





起源
精准营销一直是大数据技术商业落地的重要场景之一。通过对用户的数据分析,找到精准的受众群来营销,可以在节省营销预算的前提下大幅提升转化率,使得数据产生价值。
在精准营销的各种技术中,有个很时髦的技术叫做“lookalike”。
什么是“lookalike”呢?
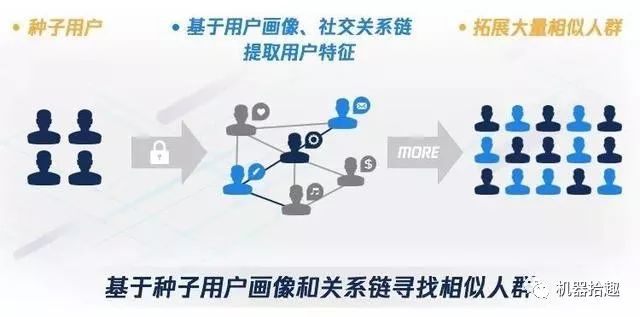
Lookalike技术基于种子用户画像和社交关系链寻找相似的受众,即在大量用户群中选择一组特定的种子(即有转化行为的)受众,包括但不局限于点击、下载、安装、激活,然后根据实际需求,筛选、识别、拓展更多相似受众,进一步引发更大客户量级的倍增。
我们先来看看lookalike之前,我们怎么来通过大数据精准营销。
首先,假定通过前期的大数据建设,我们已经有了比较完备的用户画像标签库
,包括用户性别、年龄、偏好等等。我们的业务人员根据业务经验,直接可以根据标签规则来筛选出用户群。举个例子,对于护肤品来说,用户群一般就是“18-40岁,女性,美妆偏好”等。筛选出来的潜在用户群,可以直接进行广告推送等触达,转化率肯定比广撒网更高,而且花费的成本还低。
但是,这种方式仍然有局限性。其一,如果业务人员无法准确定位人群特征怎么办?其二,如果需要对100w人投放,标签筛选只选出了30w人怎么办?
2012年,Facebook在广告领域开始应用定制化受众
(Facebook CustomAudiences)功能,这个功能可以让企业不用再选择标签,包括用户的基本信息、兴趣等,企业需要做的只是上传一批目前已有的用户或者感兴趣的一批用户,剩下的工作,就由受众发现
功能来完成。
像Facebook这样通过一群已有的用户发现并扩展出其他用户的算法就叫Lookalike。各个大厂纷纷在这个功能上发力,典型的包括腾讯在微信端的广告推荐的应用等。具体实现的技术也有多种,有基于规则定义的,有机器学习、深度学习来建模的,也有通过社交网络的。可以看到,lookalike是基于用户画像之上的、更直接的一种大数据应用。
今天,我们来介绍一种很优雅的方式:通过neo4j图数据库来实现lookalike。
思路
lookalike,即相似人群扩展
。基本原理就是根据各种维度,找到跟种子用户群
相似的人群。本文从最常见的几种场景入手,将维度大致分为基于联系人扩散、基于地理位置扩散、基于行为扩散。当然,实际生产中的扩散规则需要根据业务场景来仔细设计。
用户数据,特别是社交网络
上的用户数据,天然是图结构。节点
是用户,边
就是好友或联系人。使用图数据库,在选定某用户的情况下,根据社交关系来扩散,可以取得非常高效的查询效果。同样,我们把用户与用户之间的地理距离做成边、用户与用户之间的余弦相似度做成边,那么相似的查询接口,可以把这三种扩散关系快速得到。
我们的图数据schema
可以见下图:
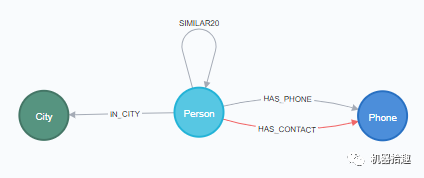
Person表示用户实体
,Phone表示手机号码实体
,City表示城市实体
。
用户和手机号之间有HAS_PHONE和HAS_CONTACT关系
,分别表示拥有手机号和联系人号码。
用户和城市之间有IN_CITY关系
,表示所在城市。
用户和用户之间有SIMILAR关系
,表示余弦相似。
数据
我们的数据直接来源于用户画像
,一般是存储在ElasticSearch
或者HBase
之上,以用户id为rowkey,每个标签为一个特征,标签值为特征值。标签包括静态属性如年龄、性别、手机号、联系人等,动态属性如gps位置、最近的点击行为、下载行为、购买行为等等。
我们将原始数据导入Pandas
,得到一个shape为(9550, 428)的DataFrame,即共有9550个用户,428个特征。
接下来是数据处理。处理的目的,是生成实体和关系的csv文件,用于neo4j的数据导入。
城市实体
城市实体很简单,取出DataFrame中的所有城市字段,去重即可。
all_city = set(df['City_Cd'].values)
with open('city_nodes.csv', 'w', newline='', encoding='utf-8') as f:
headers = ['city']
f_csv = csv.writer(f)
f_csv.writerow(headers)
for item in all_city:
f_csv.writerow([item])
手机号实体
手机号码分别存储在用户手机号及联系人手机号字段里,也是全部取出再去重:
all_phone_num = set(np.concatenate((df['Mobile_Num'].values, df['Contact_Tel'].values)))
用户实体
用户实体比较复杂。首先用户id,用户姓名,gps经纬度都可以直接得到。要做用户之间的余弦相似度,得把用户行为表示成一定维度的向量才行。这里就牵涉了基本的机器学习数据预处理操作。
首先我们将所需要的用户行为相关的特征字段分为连续数值型(numerical)和类别型(categorical)。
data_action_categorical = df[action_columns_string]
data_action_numerical = df[action_columns_float]
针对categorical类型,需要做OneHot
处理,我们直接用sklearn的api。
action_oh_enc = OneHotEncoder(handle_unknown='ignore')
data_action_categorical_onehot = action_oh_enc.fit_transform(data_action_categorical)
针对numerical类型,需要做归一化
,这样才能把每个维度的特征放在统一尺度来进行相似度运算。
mms_action = MinMaxScaler()
data_action_numerical = mms_action.fit_transform(data_action_numerical)
然后就可以把它们拼接在一起。由于sklearn的OneHot生成的是sparse矩阵,需要用到scipy.sparse的hstack。
df_action = hstack([data_action_numerical, data_action_categorical_onehot])
# df_action.shape (9550, 99)
这样,每个用户的行为数据被处理成一个99维的向量,可以进行余弦相似度运算了。在实际工作中,考虑到计算资源和效率的问题,可以使用PCA等算法将这个向量继续降维,具体可参考使用numpy来理解PCA和SVD。
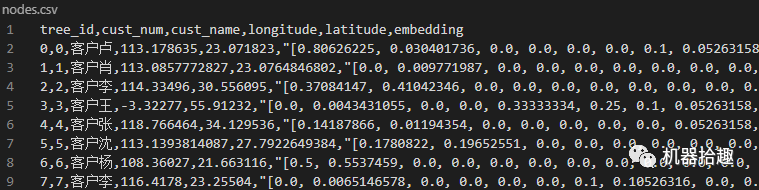
然后就是用户实体csv的创建了。除了常规的属性,我们把用户行为向量作为embedding属性存储。
with open('nodes.csv', 'w', newline='', encoding='utf-8') as f:
headers = ['tree_id', 'cust_num', 'cust_name', 'longitude', 'latitude', 'embedding']f_csv = csv.writer(f)
f_csv.writerow(headers)
index = 0
for item in df.itertuples():
f_csv.writerow([item[0], item[1], item[2], item[3], item[4], list(df_action[index])])
index += 1
可以大致看一下生成的csv的情况:
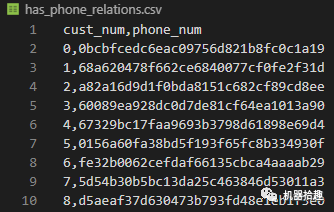
HAS_PHONE关系
这个比较简单,我们将csv分为两列,第一列为用户id,第二列为手机号(这里的手机号做了脱敏处理):
with open('has_phone_relations.csv', 'w', newline='', encoding='utf-8') as f:
headers = ['cust_num', 'phone_num']
f_csv = csv.writer(f)
f_csv.writerow(headers)
for item in df.itertuples():
f_csv.writerow([item[1], item[3]])
同理,我们可以得到HAS_CONTACT
关系、IN_CITY
关系,分别得到相应的CSV。
至此,数据处理已基本完毕,剩下的任务就是把csv数据导入neo4j,开始我们的图数据之旅,且听下回分解。
最后
欢迎订阅我的微信公众号“机器拾趣”,第一时间免费收到文章更新。

如果你喜欢我的文章,请点右下角“在看”,并且把它转发给你身边有需要的朋友。
