




标签(空格分隔): Neo4j
neo4j的优势
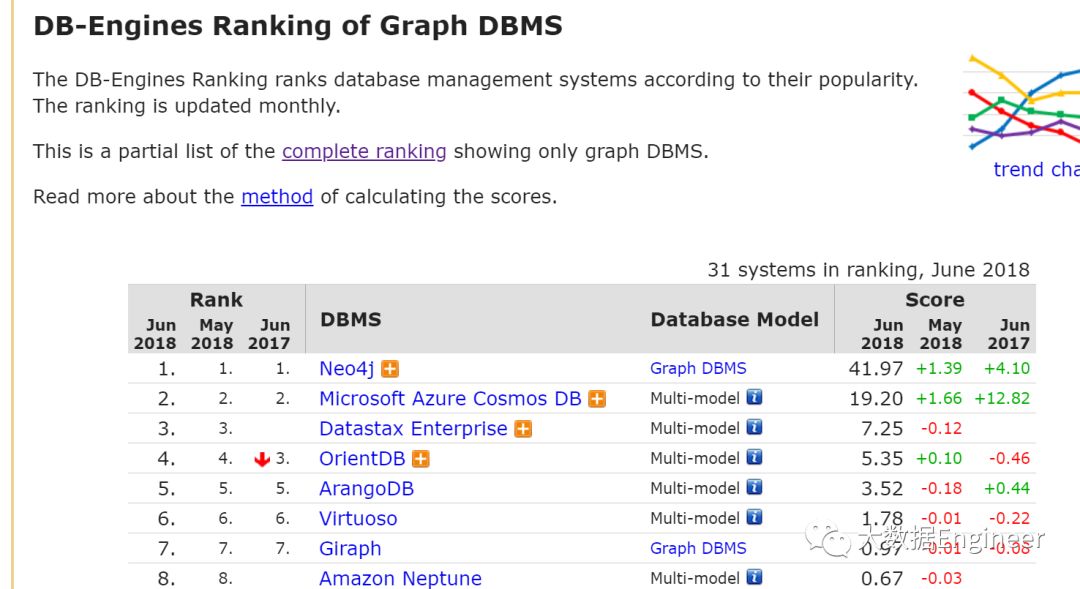
neo4j在db-engines.com排名
A native graph database
在neo4j中关系是一等公民。在关系型数据库中的join操作,其性能随着join的次数(在neo4j中相当于关系个数)呈指数级下降,而对于neo4j,随着关系个数增加,查询性能呈线性下降。
这种存储和查询实体间关系方式的不同使得neo4j拥有高达每秒每core 400w的遍历性能。同时由于大多数的查询都是在某个node相邻区域内,因此存储的数据总量不会影响查询性能。
Whiteboard friendly
Cypher,声明式式查询语言,旨在可视化的标识节点和关系的图模式。
这是一种类似于sql的功能强大且可读性强的以表达特定领域的概念或者问题的模式的查询语言。
Supports rapid development
neo4j的发展源于对高度相关的信息进行实时查询的需求,并为高度可扩展的应用程序支持快速应用程序开发。
Provides true data safety through ACID transactions
Neo4j使用事务来保证在硬件故障或系统崩溃的情况下数据安全性。
Designed for business-critical and high-performance operations
neo4j 集群支持关键业务和高性能应用,它可以存储数百亿的实体。
neo4j 可以被部署成可扩展,容错的集群。其他的特性还包括热备份,集群监控。
基本概念
图形数据库将数据存储在图中,这是最通用的数据结构,能够以可访问的方式优雅地表示任何类型的数据。
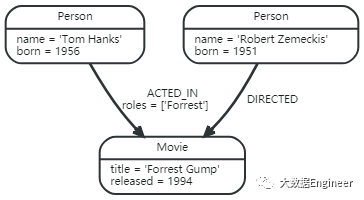
node
Neo4j中的节点是属性图模型中描述的节点,具有属性和标签。
节点通常用来表达实体。节点可以同时具有多个lebel。


Relationships
关系也是neo4j中的基本元素。关系具有具有关系lebel和属性,但是关系只能同时具有一个lebel。关系是有方向的,包含源节点和目标节点
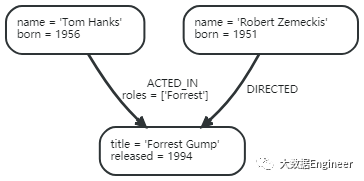
一个节点也可有自己的关系

Properties
在属性图中,节点和关系都可以有属性。
属性值的类型包含:
数值型
字符型
布尔型
任何上述值的列表
Labels
在属性图中,节点和关系都可以有标签,标签将将节点和关系分成一个个组。如果把标签看成关系数据库中的表,那么每个node相当于关系数据库中的record,但是每个record可以属于多个表。
Traversal
遍历就是在一个图中从开始节点到相关节点的导航找到诸如“我的朋友喜欢什么样我尚未听过的音乐?”的答案。遍历图意味着访问节点,根据规则追踪关系。
举个栗子
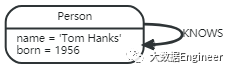
如果你想知道 Tom Hanks参演过的电影,遍历将会从 Tom Hanks节点开始跟踪所有的:ACTED_IN关系连接到下一个节点,在下面的图中最终返回Forrest Gump 节点
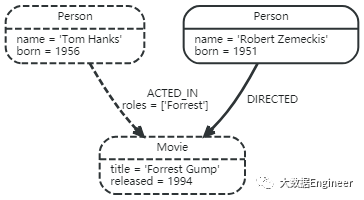
Paths
path 来自图遍历的结果,在上一个例子中,也可以将path作为返回结果,其长度为1,见图1。最短的path长度为0,也就是说他没有包含关系,只有一个节点,见图2。也有一种情况是节点与本身存在关系,那么path长度也为1
图1

图2
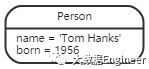
图3
Schema
neo4j是schema 可选的图数据库。这里的schema指的是索引和约束。neo4j和关系型数据库一样可以创建索引和约束。neo4j可以给节点和关系的属性创建索引。
neo4j的存储机制
免索引邻接
免索引邻接即是每个节点维护与它相关的节点的引用。这种设计的好处是一方面查询时间与图的整体规模无关,他只与和他它建有关系的节点数量成正比,另一方面是每一个节点都相当于与其相邻节点的微索引这比全局索引的代价小得多。
存储形式
在neo4j中数据是被存储在二进制文件中,节点,关系和属性倍分别存储,并且都是固定大小,通过idx字节数就可以计算数据所在位置,计算复杂度只有O(1)。具体存储见图
节点:固定大小9字节,依次是:
是否在使用,第一个关系,第一个属性。
关系:固定大小33字节,依次是:
是否在使用,关系方向,第一个节点,第二个节点,关系类型,第一个节点的上一个关系,第一个节点的下一个关系,第二个节点的上一个关系,第二个节点的下一个关系,第一个属性。
关系类型:固定大小5字节,依次是
是否在用,存储位置(动态存储指向图中块的存储文件)
属性:固定大小9字节,依次是
是否在用,属性个数,存储位置


