




近期在整理数据库索引相关知识点,就先针对最常用的innodb存储引擎为例,来看一下索引在该存储引擎下的存储格式和运行算法。
Mysql把数据存储和查询操作抽象成了存储引擎,不同的存储引擎对数据的存储和读取方式不同。
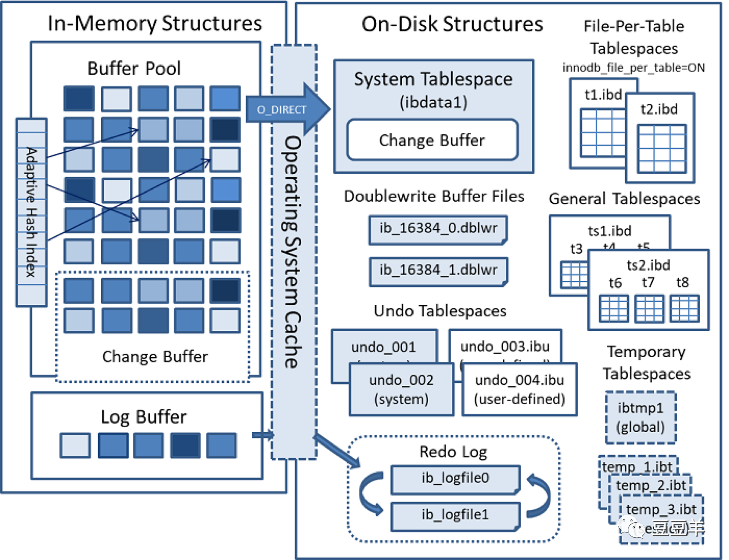
这张图显示了mysql数据库的INNODB存储引擎在内存和磁盘中的基础架构。从这里我们可以知道数据是保存在磁盘中的idb文件内的。这里需要解释一下myisam存储引擎和innodb存储引擎的磁盘存储差异。
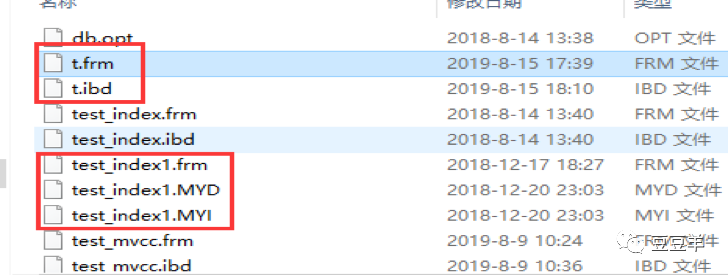
Innodb是两个文件frm保存表结构,idb保存数据内容。而myisam是三个文件,frm保存表结构,但是数据内容则由myd和myi保存。这个差异点我们在剖析了数据存储结构后以及索引的查询模式之后自然会明白,后续会讲到。
我们发现虽然数据是存在磁盘里的,但是运行其实是在内存中进行的。为了减少磁盘随机读取次数,INNODB采用页,而不是行的粒度来保存数据。也就是说数据会被分成若干页,以页为单位保存在磁盘中。那么Innodb的页大小到底是多少。
我们查阅一下mysql手册中对innodb页结构的描述。
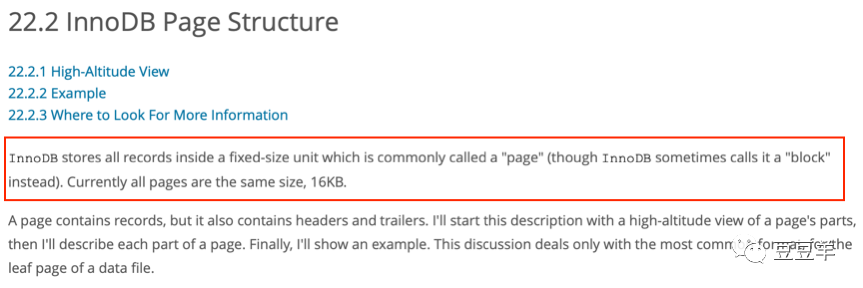
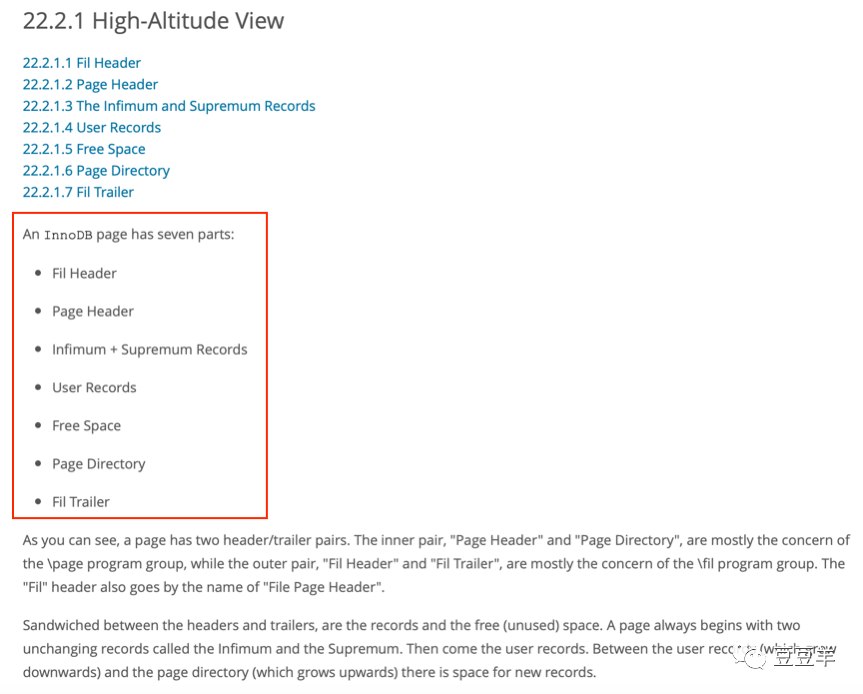
从中可以得知,当前所有页大小都是一样大的,都是16K。一个页包含七个部分,外部是两个头和尾,Fil Header和Fil Tail(文件头和尾),以及里面的Page Header和Page Directory(页头和尾) 。中间夹心的是各种记录和预留的空间,我们插入的各种数据就保存在这里。
以官网文档的demo为例:
INSERT INTO T VALUES ('PP', 'PP', 'PP');
INSERT INTO T VALUES ('Q', 'Q', 'Q');
INSERT INTO T VALUES ('R', NULL, NULL);
用hexdump -C #file命令把idb文件转成16位打开可以看到打开可以看到
Address Values in Hexadecimal | Values in ASCII |
0D4280: 00 00 2D 00 84 4F 4F 4F 4F 4F 4F 4F 4F 4F 19 17 | ..-..OOOOOOOOO.. |
0D4290: 15 13 0C 06 00 00 78 0D 02 BF 00 00 00 00 04 21 | ......x........! |
0D42A0: 00 00 00 00 09 2A 80 00 00 00 2D 00 84 50 50 50 | .....*....-..PPP |
0D42B0: 50 50 50 16 15 14 13 0C 06 00 00 80 0D 02 E1 00 | PPP............. |
0D42C0: 00 00 00 04 22 00 00 00 00 09 2B 80 00 00 00 2D | ....".....+....- |
0D42D0: 00 84 51 51 51 94 94 14 13 0C 06 00 00 88 0D 00 | ..QQQ........... |
0D42E0: 74 00 00 00 00 04 23 00 00 00 00 09 2C 80 00 00 | t.....#.....,... |
0D42F0: 00 2D 00 84 52 00 00 00 00 00 00 00 00 00 00 00 | .-..R........... |
这个是ASC码值,看不出来是个什么内容,我们重新格式化一下Hexadecimal Dump可以看到。
19 17 15 13 0C 06 Field Start Offsets /* First Row */
00 00 78 0D 02 BF Extra Bytes
00 00 00 00 04 21 System Column #1
00 00 00 00 09 2A System Column #2
80 00 00 00 2D 00 84 System Column #3
50 50 Field1 'PP'
50 50 Field2 'PP'
50 50 Field3 'PP'
16 15 14 13 0C 06 Field Start Offsets /* Second Row */
00 00 80 0D 02 E1 Extra Bytes
00 00 00 00 04 22 System Column #1
00 00 00 00 09 2B 80 System Column #2
00 00 00 2D 00 84 System Column #3
51 Field1 'Q'
51 Field2 'Q'
51 Field3 'Q'
94 94 14 13 0C 06 Field Start Offsets /* Third Row */
00 00 88 0D 00 74 Extra Bytes
00 00 00 00 04 23 System Column #1
00 00 00 00 09 2C System Column #2
80 00 00 00 2D 00 84 System Column #3
52 Field1 'R'
确实是按照1页的七个内容逐一写入的。
以上是磁盘存储结构,我们再来看看内存中的存储结构。各个数据页会组成一个双向链表,每个数据页中的记录按照主键顺序组成单向链表。没一个数据页中有一个页目录,方便按照主键查询记录。
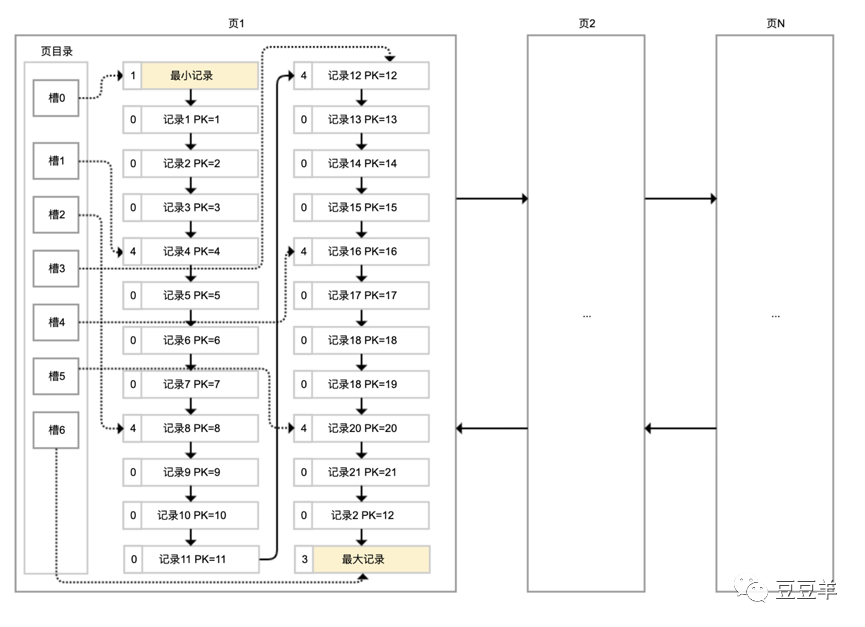
页目录中分配了槽,槽的作用是将一个页中的数据按照固定记录数进行分组。如图所示,记录中最前面的小方块中的数据,代表当前分组的条数,明显可以看到这个demo中当前一个槽是4条记录。但是这里有两个特殊槽,最大和最小的槽它们指向的是2个伪记录。有了槽以后,我们按照主键搜索页中记录的时候就可以采用二分法快速搜索,无需从最小记录开始遍历整个页中的记录链表。
例如,我们要检索主键为19的记录。
先二分得出槽中间位是(0+6)/2=3,看到其指向的记录是12<19,所以需要从#3号槽继续往后查。
再使用二分得出3号和6号槽的中间位是(3+6)/2=4.5,取整是4,4号槽对应的记录是16,16<19,那么继续往后查。
4号和6号槽的中间位是(4+6)/2=5,5号槽对应的记录是20,20>19,所以记录一定是在4号槽内。
再从4号槽指向的16号记录开始向下检索3次,定位到19号记录。
理解了innodb的存储原理后,再看看mysql索引相关的原理。
其实说到索引,刚才介绍的innodb在内存中的存储模式用到了页目录,这个页目录就是一个最简单的索引。它其实就是将所有记录进行一个一级分组来降低搜索的时间复杂度。但是,这种模式降低时间复杂度的数量级其实是非常有限的。我们看到的例子是只在一页内12条记录中进行检索。假设,如果有无数个数据页来存储数据的时候,还用这种一级分组进行二分检索定位,肯定是不够的。
为了解决这个问题,innodb引入了B+树。
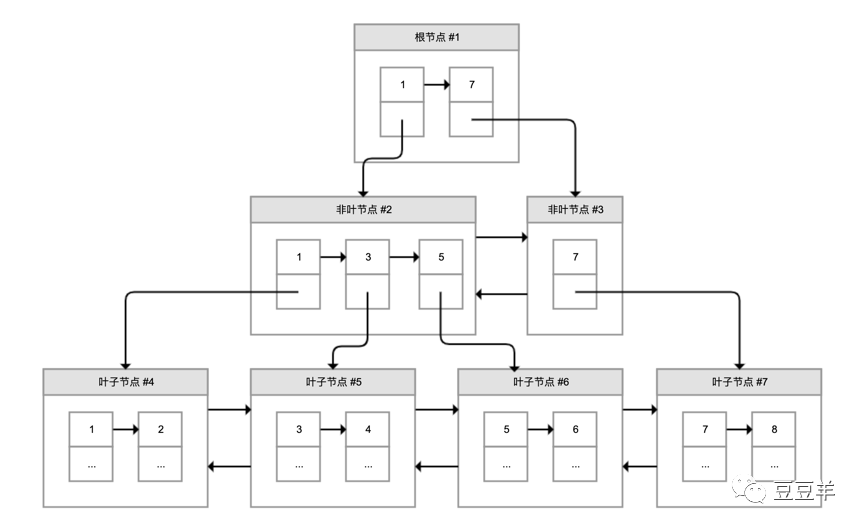
至于这个树是如何构造的,以及它和B树的区别,为何mysql要用B+树,这里不是我们这次要讨论的重点,后续我会再写一篇关于树存储数据结构的文章,可以进行重点分析。我们这里只要了解这种模式在索引的实现有几大好处。
1、最底层的叶子节点是有序的,数据也存放在这里,而且构建了一个双向链表,那么作为范围查找来说,是非常方便的。
2、利用分阶,且除了最后叶子结点保存了数据,以上每一层都是仅仅维护了目录项作为索引。那么这里有两大好处,其一,通过分层降低了搜索量;其二,增加了索引检索的稳定性,因为我数据都在最下面,无论什么要的数据定位,时间复杂度都是一样的。
以上展现的就是一个典型的聚簇索引在innodb中的实现。一般innodb会自动使用主键索引作为单表聚簇索引的实现,因为数据在物理层面上只会保存一份,所以一张表中只能有一个聚簇索引。当然,如果没有主键,就会选择第一个不包含null值的唯一列作为索引键。上图中方框里的数字就是索引键的值。
那么,问题就来了。我们都知道构建表索引不可能只用到主键索引,那非主键索引,也就是二级索引(或者叫非聚簇索引,辅助索引)是什么样子的数据结构呢。
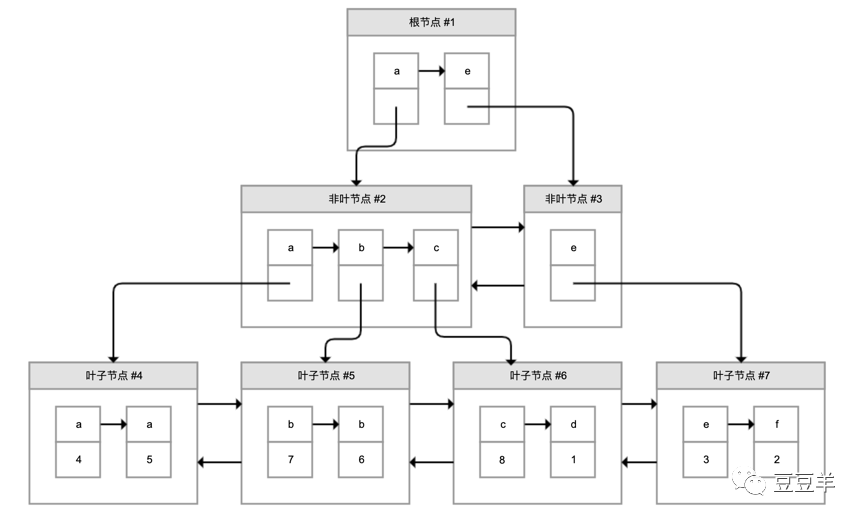
这里举的是一个针对用户名字段创建的一个二级索引,可以看到它也是一个B+树结构,但是和聚簇索引不一样的地方是,它的叶子结点保存的不是实际的数据,而是主键,拿到主键后再去聚簇索引里去检索获取数据行。这个过程就叫做回表。
比方说,我有这么一张表
CREATE TABLE `person` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`score` int(11) NOT NULL,
`create_time` timestamp NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
ID | Name | Score | Create_time |
1 | d | 80 | 2021/3/27 10:00:00 |
2 | f | 90 | 2021/3/27 10:00:00 |
3 | e | 90 | 2021/3/27 10:00:00 |
4 | a | 90 | 2021/3/27 10:00:00 |
5 | a | 100 | 2021/3/27 10:00:00 |
6 | b | 80 | 2021/3/27 10:00:00 |
7 | b | 70 | 2021/3/27 10:00:00 |
8 | c | 60 | 2021/3/27 10:00:00 |
我们构建了两个索引,一个主键索引对应列是ID,一个二级索引对应列是name。
我们要查name是b 的全部信息,select * from person where b=’name’;
索引检索的步骤就是先查二级索引,查根节点#1,因为a<b<e,所以查a的应用非叶节点#2,#2中从左向右查到b节点,再找其叶子结点#5,从左到右找出主键7和主键6的name都是b。
然后进行回表操作,在聚簇索引中开始进行检索。
先查主键7,查根节点#1,因为1<7,7=7,到非叶节点#3中找到其叶子结点#7,再从左到右找到第一个就是主键7,直接返回它的行记录。
ID | Name | Score | Create_time |
7 | b | 70 | 2021/3/27 10:00:00 |
再查主键6,查根节点#1,因为1<6=7,到非叶节点#2中,因为1<3<5<6,所以继续往下查5节点对应的叶子结点#6,从左到右找出第二个结点的主键为6,则返回其行记录。
ID | Name | Score | Create_time |
6 | b | 80 | 2021/3/27 10:00:00 |
最后组合两次查到的行记录返回。
ID | Name | Score | Create_time |
7 | b | 70 | 2021/3/27 10:00:00 |
6 | b | 80 | 2021/3/27 10:00:00 |
这是一个最简单的二级索引的应用,那么如果是联合索引,它会是以什么样的方式进行存储呢?其实很简单,如果是联合索引,则会按照构建顺序在节点中顺序记录每个列的记录。
举个列子,我们构建一个name+score的联合索引
CREATE INDEX `name_score` ON person(`name`,`score`)USING BTREE;
它的数据结构会如下图所示:
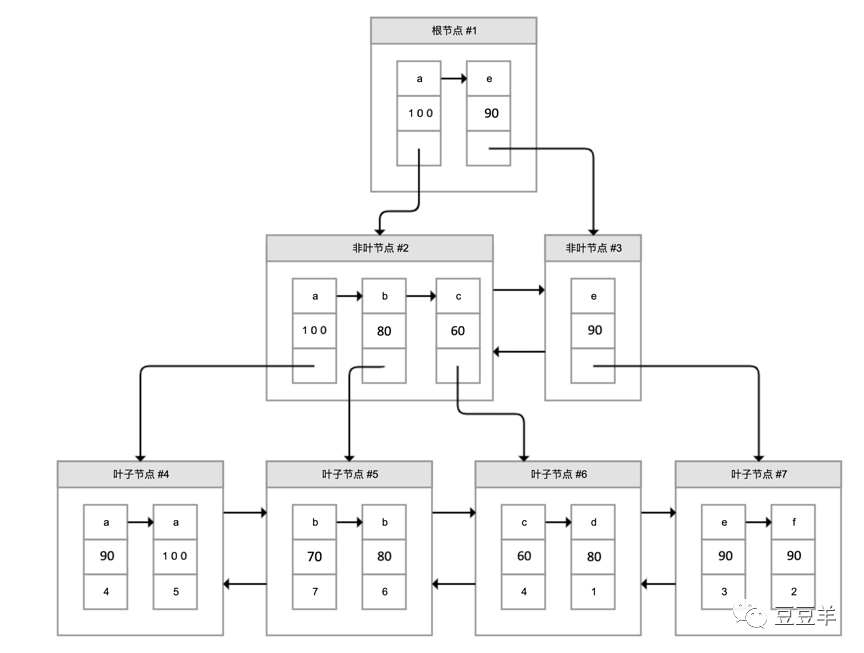
可以看到叶子结点中每一条记录的第一个方块是索引列name,第二个方块是索引列score,这个顺序就是按照你申明索引时候的顺序来的,这个很重要。因为它是按照从上到下的顺序,先按name 排序, 如果name相同,则按照score进行排序构建。所以,如果我们想使用联合索引中尽可能多的列,查询条件中的各个列必须是从联合索引中最左边的列开始,如果我们仅仅按照第二列搜索,肯定无法走索引。
另外,由于二级索引会把索引列的数据已经在树中记录了,因此,如果我们需要查询的仅仅是索引列索引或者是联合索引能覆盖的数据,那么查询索引本身就已经覆盖了需要的数据,不再需要回表了。因此,这种情况也叫做索引覆盖。
最后,我们再回过头来看一下myisam的数据结构,刚才提到了myisam有三个文件,frm,myd和myi,frm我们知道是数据表结构的存储,那么myd和myi是啥呢。
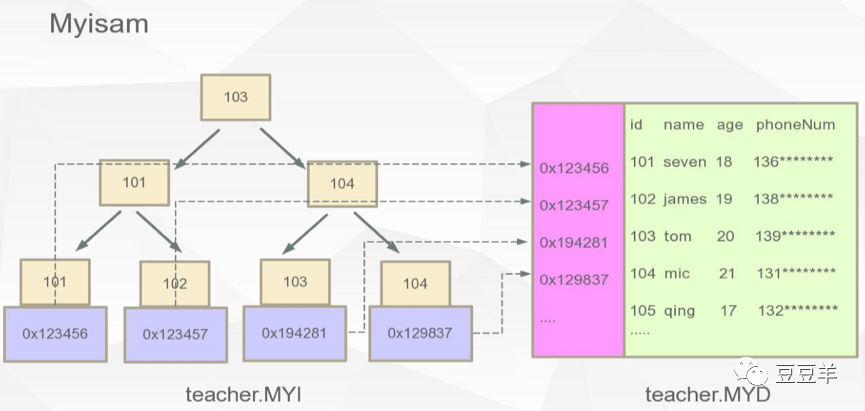
从这个图中,我们能清晰的看到myisam和innodb在数据存储上最大的差异就在于, 它的B+树叶子结点上存储的是地址,而不像innodb直接存的数据,所以,它分了两个文件,一个存地址,一个存数据。
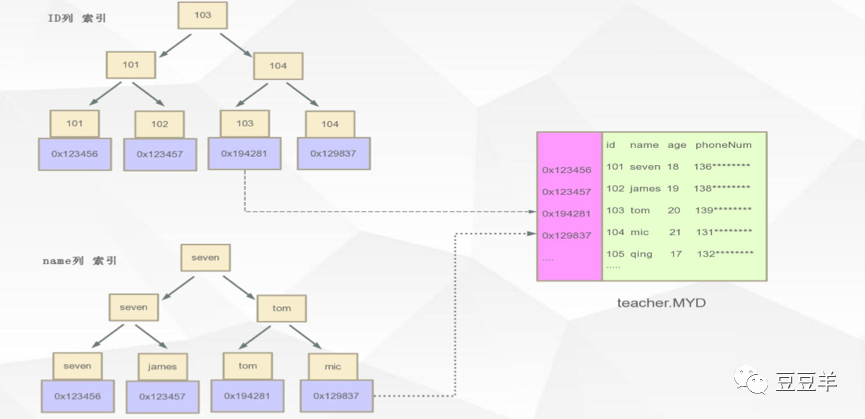
它的非聚簇索引也是用的同样的结构。
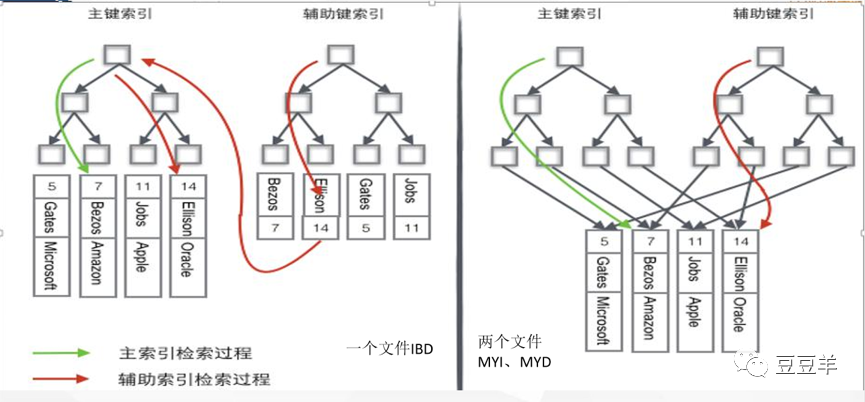
这就是为什么myisam是三个文件而innodb是两个文件的原因。
我查了一下官网对存储引擎的区别解释。
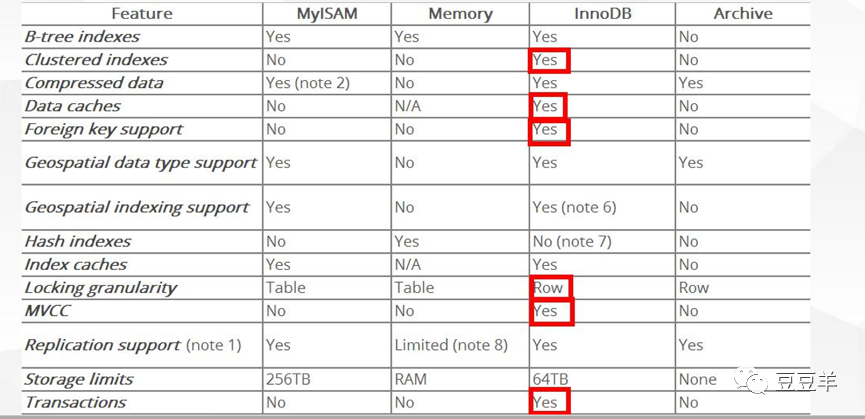
个人认为,从性能上来说,myisam还是不能同innodb相比,毕竟没有数据缓存,同时还要从两个文件中进行数据读取,本身就增加了IO的开销。在数据量小的情况下,不会有太大差异,但是在数据量大的情况下,差异就会显现出来了。MYISAM是借助操作系统来缓存数据的,操作系统是不知道优化数据库访问的,而InnoDB是用自己的缓存功能来加速访问的,要知道优化越靠近应用/数据侧才越有效果。
本来想再讲一讲索引的优化,根据今天将的数据库存储原理和机制,但是觉得一次码太多,还是不够友好。我会在下一期把索引优化的内容作为一个单独的主题再加上来。
