




最近在看过往的项目优化案例,看到了一个挺有意思的用例。正好里面也用到了redis的bitmap数据结构做存储,所以,今天也试着整理一下该项技术在生产中的实际应用过程。该项目改造的起因是缘起与19年双十一的时候暴露出系统提供SKU商详的黄金流程接口性能问题,流量大时性能不稳定且容易超时。场景是商详页的sku需要依据客户的车型进行适配。由于汽车行业的特殊性,一个SKU有可能有多个车型可以适配。比方说,一个米其林轮胎195/65R15 91V 韧悦 ENERGY XM2,有可能在高尔夫,宝来,卡罗拉,铃木天语,福克斯上都能适配。而车型又是分成了四级类目:品牌,厂商,车系,车型。那么按照这个思路,我们梳理出的数据结构如下图所示: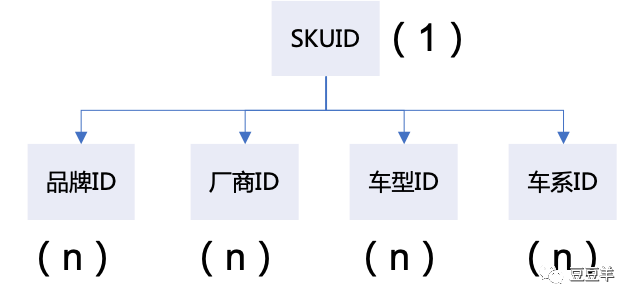
在老的方案中,我们用ES存储了以上SKU与车型的关系。那么这里有两个问题。首先,客户的车型,一定是固定的某一个品牌,厂商,车系,以及车型。这里带来一个痛苦的点,我们需要重复的拿当前确定的一个SKUID捞出所有品牌ID,厂商ID,车型ID和车系ID与客户的车型进行匹配。这是一个不断match的过程,比如某一个SKUID对应的四个类目的数值是20,30,40,20。那么极端情况下,系统需要计算20304020=480000次才能确定客户车型是否适配该SKU。其次,因为ES存储的就是一个JSON结构的文档。那么车型适配库务必不能频繁的进行更新,因为它每一次的变更,无论是只更新一个属性还是所有属性都进行更新,其实本质上是创建一个新的文档,然后把老的文档标记成删除。可想而知,会带来多大的维护成本,以及对存储的开销。
那么为了解决这两个问题,需要做一些改造。首先,需要拉平零碎的车型数据,把四级车型压缩一下,按照定长组合四级类目。压缩车型ID=品牌ID+厂商ID+车系ID+车型ID。例如压缩车型ID"101001001003"=品牌ID:101,厂商ID:001,车系ID:001,车型ID:003。这么做的好处是能保证快速定位唯一车型了,坏处是使得数据的冗余性加大了。但我们要看场景,这里的查询场景本身就不能按照传统的通过SKU找车型来完成。我们可以换一个思路,利用确定的客户车型来关联SKU会不会更合适。
基于这个思路,我们改造为使用redis进行数据的存储。将压缩车型作为key,那么sku作为value应该以什么结构进行存储会比较合适呢。其实无论是用String,Hash,List,Set还是SortedSet,都解决不了两个问题,第一,面对单个key如果有海量数据的检索匹配问题,毕竟这个检索还是在高级语言中实现,性能快不起来。第二,像SKU这种数据,量级是非常大的,如果用这种结构化的方式来存储,存储的使用是个大问题。为了针对性的解决这些问题,需要采用新的存储模式。我们使用了bitmap,其实bitmap也是基于redis的字符串类型的。但是通过位图,能够最大化的利用存储空间,把value值转化成二进制,那么在总长度一定的情况下,我们只需要在指定位点存1个bit就能标记是否包含该值。我们可以想象一下,一个字符串类型最大是512M。因为 8bit=1byte;1024byte=1kb;1024kb=1M。那么把512M换算成bit就能知道一个key最多能存多长的数据。810241024512=43亿。所以bitmap能支持的最大设置长度可以到43亿,而我们车品的sku有690W,且是自增的。绝对保证单个skuID的大小不会超出空间。
那我们看一下数据是如何存储的。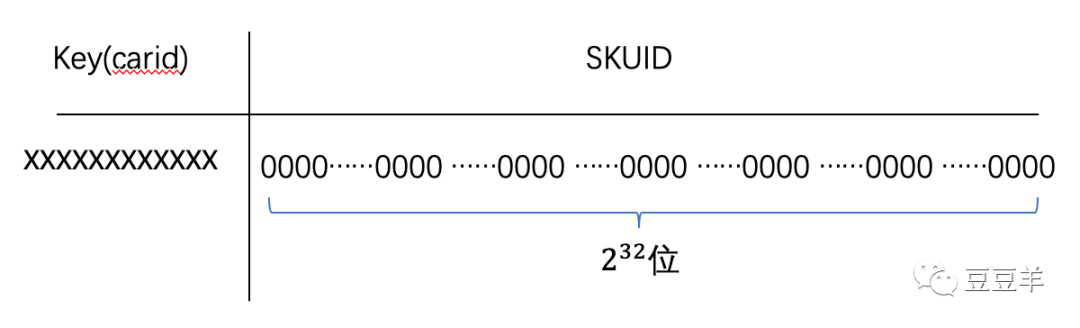
这是一个初始的数据容器,我们现在开始存一个车型ID: 101001001003,映射一个它关联的SKUID,假设这个ID已经自增到了最大值6900000。

那么6900000在redis里是以什么格式存储的呢?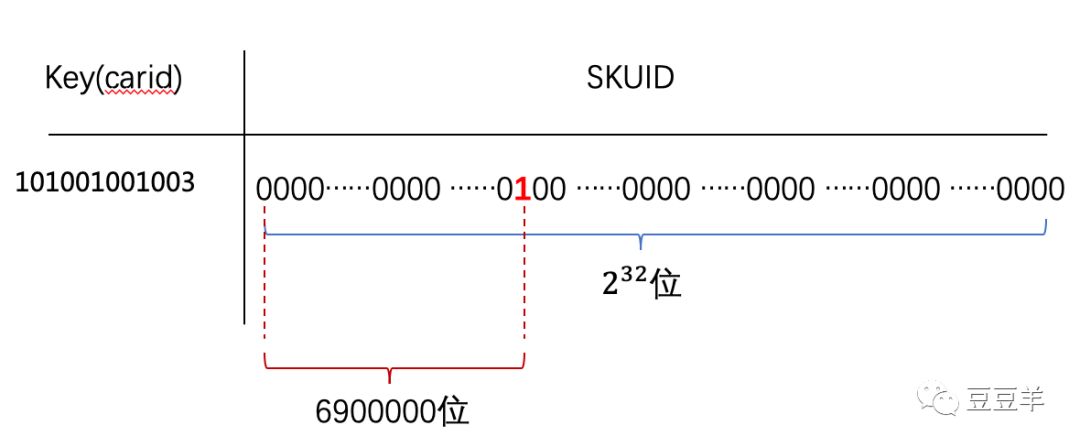
可以看到第690万位上的0变成了1,这就表示了key:101001001003在偏移位6900000上的值设为了真。我们查的时候只需要把key车型ID和value SKUID作为参数传进去,查看一下他们是否是匹配的,如果匹配,那就会传1回来,如果不匹配,则会传0。
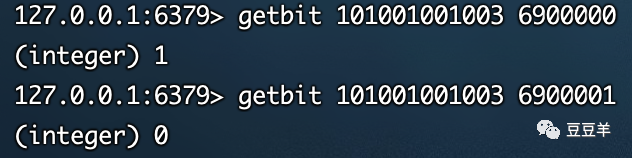
这种方式,通过占位符,仅需一个字节就能匹配key和value的关系,极大的节省了内存的占用,且能满足键值1:n模式下的快速定位。但它有一个局限性,就是必须要保证value是一个数值(它只是一个指针的偏移量),且这个数值不能超过43亿,否则会产生偏移越界的情况。依据以上这个用例,我们存储700万的SKUID,仅用到7000000/8/1024/=854kb。连1M都不到。
最后,考虑到key作为车型数据量有6万多,因此我们最好要做一下分片存储。那么既然要分片,就要设计一下分片的策略。我们可以做一张映射表,由0开始做自增,映射现有的车型ID。然后依据一定的大小,进行平均分片。
最终存储到redis中的数据结构,如下所示。
这样就能做到分布式存储,那么就能利用多线程进行分布式查询,同时也能保障快速车型和SKU的快速适配查询了。最终的优化结果是接口性能提升了5倍,接口负载量提升20倍以上,日常极少报警,完美挺过了20年的618。
该监控结果如果不知道怎么看,请看我上一篇介绍性能指标的文章。文章转载自豆豆羊,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
