




昨天我创建了一个样本表 t6
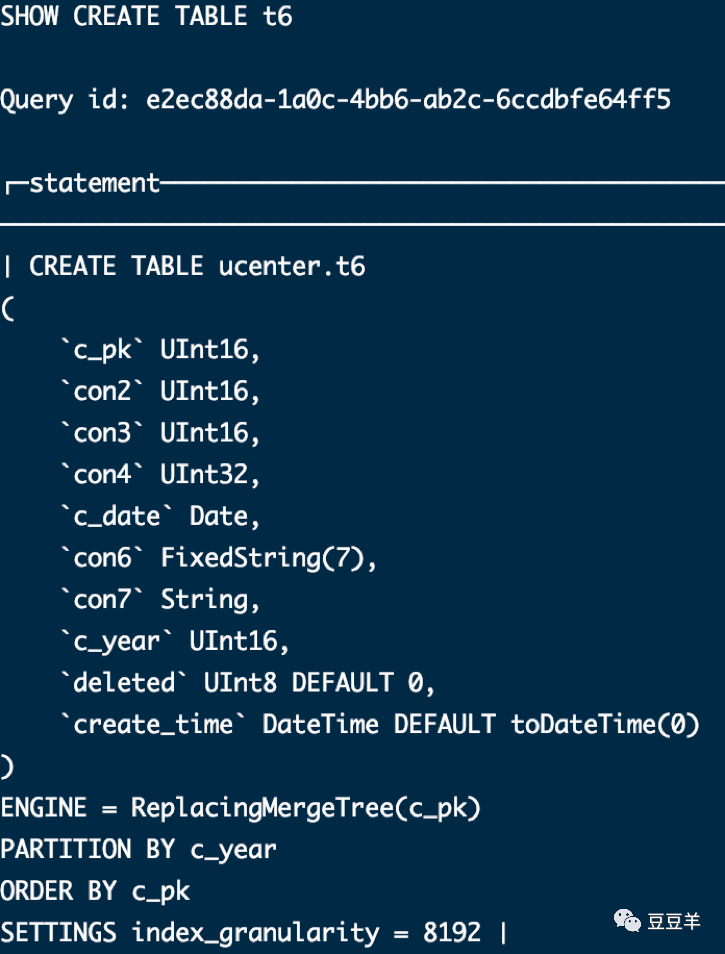
create TABLE t6
(
c_pk UInt16,
con2 UInt16,
con3 UInt16,
con4 UInt32,
c_date Date,
con6 FixedString(7),
con7 String,
c_year UInt16
) ENGINE = ReplacingMergeTree(c_pk)
PARTITION BY c_year
ORDER BY c_pk
我设定使用的引擎是合并树家族的替代合并树。之所以使用这个引擎,主要就是为了数据的去重。我定义了一个年字段作为它的分区字段,使用一个特定字段c_pk作为排序字段。在 click house中在不指定primary key的情况下,默认会将排序字段作为表的主键。
替代合并树也是属于合并树的其中一种。这种引擎的特点是适用于高负载任务。主要应用场景是被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断的修改已存储的数据,这种策略会高效很多。因此针对一些需要新增海量数据的场景,则非常适用。针对一些需要不停进行变更的,实时性要求高的数据应用场景则不合适。因此,类似于数据仓库,特别是离线数仓等OLAP类的场景非常有用。对于在线交易系统,业务系统等OLTP类的场景则非常不合适。
应用该引擎,由于数据合并会延后处理,例如以上用例中,合并规则是依据排序字段c_pk来进行合并,取该字段的最新一条数据。但由于是延后,所以在合并之前,在系统中,还是会依据批次插入的内容,进行分批存储。
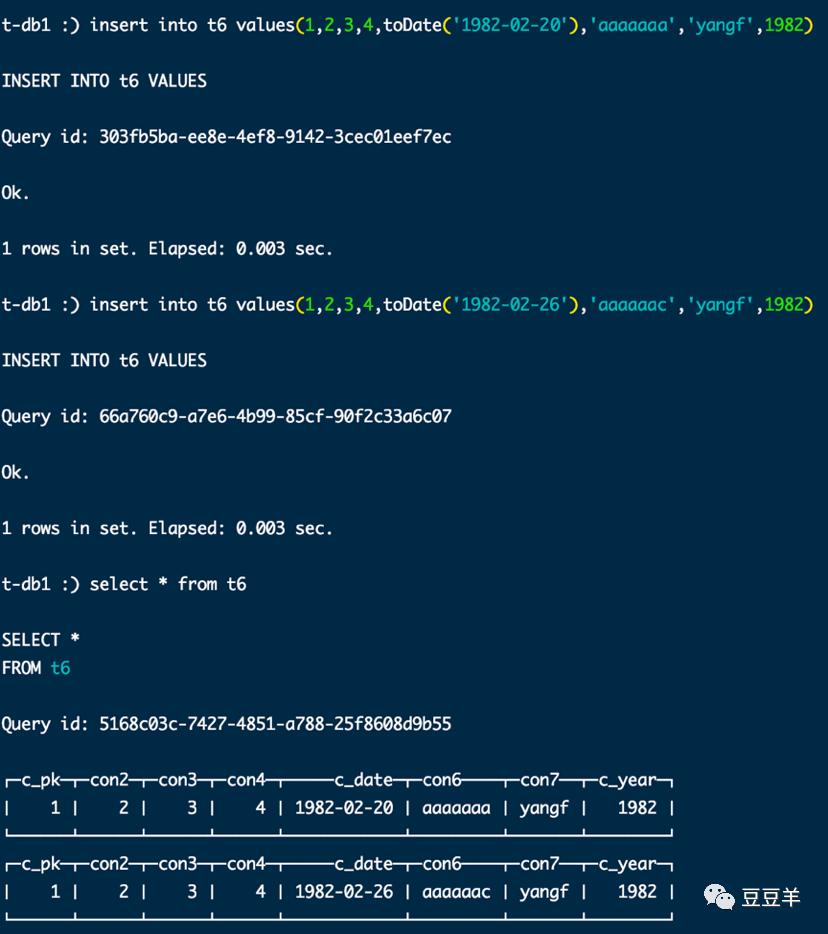
可以看到以上场景中,我先后往t6中插入了两条数据,c_pk值都是1,但是用select进行查询,会把每次插入的数据都捞取出来,提取出两个数据集。这不是我们想要的。为了解决这个问题,通常有三种解决方案。一种是每次在写入数据后,立刻通过 optimize table partition part final,立即优化表分区,强制触发分区的合并动作。
合并之前:

合并之后

这里的分区名称 ,1982是前面表存储引擎定义的partition的映射字段c_year。第一个1表示是数据块的最小编号,第二个1表示是数据块的最大编号,后面的0是块级别,即在由块组成的合并树中,该块在树中的深度。可以看到合并前1982有两个分区,每个分区都有一个数据,分别是编号为1和编号为2的数据,合并后,深度由0变成了1,编号由1到2。
,1982是前面表存储引擎定义的partition的映射字段c_year。第一个1表示是数据块的最小编号,第二个1表示是数据块的最大编号,后面的0是块级别,即在由块组成的合并树中,该块在树中的深度。可以看到合并前1982有两个分区,每个分区都有一个数据,分别是编号为1和编号为2的数据,合并后,深度由0变成了1,编号由1到2。
再次用SQL查看数据
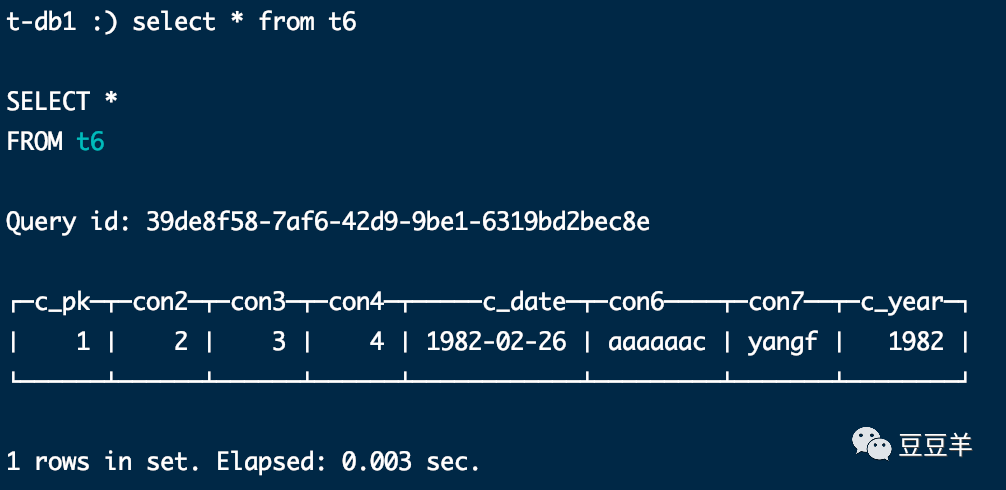
数据已经被合并。
第二种方法,通过GROUP BY查询+过滤实现
要想通过SQL查询最新的数据,我们还需要先加上两个用来控制数据有效性和版本的字段
Alter table t6 add column deleted UInt8 DEFAULT 0 after c_year
Alter table t6 add column create_time DateTime DEFAULT toDateTime(0) after deleted
这样,我们就能通过SQL条件进行过滤,取到最新的数据。
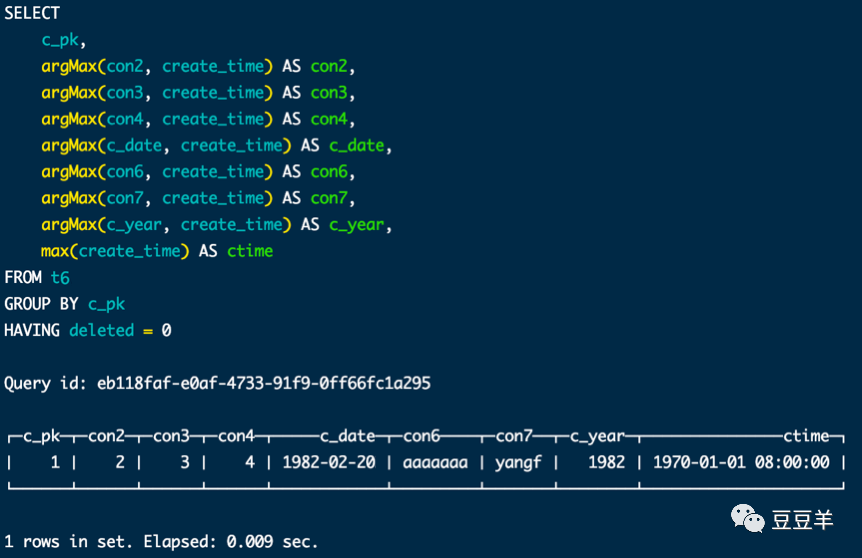
这里我没有更新create_time,取的默认值,所以取的第一条数据,这个地方需要注意,在数据仓库维护过程中,由于我们采用的是只进行insert操作,所以,每次都要维护这两个关键字段,一定要取最新的时间和状态。
第三种方式,可以从SQL语法上进行合并,如应用final修饰符,这样在查询的过程中将会执行Merge的特殊逻辑,比如数据去重,预聚合等等。但这个方法会将查询变成一个单线程的执行过程,与我们预期使用clickhouse的本质相背离,原本就是想利用单次查询走多线程来提升性能。这种方式反而和原生的mysql等关系型数据库的单次查询处理方式一致,有些本末倒置了。
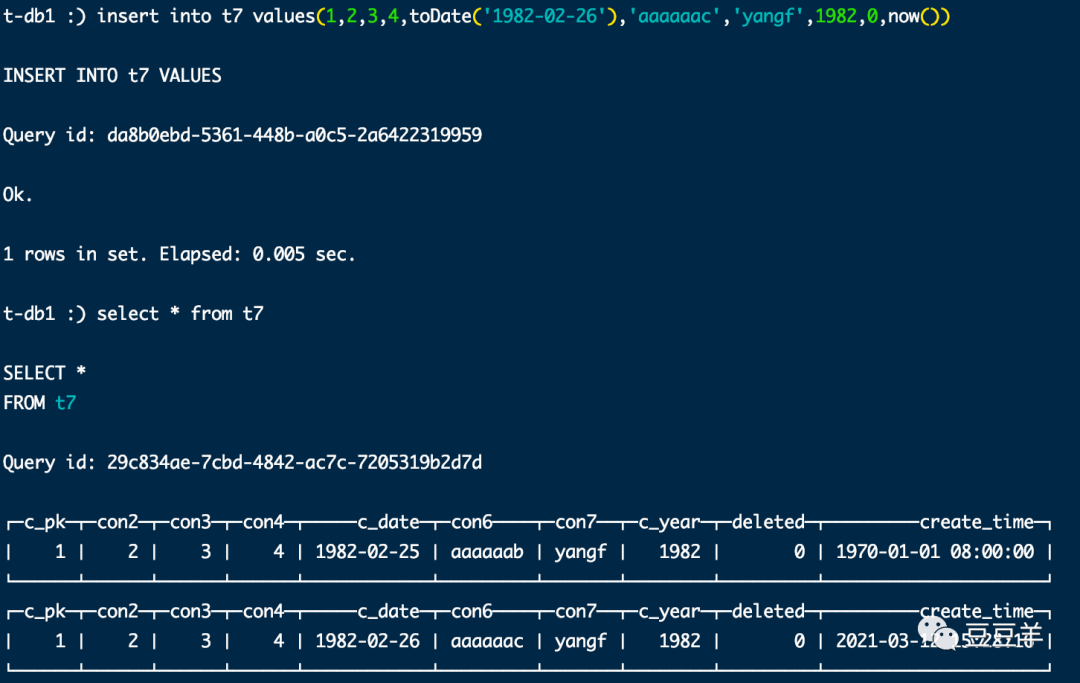
按照这个表结构,我新建了一张表t7,插入了两条数据,
insert into t7(c_pk,con2,con3,con4,c_date,con6,con7,c_year) values(1,2,3,4,toDate('1982-02-25'),'aaaaaab','yangf',1982)
insert into t7 values(1,2,3,4,toDate('1982-02-26'),'aaaaaac','yangf',1982,0,now())
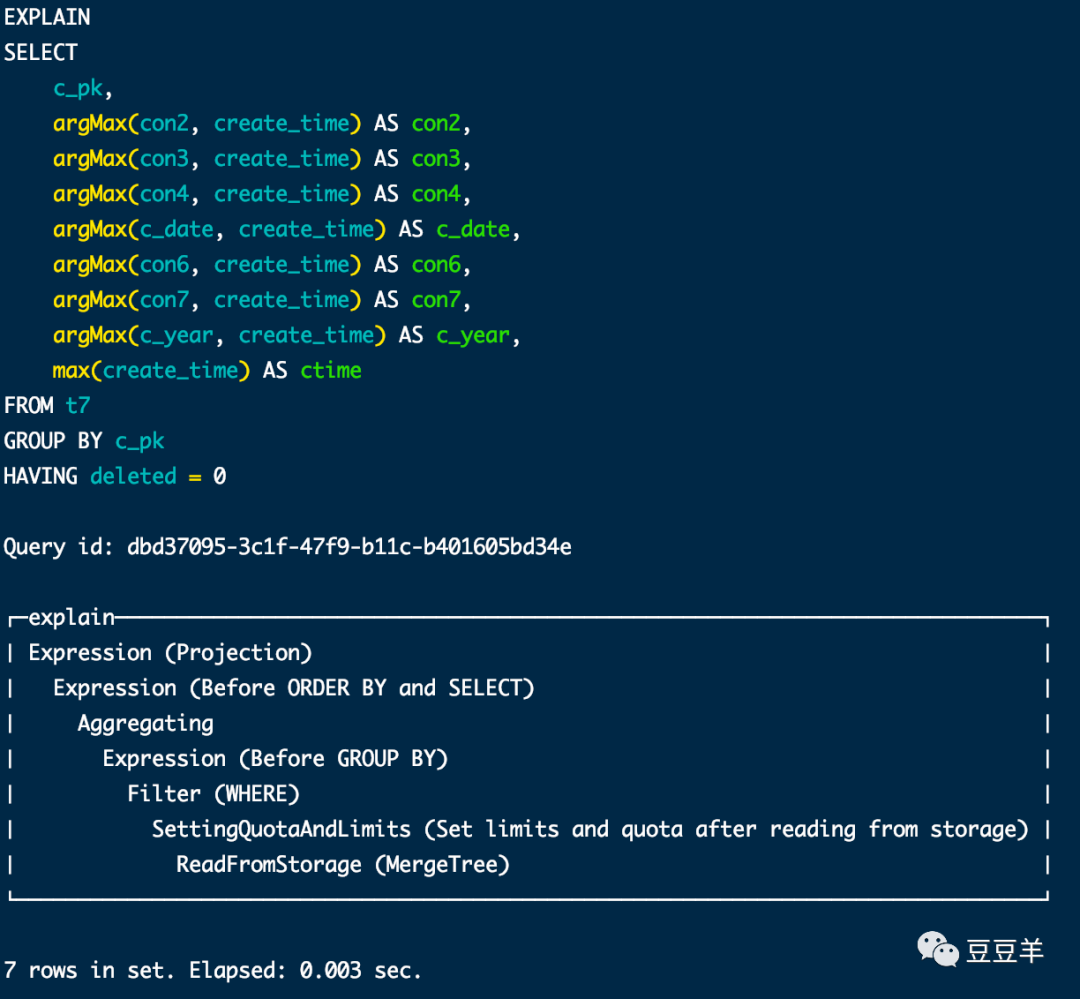
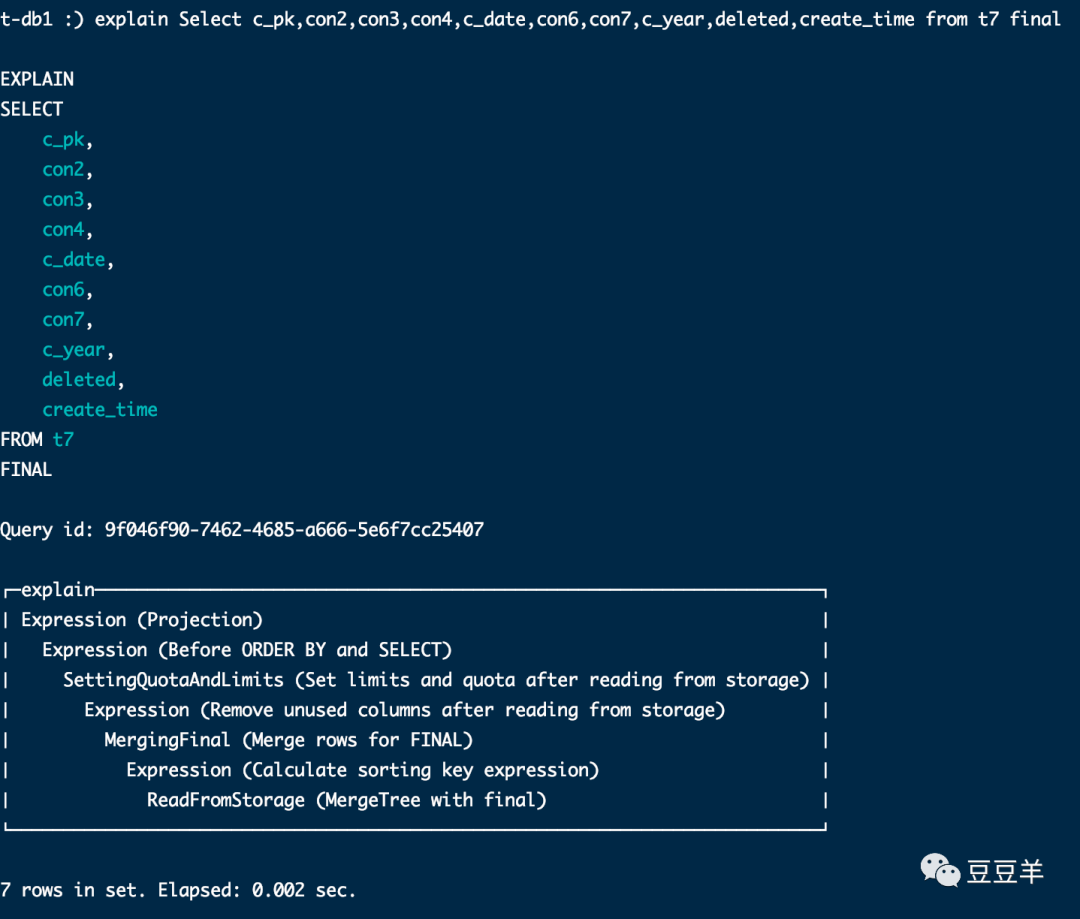
我们用代final和不代final关键词的语句来用检查语句看看内核到底有啥区别
首先是通过条件删选。
其次是通过final删选。
我们来分析一下click house的SQL执行器语法。
先看一下数据库内核结构
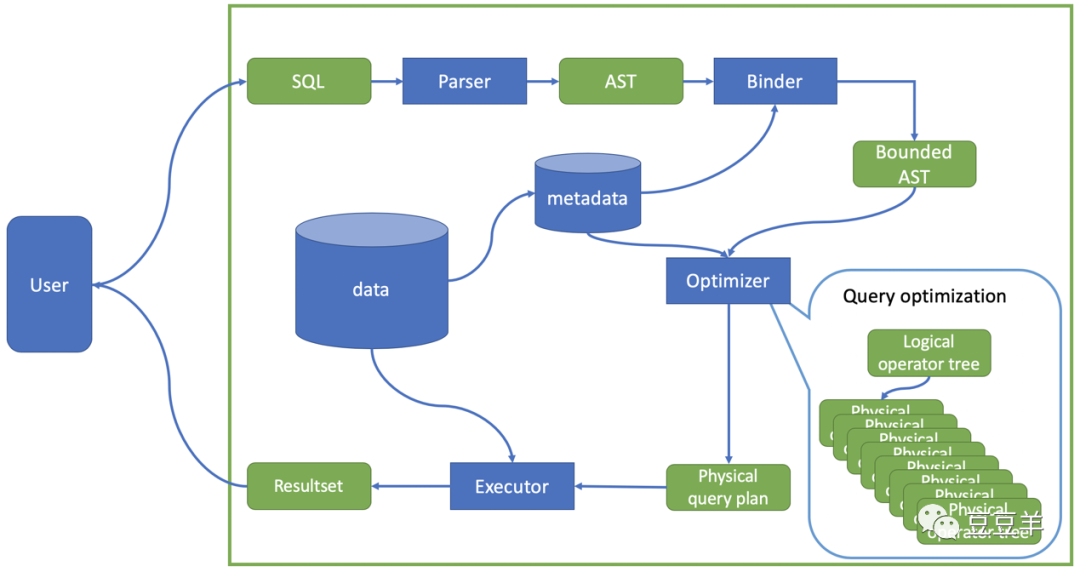
当用户输入SQL语句后,第一步是通过编译器( Parser)把语句编译成抽象语法树(Abstracted Syntax Tree)。这一步的主要过程就是确保输入语句没有SQL语法和词法错误。然后再通过绑定器(Binder)将语法树和数据库的元数据(metadata)结合,为它附上语义(semantic)。比如咱们这个语句里有select c_pk,argMax(con2…from t7,绑定器会去查询元数据确认t7表是否存在;如果存在,是否有c_pk,con2等属性存在,对于属性的后续操作是否符合规则,例如这里的argMax等。检查过程是自底向上对整棵语法树的节点依次进行,检查的同时也把相关表的元数据,属性的元数据附在语法树上,最后生成含有语义的语法树(Bound AST)。下一步就是走优化器了,优化器(Optimizer)会根据给定的语法树生成一个逻辑执行树(logical operator tree)
至于具体内核编译过程不是我们这次要研究的重点,先了解到这个顺序和逻辑即可。可以看到使用了final和不使用final的逻辑执行树是完全不一样的。一个是标准的聚合,再分组加条件过滤,在从内存读取数据后限制其输出大小。另一个则是在从内存读取数据后限制其输出大小后还进行了一系列过滤和合并以及排序计算的操作。

这些是理论上的分析,我们再把日志级别调成追踪模式看看具体执行情况。
[root@t-db1 clickhouse]# clickhouse-client -h xxx.x.x.x -u xxx --password xxx --send_logs_level=trace
先是通过普通的条件过滤方式执行
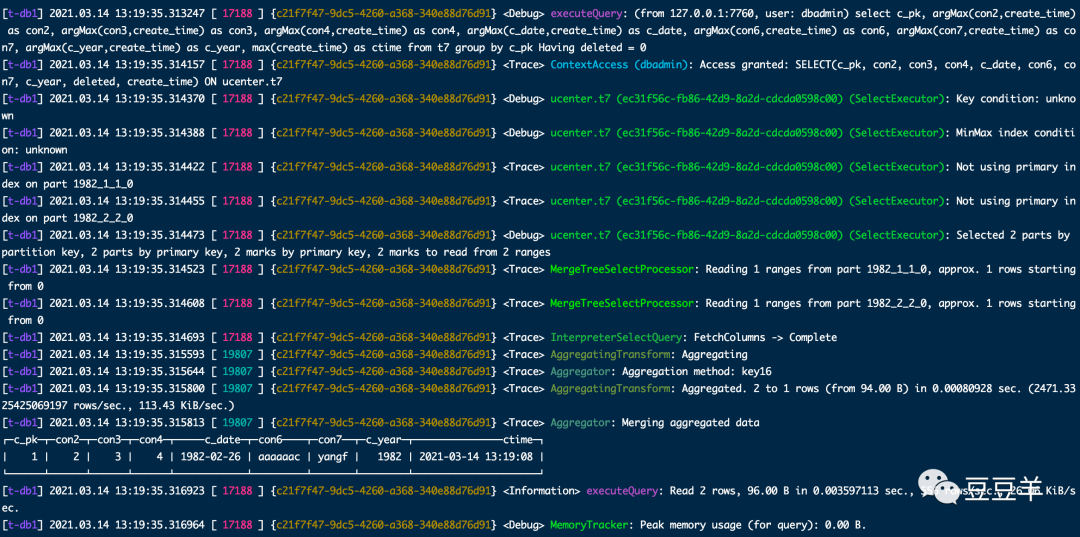
再是通过final方式执行
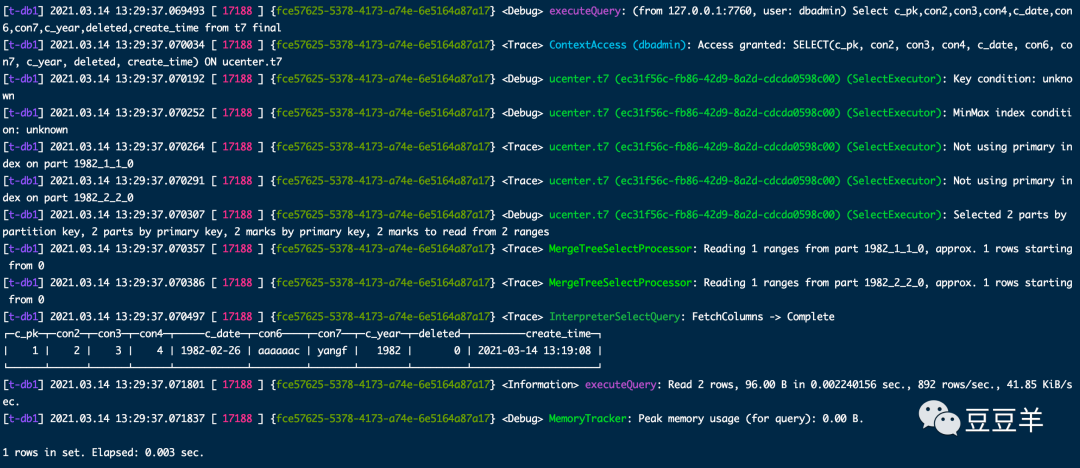
虽然结果是相同的,但是计算过程明显不一样。为了体现差异,我再插入一行数据,同时设定两个线程,使用explain pipeline看一下执行结果
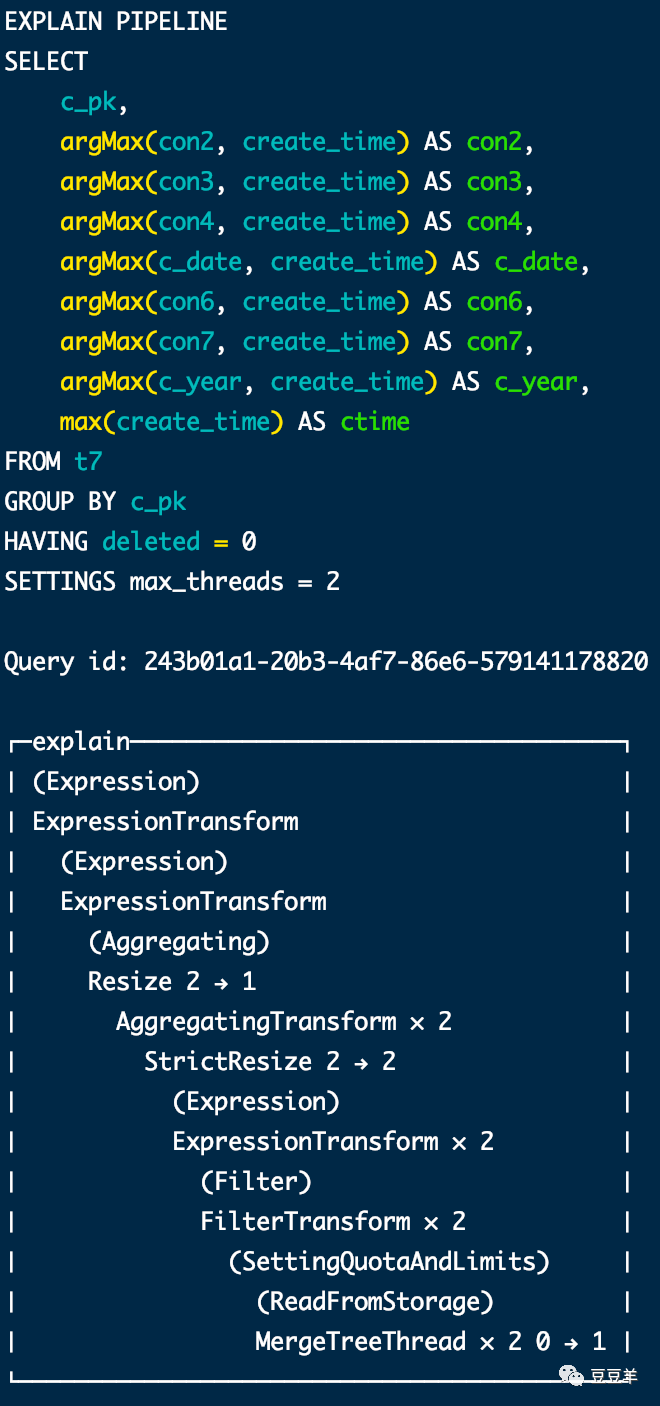
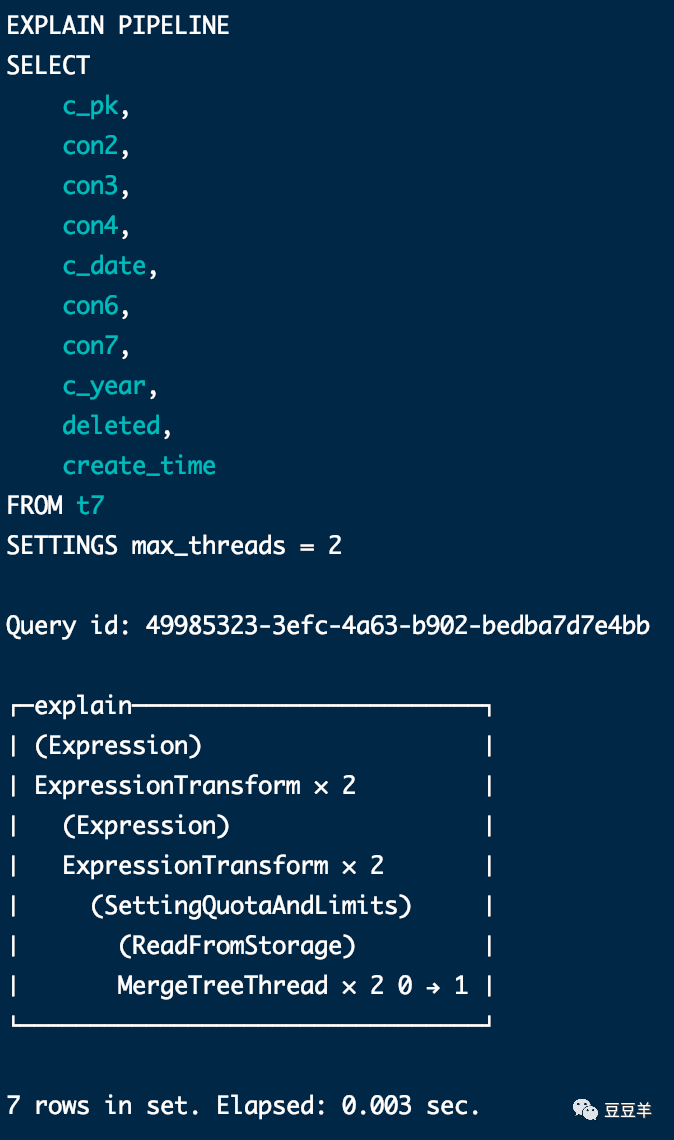
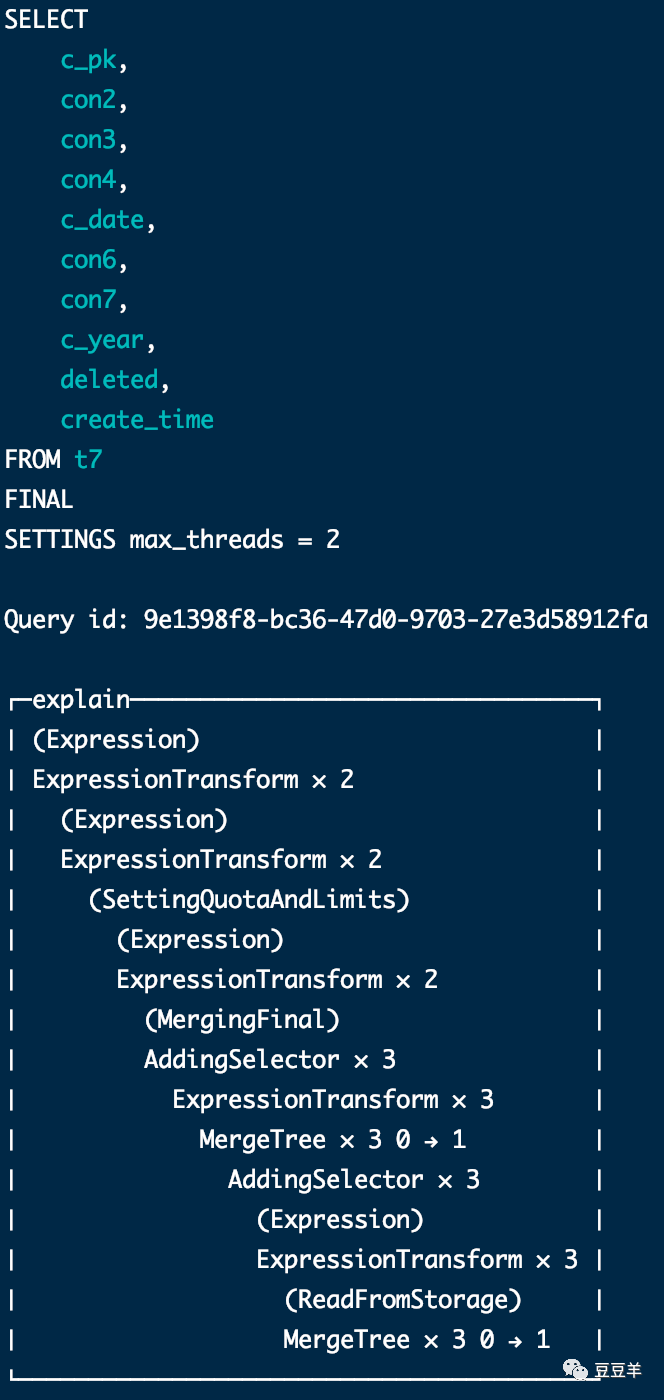
可以看到无论是否加条件,只要不用final,最后都会使用设定的2个线程并行读取part数据。用了final,发现最后读数据的时候并没有多线程读取,还是串行到三个分区中依次处理。
这里因为数据量太少,所以看的不明显。我们可以参考一下网站上给出的测试表hits_100m_obfuscated,该表有1亿行数据,105个字段。引用网上Nauu小哥对它的测试结果。他使用了两台8C,16G的虚拟机,使用20.6.3.28版本,我们看到最终的效果。
首先是不带final的查询,设定最大线程是8.
select * from hits_100m_obfuscated WHERE EventDate = '2013-07-15' limit 100 settings max_threads = 8
100 rows in set. Elapsed: 0.497 sec.
我们再使用explain pipeline看一下执行结果
explain pipeline select * from hits_100m_obfuscated WHERE EventDate = '2013-07-15' limit 100 settings max_threads = 8
(Union)Converting × 8 (Expression) ExpressionTransform × 8 (Limit) Limit 8 → 8 (Expression) ExpressionTransform × 8 (ReadFromStorage) MergeTreeThread × 8 0 → 1
很明显,这个SQL的查询会 由8个线程并行读取part查询。
然后再换FINAL
select * from hits_100m_obfuscated final WHERE EventDate = '2013-07-15' limit 100 settings max_final_threads = 8
100 rows in set. Elapsed: 0.825 sec.
explain pipeline select * from hits_100m_obfuscated final WHERE EventDate = '2013-07-15' limit 100 settings max_final_threads = 8
(Union)Converting × 8 (Expression) ExpressionTransform × 8 (Limit) Limit 8 → 8 (Expression) ExpressionTransform × 8 (Filter) FilterTransform × 8 (ReadFromStorage) ExpressionTransform × 8 ReplacingSorted × 8 6 → 1 Copy × 6 1 → 8 AddingSelector × 6 ExpressionTransform MergeTree 0 → 1 ExpressionTransform MergeTree 0 → 1 ExpressionTransform MergeTree 0 → 1 ExpressionTransform MergeTree 0 → 1 ExpressionTransform MergeTree 0 → 1 ExpressionTransform MergeTree 0 → 1
从ReplacingSorted开始已经是多线程了,有6个分区被依次加载,但是读取part部分的动作还是串行的。
总而言之:click house目前从20.5.2.7版本开始, FINAL 查询可以并行执行了,但是读取 part 部分的动作依然是串行的,而且FINAL 查询最终的性能和很多因素相关,列字段的大小、分区的数量等等都会影响到最终的查询时间, 所以为了保险起见还是使用条件过滤方式最为靠谱。
