





点击上方蓝字,关注我们


作为数据科学最受喜爱的预测算法之一,
我们在尝试建立一个好的预测模型时都会
想到随机森林。它是一种强大的机器学习
集成技术,但大多数人往往会忽略
其中的OOB_SCORE。
忽略OOB_SCORE,就无法完全理解
随机森林这一集成方法的强大之处。
那么,我们就开始“补课”吧~
随机森林快速入门
相信大家对决策树都很熟悉,它是用于有监督学习的最佳可解释模型之一,使用if-else进行决策和预测,长下面这样:
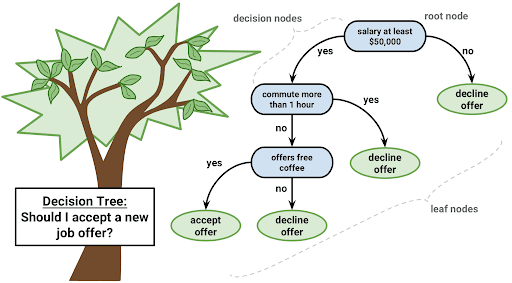
决策树很容易理解,并且具有比较好的可解释性。但它的缺点也是非常明显的:
① 长到最大深度的完全决策树对于训练样本来说是“过度拟合”的,也就是对训练样本的特征描述得“过于精确”了,无法实现对新样本的合理分析;
② 应用于测试数据会由于高方差(数据的微小变化可能会导致完全不同的树生成)而产生较大的误差
因此,为了做到更小的误差和更好的解释性,随机森林出现了。
随机森林是一种用于分类和回归问题的集成学习方法,通过在训练时构造多个独立的决策树,并用投票法或取均值法从所有树的输出中确定最终预测结果。
在一个随机森林算法中构造多个决策树有助于模型对数据模式进行泛化而不是学习数据模式,从而减少方差(减少过拟合)。
但是,如何为每一棵决策树选择对应的训练集呢?Bootstrapping就登场了!

Bootstrapping和袋外样本
使用Bootstrapping法构造随机森林中每个决策树的训练集,就像下面这样:
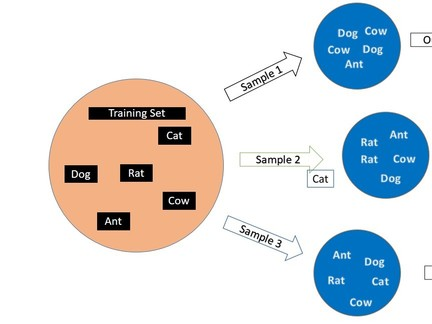
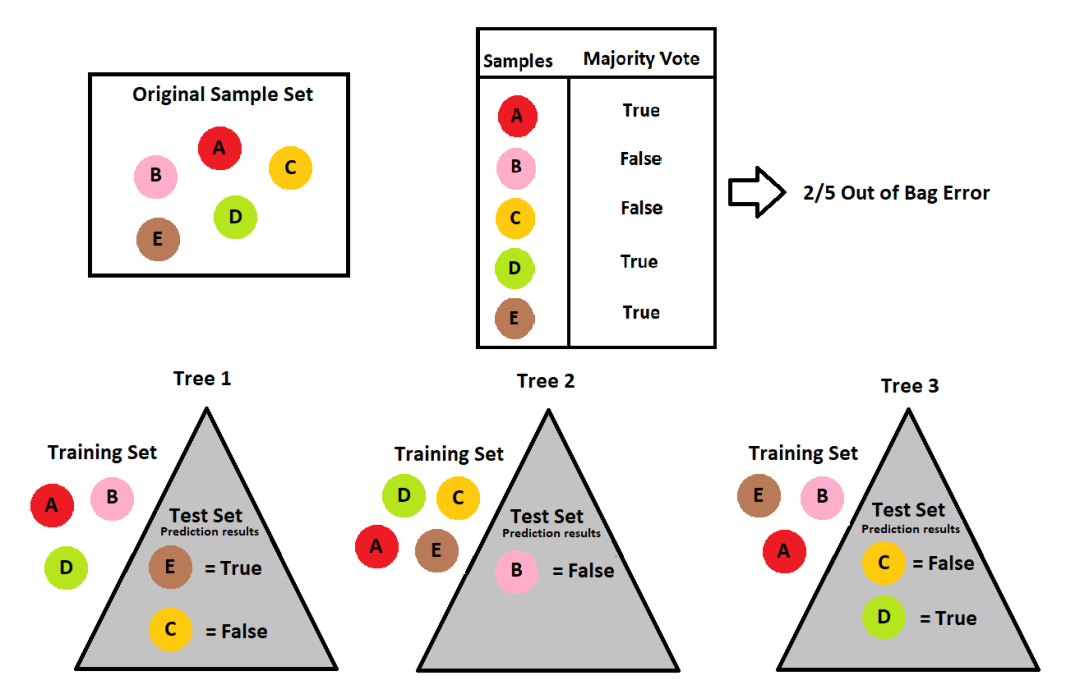
初始数据集为{Dog,Cat,Rat,Ant,Cow},每次随机且有放回地从中选取一个样本放入训练集中,直到训练集和初始数据集同等规模。按照同样的方法可以构建多个不同的训练集,每个训练集生成一棵决策树。
袋外样本
在上面的例子中,我们可以注意到,有些样本在训练集中重复出现,而有些样本则一次也没出现:
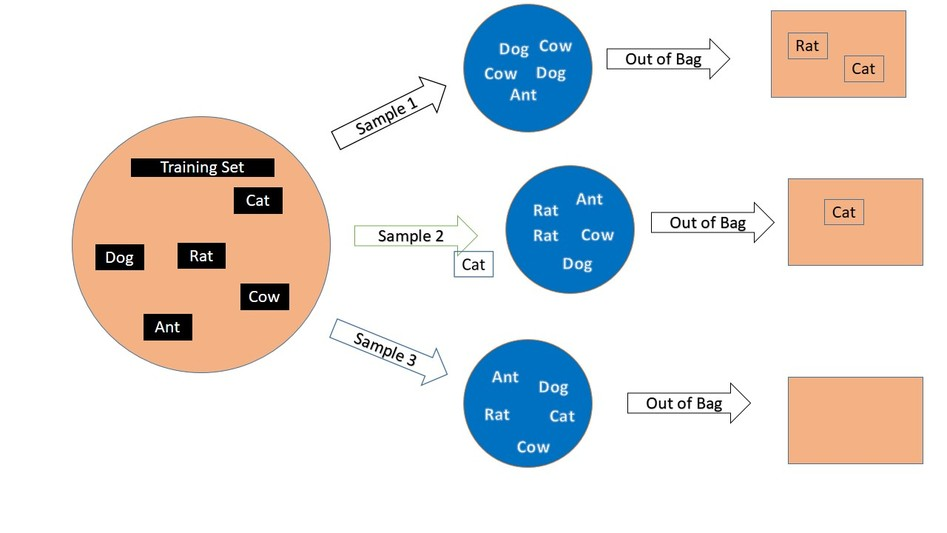
(训练集1中没有Rat和Cat,2中没有Cat)
Bootstrapping每次约有1/3的样本不会出现在所采集的训练集中,当然也就没有参加决策树的建立。这1/3的数据就称为袋外数据OOB(Out of Bag),可用于取代测试集进行误差估计。在这里,Rat和Cat就是在训练集1上构建的决策树的袋外数据OOB。
OOB_SCORE
OOB_SCORE是一种非常强大的模型验证技术,专门用于随机森林算法以实现最小方差结果。

注意:在使用交叉验证技术时,每个验证集已经被少数决策树看到或用于训练中,因此存在数据泄漏问题,会导致更大的方差。但使用OOB_SCORE可以防止这种泄漏,并且给出一个较好的低方差模型,因此我们使用OOB_SCORE对模型进行验证。
在了解了OOB后,OOB_SCORE又是什么呢?
沿用之前的例子,我们使用的初始数据集如下,分类目标变量为“是否能当宠物养”:
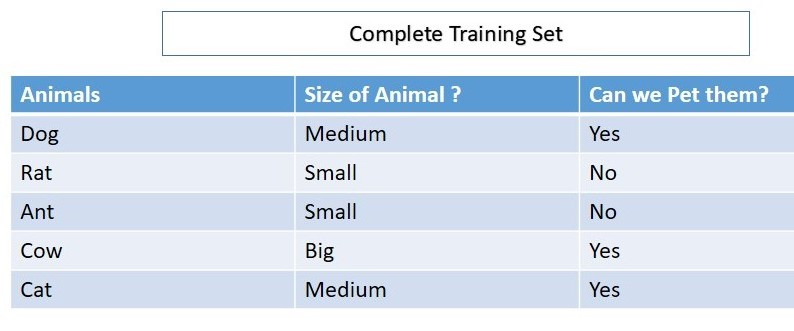
对于随机森林构建的多棵决策树,其中一棵决策树(记为DT1)的训练集如下:
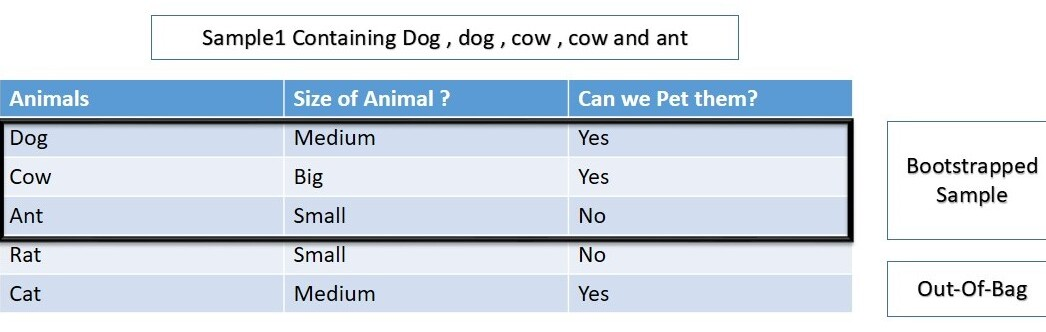
在这里,Rat和Cat对于DT1是OOB,因此我们将使用DT1预测Rat和Cat的值。(注意:训练树时DT1尚未看到Rat和Cat这两个数据)
就像DT1一样,其他决策树也会有自己对应的OOB。我们假设DT3、DT7和DT100也将Rat作为OOB数据点,也就是说,在预测Rat的值之前,他们都没有看到Rat这一样本。
记录DT1、DT3、DT7和DT100对Rat的预测值。观察到其中的大多数预测结果和实际值相同。(要注意:这其中没有一个模型以前见过Rat,但仍预测正确)
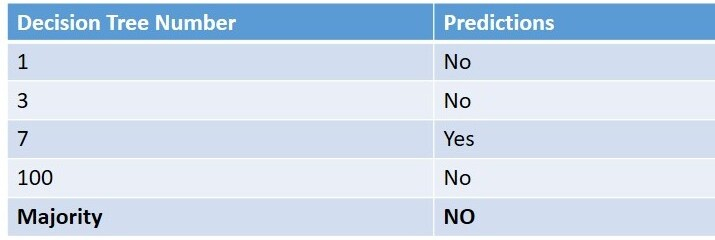
类似地,每个数据样本都被传递到它作为OOB的所有树中进行预测,所有预测的多数作为这一数据样本的预测结果。
看到这里,你一定已经明白了,OOB_SCORE就是袋外估计准确率得分,即对袋外样本正确预测的比例。
对应的,OOB_ERROR就是对袋外样本预测错误的比例。
使用OOB_SCORE的优点
① 没有数据泄露:由于模型是在OOB样本上验证的,这意味着在以任何方式训练模型时都没有使用到这些数据,因此没有任何数据泄漏,从而确保了更好的预测模型。
② 更小的方差:因为OOB_SCORE确保了没有泄漏,所以数据不会过度拟合,因此方差最小。
③ 更好的预测模型:OOB_SCORE有助于得到最小方差,因此它比其他验证技术更适合于预测模型。
④ 更少的计算:允许在训练数据时对其进行测试。
使用OOB_SCORE的缺点
① 耗时:该方法允许在训练数据时对其进行测试,但与其他验证技术相比,整个过程有点耗时。
② 不适用于大型数据集:由于与其他技术相比,该过程可能有点耗时,因此如果数据量很大,则在训练模型时可能需要更多的时间。
③ 最适合中小型数据集:即使这个过程很耗时,但如果数据集是中型或小型的,OOB_SCORE应该比其他技术更能获得一个好的预测模型。
总结
如果我们使用OOB_SCORE技术,那么随机森林可能是一种能够得到更好的预测结果的非常强大的技术。即使有点耗时,但是将OOB_SCORE参数设置为True来训练随机森林模型所花费的时间还是值得的。
作者介绍


指导老师


长按二维码关注我们

长按二维码关注沈浩老师
参考来源:
https://www.analyticsvidhya.com/blog/2020/12/out-of-bag-oob-score-in-the-random-forest-algorithm/
