





在上文教你用neo4j做lookalike(上)中,我们已经做好了基本的数据预处理,并生成了供Neo4J导入的csv格式数据。在这节中,让我们把数据导入Neo4J,开始我们的图数据库之旅。
Neo4J数据导入
这里假设大家对neo4j已经有了基本的了解。不清楚的同学可以参考下我之前写的文章手把手教你快速入门知识图谱 - Neo4J教程。
一般来说,neo4j的数据导入有以下几种方式:
CYPHER CREATE。这种方式可以实时插入,但是速度和吞吐量都很慢,只适合实验场景。 Java或Python API。这种方式适合小数据量的实时插入,实现一定程度上的增删改查。 CYPHER LOAD CSV。这种方式速度就好很多,适合中等数据量的批量插入。 Neo4j-import。这种方式速度是最快的,但缺点是插入的时候必须停止Neo4j,且只能生成新的数据库,因此只适合大数据量的初始化。
我们这里采用的是CYPHER LOAD CSV的方式。在上一章节中,已经生成好了相应的CSV,下面就是调用CYPHER语句将数据导入。这里有2个小trick:
我们是先导入节点node,然后再导入关系relationship。导入关系的逻辑,是先查找出相应的节点,再建立关系,因此为了查询速度的优化,我们要给节点的查找字段添加索引,如:
CREATE INDEX ON :Person(cust_num)
CREATE INDEX ON :Phone(phone_num)
另外,索引建立好后,记得运行:schema
确保索引已生效。
如果搭建neo4j的服务器性能有限,要避免jvm虚拟机在批量插入时内存不足,需要使用以下语句进行批量的事务提交
USING PERIODIC COMMIT 1000
节点导入
接下来就是LOAD客户节点了,注意这里有个操作,是将CSV中格式为STRING的embedding list转化为FLOAT list。
LOAD CSV WITH HEADERS FROM "file:///var/lib/neo4j/import/nodes.csv"
AS line
WITH line, split(substring(line.embedding, 1, length(line.embedding)-2), ",") as ems
CREATE (:Person {cust_num:line.cust_num, cust_name:line.cust_name, longitude:TOFLOAT(line.longitude), latitude:TOFLOAT(line.latitude), embedding:[item in ems | TOFLOAT(item)]})
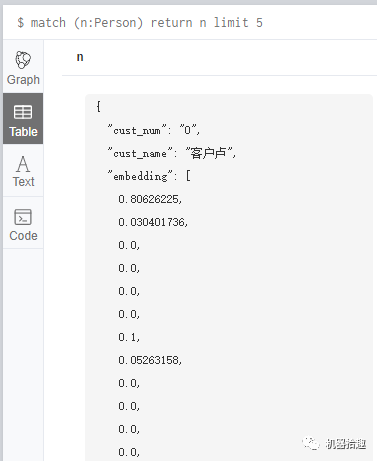
导入成功后,在neo4j里面查看一下,Person节点信息如下:
然后是手机号节点及城市节点:
LOAD CSV WITH HEADERS FROM "file:///var/lib/neo4j/import/phone_nodes.csv"
AS line
WITH line
CREATE (:Phone {phone_num:line.phone_num})
LOAD CSV WITH HEADERS FROM "file:///var/lib/neo4j/import/city_nodes.csv"
AS line
WITH line
CREATE (:City {city_cd:line.city})
关系导入
首先是用户拥有手机号的关系:
LOAD CSV WITH HEADERS FROM "file:///var/lib/neo4j/import/has_phone_relations.csv"
AS line
WITH line
MATCH (f:Person {cust_num: line.cust_num}), (t:Phone {phone_num: line.phone_num})
MERGE (f)-[r:HAS_PHONE]->(t)
RETURN count(r)
关系建立好后如图:
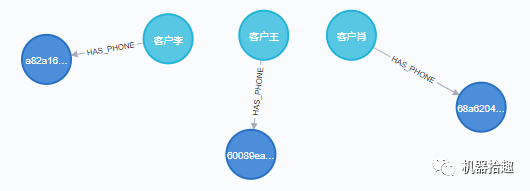
然后以此类推,分别是用户联系人的关系和用户所在城市的关系:
LOAD CSV WITH HEADERS FROM "file:///var/lib/neo4j/import/has_contact_relations.csv"
AS line
WITH line
MATCH (f:Person {cust_num: line.cust_num}), (t:Phone {phone_num: line.phone_num})
MERGE (f)-[r:HAS_CONTACT]->(t)
RETURN count(r)
LOAD CSV WITH HEADERS FROM "file:///var/lib/neo4j/import/in_city_relations.csv"
AS line
WITH line
MATCH (f:Person {cust_num: line.cust_num}), (t:City {city_cd: line.city})
MERGE (f)-[r:IN_CITY]->(t)
RETURN count(r)
lookalike实现
图谱建立好以后,就可以开始应用了。我们来看看在Neo4J中是如何优雅的实现的。
联系人扩散
联系人扩散的逻辑,就是根据种子用户,找到这些用户的联系人(父母、配偶、朋友等)。在图数据库里,可以非常自然的用以下语句实现:
MATCH (n:Person {cust_num: "3814"})-[r:HAS_CONTACT]->(p:Phone)<-[q:HAS_PHONE]-(m:Person)
WHERE n<>m
RETURN n, r, p, q, m
查询结果如下:
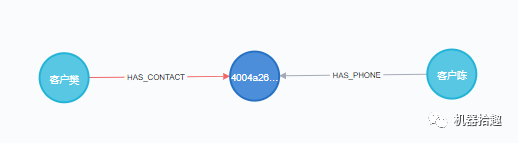
查询结果非常快,响应速度是毫秒级,而且这个速度跟数据量级基本关系不大。这就是图数据库相比传统的RDMS关系型数据库的优势。注意这里是2级关系的查询,关系级数越大,优势越明显。这是因为RDMS中对于这种关系的查找,需要全量数据的join,这是非常消耗计算资源的。而在图数据库中,关系作为“第一公民”,只会在需要查询的节点上做计算,不涉及join,因此速度非常快,且基本跟数据量无关。
地理位置扩散
地理位置扩散,难度会稍大一些了。业务逻辑是找到跟种子用户地理位置相近的用户,也就是说,根据GPS经纬度,找到某用户物理距离最近的一群用户。这就涉及了所有数据计算中的“噩梦”--笛卡尔积。
通过图数据库,我们可以在一定程度上预先减少笛卡尔积的运算量。还记得我们有个“IN_CITY”的关系么?我们可以预先查询出用户所在城市的其他用户,只在这些用户之间比较距离即可。如果数据做得细,可以增加城区、街道、甚至小区,这样计算量就更小了。
另外,根据两点的经纬度算物理距离,neo4j中也提供直接的函数,不用自己来写了。
match (n1:Person {cust_num:"200"})-[r:IN_CITY]->(p:City)<-[q:IN_CITY]-(n2:Person)
where n1<>n2
with n1, n2, point({longitude:n1.longitude, latitude:n1.latitude}) as p1,
point({longitude:n2.longitude, latitude:n2.latitude}) as p2
return n1.cust_num, distance(p1,p2)/1000 as dist, n2.cust_num
order by dist asc
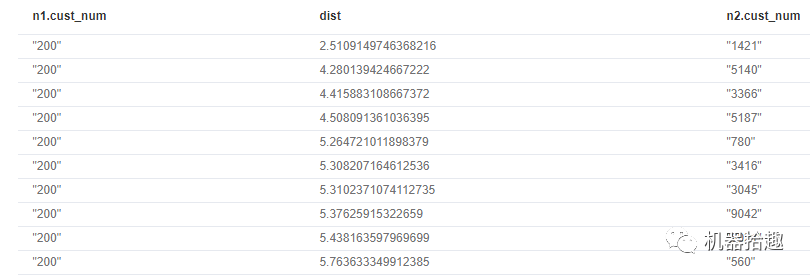
同样查询速度非常快,并且返回了客户号为200的用户,跟他距离最近的用户号及公里数。
用户行为扩散
这种扩散方式更加的“AI”。也是各个大厂的lookalike算法体现功力的地方。这里有两个问题,一是用户embedding如何生成,二是如何查询。
对于用户embedding的生成,我们在上文中采用的传统的机器学习的方式,使用已经做好的用户标签库来处理。在这里neo4j的帮助不大,我们不再多说。
在生成好的用户embedding上查询相近似的用户,这是典型的nearest neighbor场景,同样存在着笛卡尔积的噩梦。由于计算量非常的大,我们不推荐在每次查询时实时计算,而是预先在初始化的时候,把每个用户距离最近的TOP20计算好,动态生成固定关系,然后在服务的时候,只做一次查询操作即可。
注意这里使用到了neo4j的图算法库algo
,下载好相应的jar包如neo4j-graph-algorithms-3.5.13.0-standalone.jar
放到neo4j安装目录中的plugins文件夹,然后在conf文件中写入:
dbms.security.procedures.unrestricted=algo.*
接下来,就可以用如下CYPHER语句来生成关系了:
match (p:Person)
with {item:id(p), weights:p.embedding} as userData
with collect(userData) as data
CALL algo.similarity.euclidean(data, {
topK:20, write:true,
showComputations: true,
writeRelationshipType: "SIMILAR20"})
YIELD nodes, similarityPairs, computations
RETURN nodes, apoc.number.format(similarityPairs) as similarityPairs,
apoc.number.format(computations) as computations
这里我们采用了欧氏距离,并且为了演示计算的复杂度,我们把计算量computations也打印出来。
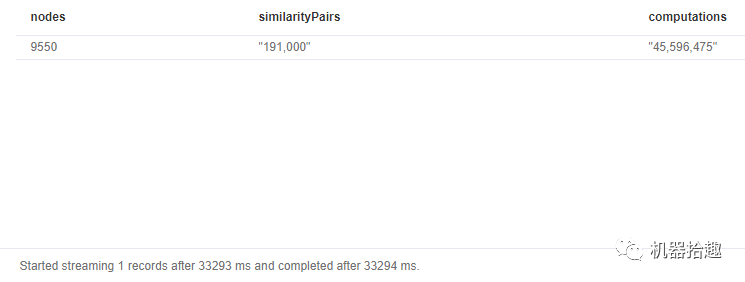
可以看到,我们的大致有9550个用户,neo4j安装在笔记本电脑的docker中,这条CYPHER语句运行了33秒,生成了19万条关系,计算量是惊人的4500万!
初始化完成以后,就可以开始查询了:
match (from:Person {cust_num:"200"})-[r:SIMILAR20]->(to:Person)
return distinct from, r, to
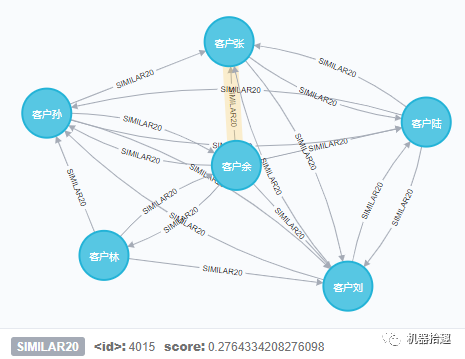
从结果可以看到,迅速返回了客户号为“200”的“客户余”跟他最相似的客户节点,以及这些客户之间的相似度分数。
批量扩散
上面几种演示,基本涵盖了常见的扩散方式。实际操作的过程中,需要根据场景、需求,设计好图模型,就能使用neo4j轻松实现lookalike。不过,还有一点就是,上面为了演示方便,都只查询了一个种子用户的情况,正常情况下,都是一批种子,如何实现呢?其实,用neo4j的unwind
语句就可以了。比如我们要批量查询5个用户的联系人扩散:
UNWIND ["0","1","2","3","4"] as x
MATCH (n:Person {cust_num: x})-[r:HAS_CONTACT]->(p:Phone)<-[q:HAS_PHONE]-(m:Person)
WHERE n<>m
RETURN m.cust_num
unwind
语句可以理解为编程语言中的循环,把一个列表中的值依次代入到后续的语句中执行,就可以高效地得到批量的结果。
总结
本文以一个实际的案例,分别从联系人扩散、地理位置扩散、用户行为扩散三方面演示了使用neo4j图数据库去做lookalike用户扩散的方法。当然,这里只是demo,在实际的生产环境中,还需要考虑很多工程化的问题,比如:
用户数据的更新如何导入,是T+1全量,还是实时增量?如果每日T+1,如果解决neo4j批量数据删除与重建? 当用户数据量达到一定程度,在地理位置扩散中,即使预先选定了城市,数据量也非常大,如何提升查询效率? 同样当用户量很大时,预先计算用户行为向量相似度的笛卡尔积也非常的大,计算量呈几何级数增长,非常容易内存OOM导致计算失败,如何解决?
这些具体问题,我们在后续的文章中再来探讨。
最后
欢迎订阅我的微信公众号“机器拾趣”,第一时间免费收到文章更新。

如果你喜欢我的文章,请点右下角“在看”,并且把它转发给你身边有需要的朋友。
