




前段时间,有同学问我,我在黄金眼系统上查看到我们京东汽车双十一期间商详PV有5,6百万,那么我们服务调用TPS峰值到底是多少?
针对这个问题,我想到了一系列性能指标,我们团队的同学们经常会问到这方面的问题,所以我今天就正好统一梳理一下。
我们所在的业务线是京东零售汽车品类业务线,作为一个电商平台,除了商搜以外,调用量最大的页面自然是自营和POP的服务市场商详页,其中核心接口是服务数量和服务费查询接口。因为监控平台获取调用频度是按照5分钟来计算的,因此可以查到双十一期间调用频次为5分钟5,917,443次。由此,我们进行一下计算。
场景:每分钟调用1,183,488次
TPS:每秒处理的消息数,指系统在单位时间内处理请求的数量。 |
TPS=1,183,488/60=19,724笔/秒
以上算出的这个TPS值还不能算是峰值,只能说是平均值。那么峰值该如何计算。
TPS峰值:符合帕累托法则,即80%的调用量发生在20%的时间内。 |
TPS峰值=1,183,488*80%/(60*20%)=946790/12=78899笔/秒=4*TPS平均
所以TPS峰值基本上等于4倍的TPS平均值。
那么只看TPS也只能看到接口的调用情况,并不能反映网站的真实流量,对于我们技术来说,我们更关心这些大规模的调用,到底是多少用户达成的。因此,又引出了另一个指标,并发量。
并发量:系统可以同时承载的正常使用系统功能的用户的数量。 |
例如:某一个地铁站进展有10个闸机,可以允许10个人同时进站,那么并发量即为10。还是以JD汽车服务市场业务为例,双11当天,商详页UV为770万,在接口没有限流措施和用户一个时间点集中访问等极端情况下,可以认为并发量能和UV持平,当然,这个基本上不大可能。
除了调用量和并发量,当然引出了另一个问题,系统的响应时间。
响应时间:系统对请求作出响应的时间。是指执行一个请求从开始到最后收到响应数据所花费的总体时间。 |
例如:向服务器A发送请求时间为T1,服务器A处理请求时间(思考时间)为T2,服务器返回信息的时间为T3,响应时间T=T1+T2+T3。
对于一个游戏软件来说,响应时间小于100毫秒应该是不错的,响应时间在1秒左右可能属于勉强可以接受,如果响应时间达到3秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说都是可以接受的。
那么,这个响应时间还只是一次请求的时间,但是对于我们研发同学需要关注的其实是在某一个时间段内系统的稳定性和抗压能力。那么该如何来监控产品的性能呢。
这里引出了另一块我们需要关注的指标点TP50、TP90、TP99等。
TP=Top Percentile , Top百分位数,是一个统计学里的术语,与平均数、中位数都是一类。 TP50就是满足百分之五十的网络请求所需要的最低耗时。 TP90就是满足百分之九十的网络请求所需要的最低耗时。 TP99就是满足百分之九十九的网络请求所需要的最低耗时。 |
举个例子:有四次请求耗时分别为:
10ms,1000ms,100ms,2ms
那么我们可以这样计算TP99,4次请求中,99%的请求数为4*0.99,进位取整也就是4次,满足这全部4次请求的最低耗时为1000ms,所以TP99就是1000ms.
TP指标:指在一个时间段内,统计该方法每次调用所消耗的时间,并将这些时间按从小到大的顺序进行排序,并取出结果为:总次数*指标数=对应TP指标的序号,再根据序号取出对应排序好的时间,即为TP指标。
文章开始引用中的例子中样本较少,不好理解。举一个样本较多的例子,方便理解:
假设一分钟内接口被调用100次,100次的调用耗时分别是1、20、39…2、10秒。
我们对耗时进行从小到大排序,形成容量为100的数组A=[1s、2s、3s…99s、100s]
TP50的计算方式:100*50%=50,所以TP50指标=A[50]=50s
TP99的计算方式:100*99%=99,所以TP99指标=A[99]=99s
TP999的计算方式:100*99.9%,99.9进位取整为100,所以TP999指标=A[100]=100s
综上所述,可以得出结论
如果我们的性能指标要求是TP50=12ms,那么就意味着需要保证在某一时间段内该方法所调用的消耗时间至少有50%的值要小于12ms。
同理,如果要求TP99=92ms,那么就要求方法在一段时间内调用的消费时间至少有99%的值要小于92ms。
以我们日常使用的监控平台的数据为例。
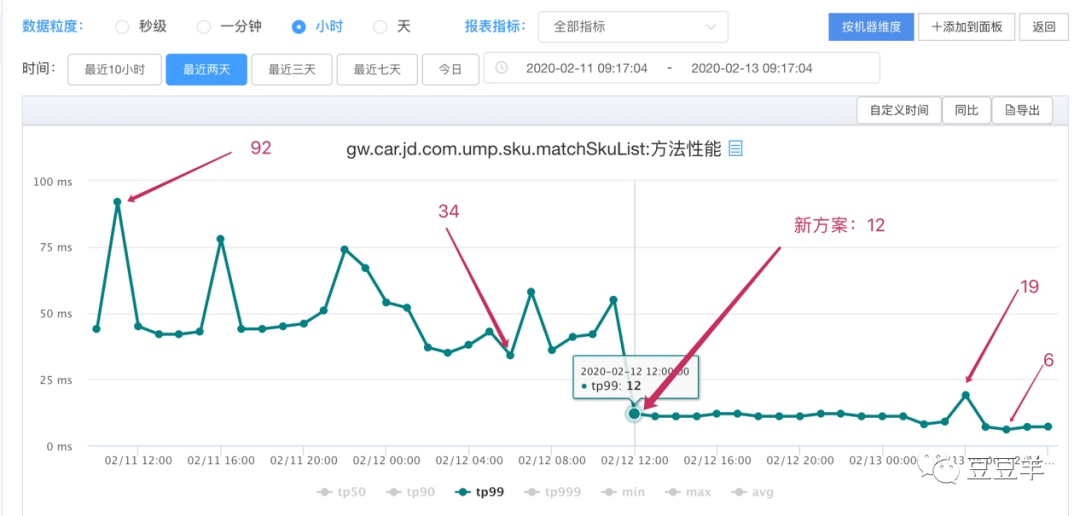
这里可以看到2月11日使用旧方案性能指标体现出来TP99最高到92,最低到34,12日上线后,使用新方案后tp99最高到19,最小只有6。我们不关心这个技术方案的改造原理,这篇文章这个不是重点,这篇文章的重点在于如何解读这些性能指标。 我们解读最终的结果是在性能改造之前该接口一个小时之内有99%的响应时间在34ms~92ms之间,改造之后能够优化到一个小时之内有99%的响应时间在6ms~19ms之间。改造的成绩还是很显著的,性能整体提升了5倍。
最后,我们再来看一下咱们日常压测接口的时候一般会关注到哪些性能瓶颈。
失败事务数增多
TP99大于500ms
平均响应时间大于200ms
并发用户数增多,平均TPS趋向平稳
TPS曲线不平稳,抖动严重
接口调用次数(UMP)与预期不符
应用服务器CPU利用率大于等于80%
应用服务器内存利用率大于等于80%
应用服务器出现错误日志
压力机CPU利用率大于等于80%
压力机内存利用率大于等于80%
(有)数据库服务器CPU利用率大于等于80%
(有)数据库服务器内存利用率大于等于80%
(有)Jimdb中CPU利用率大于等于80%
(有)Jimdb中内存利用率大于等于80%
(有)Jimdb中当前连接数超过预期
(有)ES的CPU利用率大于等于80%
(有)ES的内存利用率大于等于80%
(有)Redis的CPU利用率大于等于80%
(有)Redis的内存利用率大于等于80%
相同设置,不同时段压测结果不一致
相同设置,压测结果越来越差
应用操作异常:响应超时\页面异常\报错
下游依赖接口报警
