





前言
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获得要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
我相信,从18年到19年,在NLP领域中,出现频率最高的词就是BERT了。各种blog的介绍,各种公众号文章的分析,以及github上数不清的repo。BERT的出现,在自然语言处理方向上是划时代的。虽然后续相继出现了非常多的 RoBERTa 、ALBERT、 NEZHA等等模型,都是基于BERT上的改进,其根基都是BERT,或者严格意义上是Transformer。

今天,我们不做BERT的科普或者详解,而是站在另一个角度,透过attention
来看BERT。
BERT中的attention
attention其实很早就出现了。在BERT出现之前,attention机制就在seq2seq场景中大放异彩。当时的attention,主要是在decoding阶段对input中的信息赋予不同的权重。比如在做机器翻译的场景,针对翻译的每个字,原文中的每个字的权重都是不一样的。
而作为BERT的主要组成部分-Transformer中,提出了“Attention is all you need”的口号,全面应用了Multi-Head Self-Attention
。
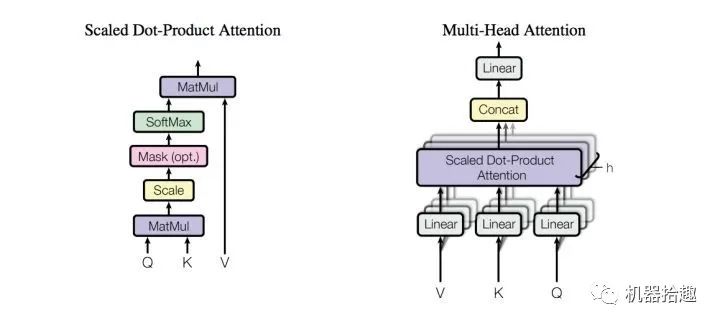
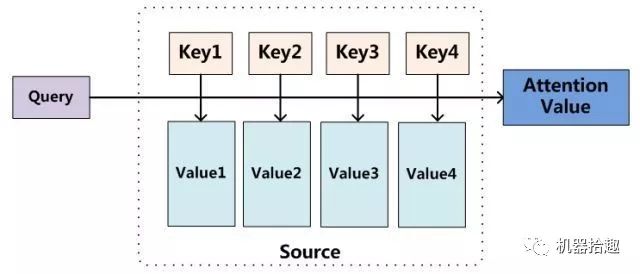
这里的关键点有两个:
Self-Attention
: 跟传统的encoder-decoder架构中的attention不一样,Transformer中的attention,主要是自注意力,也就是单个sequence里自己和自己的attention。这样就可以成功将一个sequence通过矩阵变换,抽取特征。Multi-Head Attention
: 在Transformer中,非常类似CNN中多个卷积Filter的概念,采用多头Attention(BERT中是12个head),这样不同的HEAD,可以从不同的角度来抽取特征,使得特征信息更加丰富。
接下来,让我们依照一贯的传统,根据实例来深入BERT的attention。
场景
数据集采用大众点评的用户评论情感数据,如图:
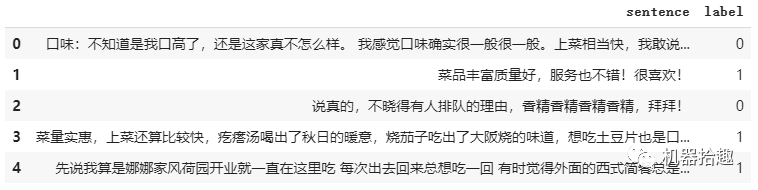
这是典型的文本二分类问题,也是BERT最为拿手的场景之一。
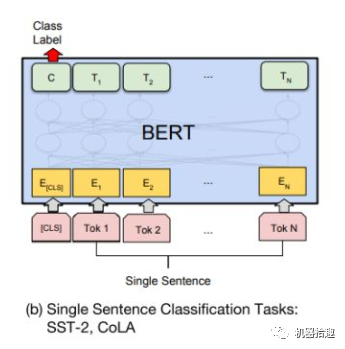
将原始句子Tokenize后,输入BERT,经过多层的Transformer变换,最后取第一个[CLS]
token的hidden state,然后接传统的Dense网络来输出。
BERT框架
Google自身是开源了BERT代码的。但是说实话,站在软件工程的角度来看,google原版的BERT代码“很不专业”,可读性、扩展性都非常的差。这里我们采用HuggingFaces的Transformers,是我认为写的很好的BERT框架之一。
用这个框架玩BERT模型,一般就是几板斧搞定,非常清晰:
从预训练权重初始化Tokenizer,将原始文本转化成input_ids、attention_masks。
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
input_ids = [tokenizer.encode(sent, add_special_tokens=True, max_length=MAX_LEN, pad_to_max_length=True) for sent in sentences]
attention_masks = [[float(i>0) for i in seq] for seq in input_ids]
model = BertForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2, output_attentions=True)
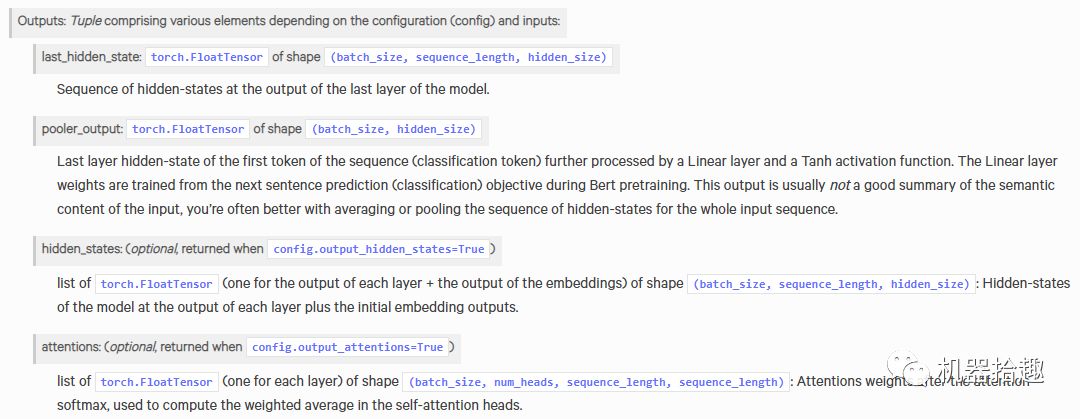
这里的关键点在于output_attentions=True
这个参数。Transforms里面的模型,输出都是一个tuple
,如图,分别是模型最后一层的各个hidden_state、[CLS]
token的向量表示、每一层的hidden_state(需参数)、每一层的attention(需参数)。
初始化模型之后,就是常规的分Epoch/Batch来训练了,过程这里不再赘述。
Attention Weights
这里我们拿出一个句子
text = '超级差评\xa0\xa0上菜慢\xa0服务态度超级差、先把汤上来喝饱了\xa0完事菜就上了一个,找服务员催半天也上不来最后结账态度超级差一个个子不高在门口附近桌子的服务员'
首先通过tokenizer来把文本数字化input_ids
,并得到相应的token_type_ids
和attention_mask
。
encoded = tokenizer.encode_plus(test)
input_ids = encoded['input_ids']
token_type_ids = encoded['token_type_ids']
attention_mask = encoded['attention_mask']
然后将它输入到训练好的BERT模型中,从输出拿到attention weights。
out = model.bert(torch.tensor(input_ids).reshape(1, -1).detach().to('cuda'), token_type_ids=torch.tensor(token_type_ids).reshape(1, -1).detach().to('cuda'))
attention = out[2]
注意这里的输入需要用detach
来从当前的计算图中分离开,不需要梯度,当一个data使。
这里得到的attention
是一个列表,长度是12,表示BERT模型的12层每一层的attention weights。
这里的12层,跟多层CNN模型类似,每一层都提取出了不同粒度的特征(如经典CNN网络做猫狗识别中,底层提取出了点和边的特征,中间层提取出了眼睛鼻子耳朵特征,高层再抽象出猫和狗)。BERT处理自然语言一样,底层是单个字的特征(最下面是每个字的word embedding),然后到词,然后是一些语义,最后到句子。可以说,BERT让自然语言处理真正到达了“深度学习“的时代。
然后我们看看每一层的attention
啥样:
attention[-1].shape
# torch.Size([1, 12, 71, 71])
这里的第1维是batch_size,第2维表示multi-head中的12个head,后面的71x71就是我们每一个token的两两attention矩阵了。
attention weights可视化
接下来就是把我们的attention weight可视化了。
首先,我们取倒数第2层的attention。为什么要倒数第2层呢?因为最后一层其实已经趋向于模型最终的二分类结果,不利于去观察每个token的情况。我非常欣赏的hanxiao博士,在他的大作bert-as-service
中,也是取得倒数第二层的hidden state作为特征提取:

我们的目标,是探寻每个字对于情感分析的影响,也就是说,第1个[CLS]
token和句子中的每一个字的attention权重:
att_matrix = attention[-2].squeeze(0)[:, 0, 1:-1]
这里-2表示取倒数第2层,squeeze(0)
取出batch,第1个:
取出所有的head,0
取出[CLS]
,1:-1
表示去掉句子中[CLS]
和[SEP]
的attention。最终,我们得到一个shape为(12, 69)的矩阵。
为了方便attention矩阵可视化观察,我们再将之归一化:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
scaled = scaler.fit_transform(attention[-2].squeeze(0)[:, 0, 1:-1].cpu().detach().numpy())
然后,就是拿出万能的excel了:
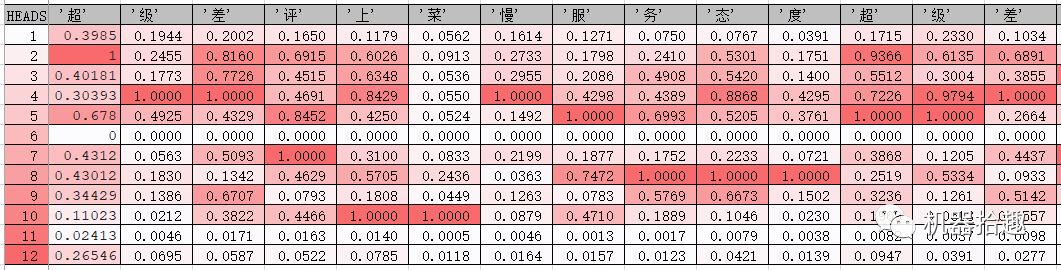
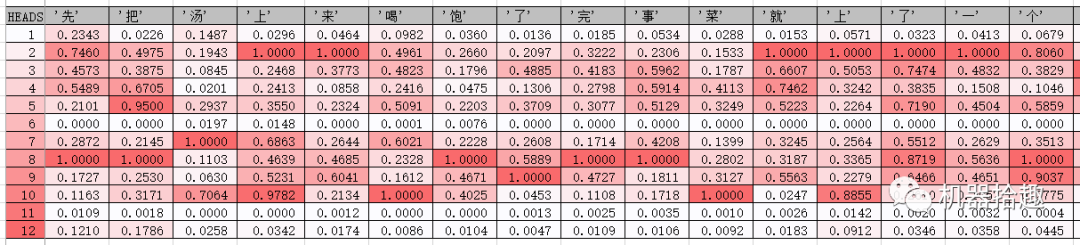
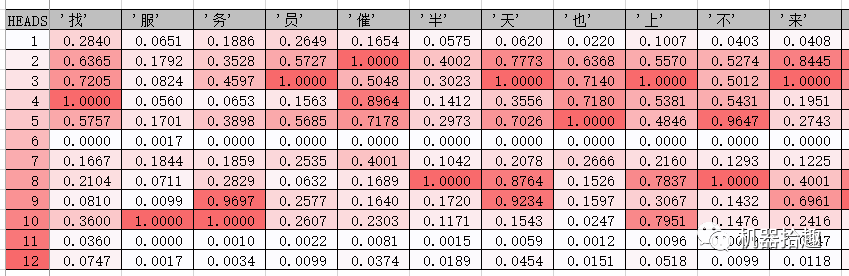
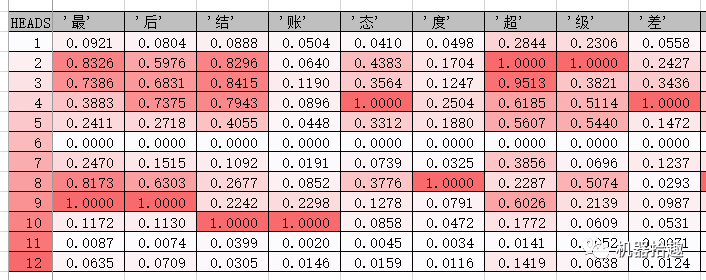
可以看到,我们的“多头猛兽”每一个头的关注点都不太一样。有的头关注了“超级差评”、“超级差”等字眼,有的头关注了“服务态度”,有的头关注了“催”等等。
从直觉来看,这些头关注的字词,应该是关乎这最终情感分类的关注点,即关注一些明显的情感词,但是仔细观察这些attention的值,好像又不完全是这样。就像CNN的feature map一样,这些仍属于深度学习不可解释的部分,attention机制模仿人类的注意力,但是它的实际运作,又不完全跟人类的注意力等同,就像深度学习的神经网络跟实际大脑的神经网络不同一样。
我相信,NLP的未来一定属于attention。随着我们对attention研究的进一步提升,能够去解释它,去掌控它,那么NLP一定会迎来更高的飞跃。
总结
可以说,正是因为BERT中Transformer的multi-head“多头”,再加上多个Transformer叠加的多层,如此大的容量容纳了非常多的信息,一方面使得它在理解文字语义方面优势明显,另一方面,也使得“预训练”成为可能。当然,大容量也导致了这个“多头猛兽”是难以驯服的,各个大厂也一度开始“军备竞赛”,模型越来越大,消耗的算力也越来越猛。当然,我们也非常欣慰的看到很多人也在研究如何把BERT简化,让它去适合更多的实际生产场景,如Google自家的ALBERT
、HuggingFace的DistillBERT
、华为的TinyBERT
等。
我一直认为,基于预训练的迁移学习,是深度学习技术相比传统机器学习最大的优势,也是非常类似人类去学习的一个过程。
要知道,ImageNet以及各种CNN预训练模型的百花齐放,使得深度学习在计算机视觉领域吊打一切;而BERT的横空出世, fast.ai创始人Sebastian Ruder非常兴奋的说:
NLP's ImageNet moment has arrived
最后
欢迎订阅我的微信公众号“机器拾趣”,第一时间免费收到文章更新。

如果你喜欢我的文章,请点右下角“在看”,并且把它转发给你身边有需要的朋友。
