




TOC:一、概述二、基本语法结构三、关键字及语法四、函数五、性能调优
一、概述
Cypher(也称为CQL)是一种声明式图数据库查询语言。和SQL一样声明式语言只专注于图的表达而不关注怎么获得结果。Cypher支持事务,要么全部成果,要么全部失败。可以将多个查询放到一个事务中去提交。同时Cypher也支持唯一性,但只包括节点的唯一性,即查找“自己朋友的朋友”时,不会再查到自己;查询关系时,Cypher将尝试匹配两个方向的关系,互换开始结束节点,故关系并没有唯一性。
二、基本语法结构
Cypher语言主要分为增删改查(CRUD)四个部分,也可抽象成读和写两个部分。但是不能同时读和写数据,每个部分要么匹配,要么更新。当需要使用聚合进行过滤时,必须使用WITH将读和写连接起来。
基本语法:
单行注释使用
//关键字大小写不敏感,变量名大小写敏感
null意味着“一个未找到的未知值”,对待null的方式会稍有不同,具体含null值的计算需要查表
出现特殊字符用反引号 ` 括起来
字符串连接用
+返回所有结果使用星号
RETURN *
基本概念:
1. 点
节点有若干个标签,若干个属性,属性用键值对表示。
节点用圆括号
()
表示标签用冒号
:
表示,节点可以有多个标签节点属性用花括号加键值对
{键值对}
表示
示例:点
() //匿名节点(matrix) //命名节点(:Movie) //标签(matrix:Movie) //命名节点+标签(matrix:Movie:Film) //多标签(TheMatrix:Movie {title:'The Matrix', released:1999,tagline:'Welcome to the Real World'}) //节点标签+属性
2. 边
总有开始节点和结束节点,有且只有一个方向,有且只有一个类型,可以有若干属性,属性用键值对表示。
边用中括号
[]
表示类型用冒号
:
表示,只能有一个,可用|
做多选一边的属性用花括号加键值对
{键值对}
表示使用
*
指定关系的长度,使用..
指定可变长度
示例:边
(点1)-[:关系标签 {p1:['属性1']} ]->(点2)()-[r]-() //关系命名为r()-[:关系]-() //关系唯一,命名省略()-[:关系1|关系2|关系3]-() //关系多选一(a)-[*2]->(b) //关系的长度为2,即边的数量为2,即(a)-[r1]->(c)-[r2]->(b),注意边的方向(a)-[*3..5]->(b) //关系的长度为3~5,即满足3种模式p=(a)-[*2]->(b) //命名路径
注:当两点之间的关系是变长的,返回他们之间的关系可能就是一个关系列表!
注:如果变成路径的下界为0,则意味着两个节点为同一个节点。
图数据库与关系型数据库的类比
| 图数据库 | 关系型数据库 |
|---|---|
| 点 | 表 |
| 点标签 | 表名 |
| 点属性 | 表字段 |
| 点数据(标签+属性键值对) | 表的一行数据 |
| 相同标签的点数据 | 表的所有数据 |
类比示例:
| 元素 | 图数据库 | 关系型数据库 |
|---|---|---|
| 点 | (matrix) | entity |
| 点标签 | (matrix:Movie) | create table Movie (...) |
| 点属性 | {title,release,tagline} | create table Movie (id uuid pirmary key, title char,release number,tagline text); |
| 点数据(标签+属性键值对) | (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'}) | select * from Movie where id = 0; |
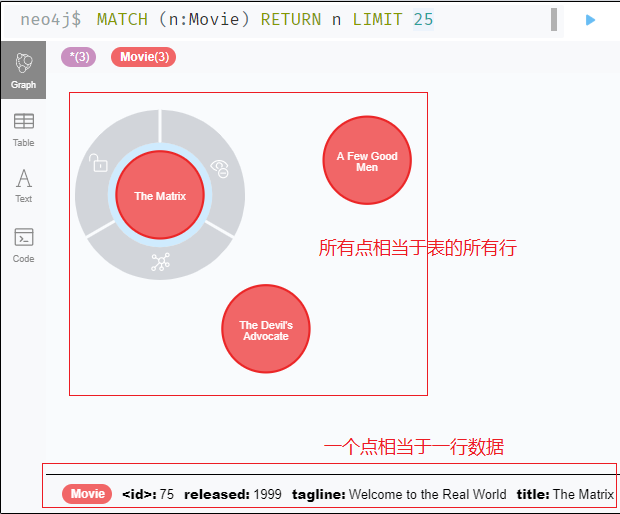
| 相同标签的点的所有数据 | MATCH (n:Movie) RETURN n LIMIT 25; | select * from Movie limit 25; |
相同标签一般拥有相似属性,不完全一样 <> 表的一行数据的列式相同的
示例:查询相同标签的所有点

3. 模式(Patterns)
点和边中单个元素信息比较局限,而图数据库的查询主要依赖于模式。最简单的(点)-[边]-(点)
可以组成一个最简单的模式。图数据库中,复杂的模式可以表达任意复杂的概念。使用模式可以描述为你期望看到的图的形状
。
示例:
create (Lily:Person{name:'Lily'})-[r:friend]->(Tom:Person{name:'Tom'})create (A:Person{name:'A'})-[r1:friend]->(B:Person{name:'B'})-[r2:friend]->(C:Person{name:'C'}) //朋友的朋友create (:Person)-[:LIVE_IN]->(:City)->[:PART_OF]->(:Country) //人-》城市-》国家Lily,Tom,A,B,C --> 点r,r1,r2 --> 边Lily 和 Tom 为朋友 --> 关系,简单模式C为A朋友的朋友 --> 复杂模式
Neo4j保证单个模式中匹配结果的唯一性,即查找“朋友的朋友”时,不会再查到自己。
数据类型
数值型
字符串:'Hello Cypher' "Hello Cypher"
布尔型:true, false, TRUE, FALSE
节点
关系
路径
映射(Map)
列表(List):['a','b'], [1,2,3], ['a','2','$param], []
下面对一些特殊数据类型进行说明:
数据类型之列表(List)
使用[ , , ]
来创建一组元素的列表。Cypher对于List的支持很好,常用使用方法如下:
range() 创建一个序列,左闭右闭
RETURN range(0,10) as list1 结果:[0,1,2,3,4,5,6,7,8,9,10] 使用[]访问list中的元素
with range(1,5) as list
with list, //"[1,2,3,4,5]"
list[0] as c1, //1
list[3] as c2, //第4个元素,从0开始
list[-3] as c3, //倒数第3个元素
list[1..3] as c4 //第2~第3个元素,左闭右开
return list,c1,c2,c3,c4;
结果:"[1,2,3,4,5]",1,4,3,"[2,3]"如果list值越界了返回null
size() 获取列表长度
with range(0,5) as l
return l,size(l) as s;
结果:"[1,2,3,4,5]",6List推导式(Comprehension)
通过映射和过滤函数,用已经存在的list构建新的list。整个断言包括WHERE都可被省略。 示例:例如10以内的整数 --> 10以内的偶数的立方
return [x in range(0,10) where x % 2 = 0 | x^3 ]
结果:"[0.0,8.0,64.0,216.0,512.0,1000.0]"
//模式推导式,注意区别
MATCH (a:Person {name: 'Keanu Reeves'})
RETURN [(a)-->(b) WHERE b:Movie | b.released] AS years
转义字符
| 字符 | 含义 |
|---|---|
| \t | 制表符 |
| \b | 退格 |
| \n | 换行 |
| \r | 回车 |
| \f | 换页 |
| \' | 单引号 |
| \" | 双引号 |
| \\ | 反斜杠 |
变量
可以对点、边、模式等用变量命名,在后面的语句中引用他们。类似SQL中的别名。变量区分大小写。包含字母数字下划线。如果有特殊字符可用反引号`括起来。变量只在同一个查询内可见。
参数
可以使用参数代替字面量来写Cypher。参数为字母+数字。已json文件的格式提供,具体如何提交取决于使用的驱动程序。
示例:参数
{ "name": "John" }
示例:使用参数构建查询
MATCH (n)
WHERE n.name = $name
RETURN n;
或
MATCH (n {name: $name}) RETURN n;
运算
比较等于和不等于使用
= 和 <>相同类型只有
不同类型不能比较,例如点和边和路径不能互相比较
List比较时,只有所有对应元素都相等列表才相等
Map比较时,只有Map的键相等且其指向的值也相等时才相等
路径比较时,只有路径上所有的点和边都相等时才相等
和null比较的结果还是null
三、关键字及语法
Cypher语法总体分为读和写,常用关键字如下:
读:MATCH, OPTIONAL MATCH, WHERE, START, 聚合, LOAD CSV
写:CREATE, MERGE, SET, DELETE, REMOVE, FOREACH, CREATE, UNIQUE
通用: RETURN, ORDER BY , LIMIT , SKIP, WITH, UNWIND, UNION , CALL
MATCH
常与where联用、可以出现在查询的开始或结尾,可以出现在with之后。
//查询
match (n) return n;
match (n:Movie) return n.title;
match (person {name:'Keanu Reeves'})--(movie) return distinct movie.title;
match (n {title: 'the matrix'}) return n;
match (:Person {name:'Keanu Reeves'})-[r]-(movie) return distinct movie.title,type(r);
//关系多选一
match (person:Person )-[r:ACTED_IN | DIRECTED]-(movie) return person,movie;
OPTIONAL MATCH
相当于SQL中的OUTER JOIN,找的和MATCH一样,找不到的项用null代替。
WHERE
在MATCH或OPTIONAL MATCH中添加约束,或与WITH一起用来过滤结果。又叫“断言”,可以出现在查询的前,中,后
示例:用方括号动态计算属性来过滤
MATCH (n) WHERE n[toLower($prop)] < 30 RETURN n;
示例:模式过滤
MATCH (a),(b) WHERE (a)<--(b)RETURN a,b;
CASE
简单式
CASE test
WHEN value THEN result
[WHEN ...]
[ELSE <default>]
END搜索式
CASE WHEN <predicate1> THEN result1
CASE WHEN <predicate2> THEN result2
[ELSE <default>]
END
START WITH
字符串匹配,区分大小写,类似于SQL中的LIKE %。其余还有END WITH
和 CONTAINS
IS NULL
测试一个值是否为空,相反为IS NOT NULL
START
使用遗留索引(Legacy Index)来查找,其他情况都应用MATCH
通过索引搜索(Index Seek)开始点。 语法:
node:<index_name>(key = "value")
或relationship:<index_name>(key = "value")通过索引查询(Index Query),语法
node:<index_name>("query")
或relationship:<index_name>("query")
。(使用复杂的Lucene语法)
CREATE
用于创建点和边。使用逗号分隔。注意创建边的前提是,首先要找到边的两个节点!使用CREATE时,模式中所有不存在的部分都会被创建
示例:创建点
CREATE (n)
CREATE (n),(m)
CREATE (n:Person),(m:Dog)
CREATE (n:Person:Chinese)
CREATE (n:Person {name:'Gaoj', age:'18'})
示例:创建边
//创建边
MATCH (a:Person),(b:Person) WHERE a.name = 'Gaoj' AND b.name = 'Neoob'
CREATE (a)-[r:RELATION1]->(b) RETURN a,b,r;
//创建边,有属性name,属性由 + 拼接字符串
MATCH (a:Person),(b:Person) WHERE a.name = 'Gaoj' AND b.name = 'Neoob'
CREATE (a)<-[r:RELATION2 { name: a.name + ' 我是分隔符 ' + b.name }]-(b) RETURN a,b,r;
MERGE
创建某个Patten,MERGE=MATCH + CREATE,类似于SQL中的MERGE+UPDATE,即没有则创建有则什么都不做。使用MERGE要不整个Pattern被匹配,要么整个Pattern被创建,不会应用于部分Pattern。
示例:MERGE与和MATCH+CREATE联合使用,类比SQL中的MERGE
MERGE (keanu:Person {name: 'Keanu Reeves'})
ON CREATE SET keanu.created = timestamp() //如果创建更新创建时间
ON MATCH SET keanu.lastSeen = timestamp() //如果找到更新时间,可以设置多属性,用逗号分隔
RETURN keanu.name, keanu.created, keanu.lastSeen
可以使用唯一性约束+MARGE可以防止获取冲突的结果。
SET
用于更新/删除点和边的标签和属性。
示例:修改点的标签
MATCH (n:Boy {name:'gaoj'}) SET n:Gril:Chinese示例:使用+=
添加属性
MATCH (p {name: 'PeTER'}) SET p += {hungry: TRUE, position:'Begger'}DELETE
删除点、边、路径。不能只删除点,而不删除与点相连的关系,要不显式的删除关系,要么使用DETACH DETELE
隐式删除
示例:删除一个点和其所有关系
MATCH (n {name:'gaoj'}) DETACH DELETE n示例:删除所有点边(清空图)
MATCH (n) DETACH DELETE n;REMOVE
用于删除属性和标签。Neo4j中不允许属性存null值,如果属性真的为空值,则其属性会被删除。
示例:删除属性
MATCH (a {name: 'Andy'}) REMOVE a.age示例:删除多个标签
MATCH (n:Chinese:German:Swedish {name: 'Peter'}) REMOVE n:German:SwedishFOREACH
用于更新列表中的数据,或来自路径的组件,或者来自聚合的结果。它可以在集合或路径的每一个元素上执行更新命令。FOREACH中的变量是和外部分开的,类似游标。
在FOREACH中可以执行任何UPDATE和CREATE, CREATE UNIQUE, DELETE , FOREACH。
如果希望对列表里的元素执行额外的MATCH,使用UNWIND命令更合适。
示例:更新路径,路径删的所有节点的marked属性设置为True
MATCH p=(start)-[*]->(finish)
WHERE start.name = 'A' AND finish.name = 'D'
FOREACH (n IN nodes(p) | SET n.marked = true)
示例:更新列表,将小红小明小白全部加为老王的好友
MATCH (a:Person {name:"老王"})
FOREACH (i in ["小红","小明","小白"] | CREATE (a) -[:FRIEND]->(:Person {name:name}))
CREATE UNIQUE
匹配所有模式,创建不存在的。类似于MERGE,但是保证关系是唯一的,如果找到多个匹配的子图,那么CREATE UNIQUE会报错。
RETURN
定义查询结果集返回的内容。
示例:返回所有
MATCH p=(a {name:'A'}) -[r]->(b)
RETURN *
如果RETURN的属性不存在,可以正常查询,但是会返回Null
ORDER BY
紧跟 RETURN 和 WITH,用来给结果排序。能排序其属性,点都是无序的!默认升序,降序使用DESC
注意:结果含null的情况,升序null会拍在最后,而降序null会排在最前
LIMIT
限制返回的行数,可用任意表达式,但必须是正整数。
SKIP
定义从哪行开始返回结果
示例:
MATCH (n)
RETURN n
ORDER BY n.name
SKIP 1
LIMIT 3+1;
WITH
将分段的查询连接在一起,传递给另外一部分作为查询的开始。
常用于限制传递给MATCH的结果数
通过ORDER和LIMIT,可获取前面的的结果
还可用于将图语句中的“读和写分开”
示例1:过滤聚合结果
MATCH (david {name: 'David'})--(otherPerson)-->()
WITH otherPerson, count(*) AS foaf
WHERE foaf > 1
RETURN otherPerson.name
示例2:获取后面的结果
MATCH (n)
WITH n
ORDER BY n.name DESC
LIMIT 3
RETURN collect(n.name)
MATCH (n {name: 'Anders'})--(m)
WITH m
ORDER BY m.name DESC
LIMIT 1
MATCH (m)--(o)
RETURN o.name
UNWIND
将一个列表展开为一个序列的行。
示例:list行去重
WITH [1, 1, 2, 2, 2, 3] AS coll
UNWIND coll AS x
WITH DISTINCT x //与DISTINCT联用
RETURN collect(x) AS setOfVals //使用collect重新组装成list
结果:[1,2,3]
示例:列表拼接,列表拼接+去重
//列表拼接
WITH [1, 2, 3, 4] AS a, [3, 4, 5 ,6] AS b
UNWIND (a + b) AS x
return collect(x)
结果:[1, 2, 3, 4, 3, 4, 5, 6]
//列表拼接+去重
WITH [1, 2, 3, 4] AS a, [3, 4, 5 ,6] AS b
UNWIND (a + b) AS x
WITH DISTINCT x AS y
return collect(y)
结果:[1, 2, 3, 4, 5, 6]
//上面CQL可简写成
WITH [1, 2, 3, 4] AS a, [3, 4, 5 ,6] AS b
UNWIND (a + b) AS x
RETURN collect(distinct x)
UNION
将多个查询组合起来。和SQL类似,多个查询的列的名称和数量要一致!
CALL
调用SP。使用参数列表(逗号分隔)的形式给SP传参。
CALL org.neo4j.procedure.example.addNodeToIndex('users', 0, 'name')四、函数
id()
where中使用,可查询节点,也可查询关系
//使用id查询
MATCH (n) WHERE id(n) = 123 RETURN n;
type()
//返回关系的类型
//返回Reeves有关的电影名,和他在这个电影关系的类型(ACTION_IN)
match (director {name:'Keanu Reeves'})-[r]-(movie) return distinct movie.title,type(r);
shortestPath() 和 allShortestPaths()
//返回最短路径,注意不是路径数
MATCH (a:Person {name: 'Geena Davis'}),
(b:Person {name: 'Keanu Reeves'}),
p = shortestPath((a)-[*..15]-(b))
RETURN p limit 1;
//返回所有最短路径
Finds all the shortest paths between two nodes
relationships()
//返回模式中的所有关系
MATCH (a:Person {name: 'Geena Davis'}),
(b:Person {name: 'Keanu Reeves'}),
p = shortestPath((a)-[*..15]-(b))
RETURN relationships(p) limit 1;
exists()
检查点或边是否存在,原来的has()函数
MATCH n WHERE exists(n.belt) WHERE n;正则表达式
语法为Java的正则语法,使用~=
,放在正则表达式的开头。
| 符号 | 含义 |
|---|---|
| (?i) | 不区分大小写 |
| (?m) | 多行 |
| (?s) | 单行 |
下面介绍聚合函数,类似SQL中的GROUP BY。
COUNT()
SUM()
percentileDisc() 和 percentileCont()
计算百分位,取值从0.0~1.0,使用舍入法取最接近的值。
MATCH (n:Person) RETURN percentileDisc(n.age, 0.5);percentileCont同percentileDisc,使用线性插值,在两个数之间计算一个加权平均值。
stdev() 和 stdevp()
标准差。当以部分样本作为无偏估计时使用stdev,当计算整个样本的标准差是使用stdevp
max() 和 min()
最大最小值
collect()
所有值放进一个列表,null值被忽略,用于把行转成列
MATCH (n:Person) RETURN collect(n.age)
[11,31,34,66]
distinct
所有聚合函数都可以带DISTINCT去重
load csv
从CSV文件导入数据。fildterminator指定分隔符。
using periodic commit 5000
load csv from 'http://neo4j.docs./develober-manual/3.1/csv/artists-fieldterminator.csv' as line
fieldterminator ';'
create (:Artist {name: line[1], year: toInt(line[2])})
五、性能调优
在内存运行的情况下,尽量将查询部门链接在一起写
使用参数来构建查询,可以让执行计划的缓存更加容易
如果只查询属性,则尽量避免返回整个节点或关系
(TO BE CONTINUED)
