







每次用百度搜索一些想要的知识时,总是找不到想要的结果,还很耗费时间,如果有什么机器可以完成我问它答就好了。
哎?这个不就是我最近在看的自动问答系统嘛。用户可以使用自然语言进行提问,机器用自然语言回答用户的问题。家里常用的小度和天猫精灵就是自动问答系统成功的商业案例!

那向我们介绍一些关于自动问答的知识吧!
可以呀!想要了解的话一起往下看吧~
自动问答系统的定义
自动问答系统(Question and Answering System):能够对人类自然语言进行识别,并准确回答人类所提出的问题的机器人。比如以下的智能语音机器人。



自动问答系统的研究背景
随着互联网的发展,以关键字和网页链接为基础的传统搜索引擎逐渐难以满足用户从海量的数据库中准确获得自己所需数据的需求。可以将搜索引擎的缺点归纳为以下三点:
1.检索需求的表达不够准确
2.检索结果不够简洁
3.缺乏语义处理技术的支撑
正是由于传统的搜索引擎所存在的可以提升的缺点,这些用户需求就催生了自动问答系统;另一方面,自然语言处理领域的分词技术、属性抽取等知识的发展和成熟,为自动问答系统的问世奠定了坚实的基础。
自动问答系统的发展
自动问答系统的起源可以追溯到1950s图灵测试的提出,随后经过不同时代技术人员的不断探索和设计,有了不同时代对应的自动问答系统的产物,具体如下面的表格:
不同时期自动问答系统的发展 | 代表作品 |
图灵测试(QA系统的蓝图) | 1950s |
早期的QA系统 | BASEBALL(1961s) LUNAR(1973s) |
可对话的系统 | ELIZA(1966s) , SHRDLU(1971s) , GUS(1977s) |
阅读理解系统 | SAM(1970s) |
基于大规模文档集的问答 | START(1993年至今) |
下面挑其中几个代表性的作品为大家作简单的介绍~
01
早期的QA系统后台都有一个人工编制的数据库,保存系统可提供的各种数据。在用户提问时,系统把用户的问题转换成SQL查询语句,从数据库中查到数据返回给用户。由于领域狭窄,词汇总量有限,其语言和语用的歧义问题可以得到有效的控制。问题是可预测的,词汇总量很有限,合成相应的答案自然有律可循。
02
ELIZA是最早的与人对话的系统,是世界上第一个真正意义上的聊天机器人,诞生于MIT实验室,她模拟一个心理医生跟病人进行对话。Eliza用的是模式及关键字匹配和置换的方法,没有发展成一套系统的技术。
03
1993年,MIT人工智能实验室发布了START系统。该系统是第一个真正意义上的问答系统,其直接向用户返回一个简短精确的答案文本,明显区别于返回网页列表的搜索引擎系统。Start是世界上第一个基于Web的QA系统,自从1993年12月开始,它持续在线运行至今。现在Start能够回答数百万的多类英语问题,包括“place”类(城市,国家,湖泊,天气,地图,人口统计学,政治和经济等),电影类(片名,演员和导演等),人物类(出生日期,传记等),词典定义类等。
自动问答系统的分类及框架
常见的自动问答系统根据用户数据、信息查询方式等可以分为不同种类,其分类大致如下图所示。
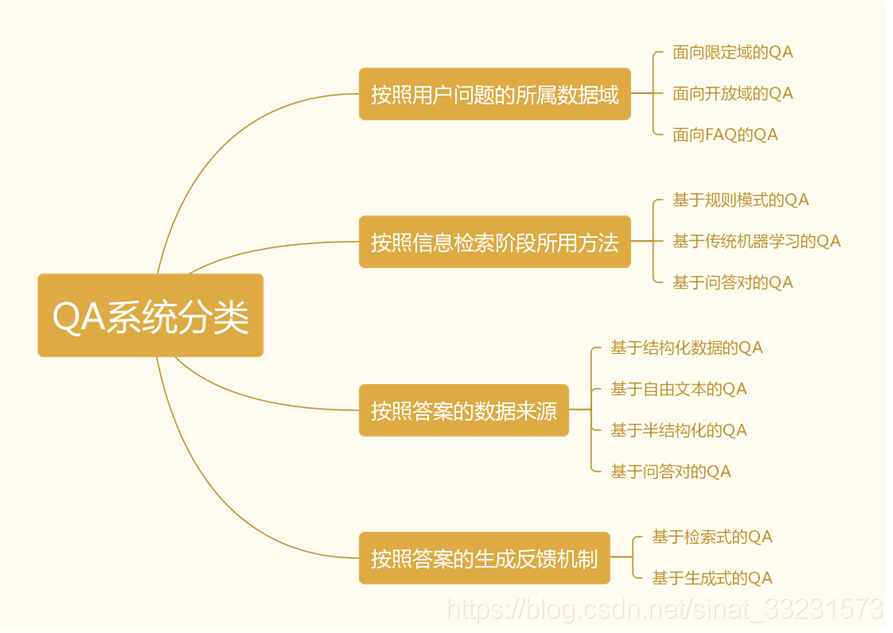
不同类型的问答系统对于数据处理的方法存在不同,例如,相对于面向FAQ的问答系统的问句检索直接得到候选答案,面向开放领域的问答系统首先需要根据问题分析的结果进行相关文档、文本片段信息的检索,然后进行候选答案的抽取。
虽然不同类型的问答系统对于系统模块的功能分工和具体实现存在差异,但依据数据流在问答系统中的处理流程,一般问答系统的处理框架中都包括问句理解、信息检索、答案生成三个功能组成部分。

提问处理模块:负责对用户的提问进行处理;生成查询关键词(提问关键词,扩展关键词,···);确定提问答案类型(PER,LOC,ORG,TIM,NUM)以及提问的句法、语义表示等等。
检索模块:根据提问处理模块生成的查询关键词,使用传统检索方式,检索出和提问相关的信息;返回的信息可以是段落也可以是句群和句子。
答案抽取模块:从检索模块检索出的相关段落、或句群、或句子中抽取出和提问答案类型一致的实体,根据某种原则对候选答案进行打分,把概率最大的候选答案返回给用户。
不同类型的自动问答系统具体的实现细则也有区别,下面我们就简单的FAQ系统,为大家做一个简单的实现~
FAQ系统的简单实现
要动手实现一个简单的FAQ系统,首先我们要清楚什么是FAQ系统,实现该系统的技术框架和路线是怎么样的,然后搭建自己的整个系统。
FAQ,全称为Frequently Asked Questions(基于常见问题集的问答系统):FAQ把用户常问的问题和相关答案保存起来,使得用户使用系统更加便捷。当用户输入问题时,如果在已有的“问题——答案“对集合中能找到与之相匹配的问句,系统就直接把相应的答案反馈给用户,而不需要经过问题理解、信息检索、答案抽取等复杂的处理过程。
FAQ系统的整体流程框架如下图所示:
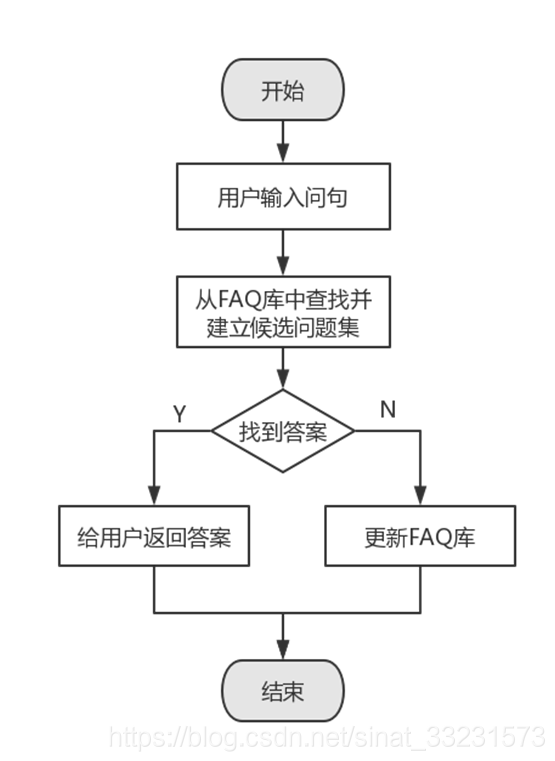
FAQ自动问答系统中需要处理的主要问题是候选问题集的建立、句子相似度计算、FAQ库的更新。
下面来看看整体的FAQ流程:
首先需要对输入的数据进行预处理,比如去停、分词等;
然后需要对预处理之后的语料进行向量化,向量化的方法很多,不拘泥于一种,常见的向量化方法有词频向量化、word2vec、tf-idf等方法;
向量化之后,就可以进行文本相似度计算了然后我们可以选取相似度最高的问题答案输出。

由此,我们可以归纳出我们要做的三件事:
1.创建问题集、答案集
2.分词部分
3.向量化部分,通过余弦相似度匹配得出相似度最高的结果后输出
至此可以将我们的程序分为以下几个板块。
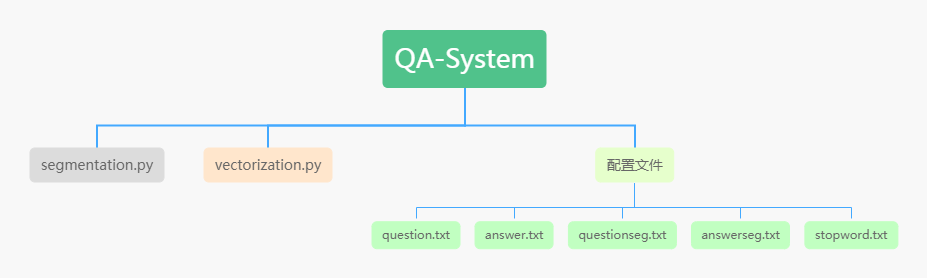

1.构造问题集与答案集

2. 分词
在分词板块中我们运用了停用词表,用Python调用jieba的分词包直接分词,分词的结果会自动过滤掉停用词表中的字符,这样在相似度对比查找时可以节省大量的时间,提升算法效率。下面是具体的算法程序:

import jieba
def stopword_list():
stopwords = [line.strip() for line in open('stopword.txt', encoding='utf-8').readlines()]
return stopwords
def seg_with_stop(sentence):
sentence_seg = jieba.cut(sentence.strip())
stopwords = stopword_list()
out_string = ''
for word in sentence_seg:
if word not in stopwords:
if word != '\t':
out_string += word
out_string += " "
return out_string
def segmentation(sentence):
sentence_seg = jieba.cut(sentence.strip())
out_string = ''
for word in sentence_seg:
out_string += word
out_string += " "
return out_string
inputQ = open('Question.txt', 'r', encoding='gbk')
outputQ = open('QuestionSeg.txt', 'w', encoding='gbk')
inputA = open('Answer.txt', 'r', encoding='gbk')
outputA = open('AnswerSeg.txt', 'w', encoding='gbk')
for line in inputQ:
line_seg = seg_with_stop(line)
outputQ.write(line_seg + '\n')
outputQ.close()
inputQ.close()
for line in inputA:
line_seg = seg_with_stop(line)
outputA.write(line_seg + '\n')
outputA.close()
inputA.close()
3.向量化&相似度对比
接下来是对用户提出的问题以及问题集的分词结果进行词向量化,对词汇进行向量化之后,可以用数学方法对其进行向量的相似度的对比,从而科学地得出词汇之间的相似度。在本程序中,我们使用余弦相似度进行比对,余弦相似度对比是常见的文本比对的方法。具体程序如下:

from sklearn.feature_extraction.text import CountVectorizer
import math
from segmentation import segmentation
count_vec = CountVectorizer()
def count_cos_similarity(vec_1, vec_2):
if len(vec_1) != len(vec_2):
return 0
s = sum(vec_1[i] * vec_2[i] for i in range(len(vec_2)))
den1 = math.sqrt(sum([pow(number, 2) for number in vec_1]))
den2 = math.sqrt(sum([pow(number, 2) for number in vec_2]))
return s / (den1 * den2)
def cos_sim(sentence1, sentence2):
sentences = [sentence1, sentence2]
vec_1 = count_vec.fit_transform(sentences).toarray()[0]
vec_2 = count_vec.fit_transform(sentences).toarray()[1]
#print(len(vec_1), len(vec_2))
return count_cos_similarity(vec_1, vec_2)
def get_answer(sentence1):
sentence1 = segmentation(sentence1)
score = []
for idx, sentence2 in enumerate(open('QuestionSeg.txt', 'r')):
score.append(cos_sim(sentence1, sentence2))
if len(set(score)) == 1:
print('暂时无法找到您想要的答案。')
else:
index = score.index(max(score))
file = open('Answer.txt', 'r').readlines()
print(file[index])
while True:
sentence1 = input('请输入您需要问的问题(输入q退出):\n')
if sentence1 == 'q':
break
else:
get_answer(sentence1)
4.测试
请输入您需要问的问题(输入q退出):
自动问答系统
FAQ是基于常见问题的问答系统,它把用户常问的问题和相关答案保存起来,使得用户使用系统更加便捷。
请输入您需要问的问题(输入q退出):
QA系统
QA系统是能够对人类自然语言进行识别,并准确回答人类所提出的问题的机器人。
请输入您需要问的问题(输入q退出):
中国传媒大学
中国传媒大学(Communication University of China)简称“中传”,位于首都北京,是中华人民共和国教育部直属的信息传播领域行业特色大学,国家“世界一流学科建设高校””。
请输入您需要问的问题(输入q退出):
李姣
暂时无法找到您想要的答案。
请输入您需要问的问题(输入q退出):
q
Process finished with exit code 0
好啦~至此为大家简单地介绍了自动问答系统,相信大家都各有所获~我们下期见!

本文作者:


指导教师:

喜欢我们的话就动动手关注我们吧!



