







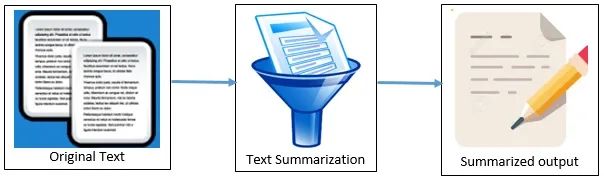
文本摘要是一种NLP技术,可从大量数据中提取文本。它有助于创建可用大文本的较短版本。
这很重要,因为:
减少阅读时间
帮助更好的研究工作
增加可以容纳一个区域的信息量
文本摘要有两种方法:基于NLP的技术和深度学习技术。
在本文中,我们将介绍一种基于NLP的技术,该技术将使用NLTK库。
取得资料
文字预处理
将段落转换为句子
标记句子
查找发生的加权频率
用句子中的加权频率替换单词
按权重降序对句子排序
总结文章
如果希望总结网页上的文章摘要,可以通过获取网页文章的 URL,使用Web抓取的概念从URL获取数据。这种方法需要用到Python中的beautifulsoup库。该库将用以在各种HTML标签内获取网页上的数据。
首先,安装beautifulsoup库,需要用到以下命令:
pip install beautifulsoup
为了解析 HTML标签,我们需要一个解析器,即LXML包:
pip install lxml
通过以下代码,我们在网络上获取数据:
import bs4 as bsimport urllib.request #解析URL的包import re #用于文本预处理的正则表达式的库import nltknltk.download('punkt')url="https://en.wikipedia.org/wiki/Reinforcement_learning"scraped_data = urllib.request.urlopen(url)#urlopen:抓取数据article = scraped_data.read()#读取URL中的数据parsed_article = bs.BeautifulSoup(article,'lxml')paragraphs = parsed_article.find_all('p')article_text = ""#检索<p>标记内的文本数据for p in paragraphs:article_text += p.textprint(article_text)
网页内容:
第一个任务是删除文章中所有的引用。这些参考文献均标记在方括号内,使用以下代码将方括号删除并将其替换为空格:
# 删除方括号和多余的空格article_text = re.sub(r'[[0-9]*]', ' ', article_text)article_text = re.sub(r's+', ' ', article_text)
article_text为包含不带括号的文本,该文本为原始文本。article_text不会删除任何其他单词或标点符号,将直接使用它来创建摘要。
执行以下代码以创建加权频率并清理文本:
# 删除特殊字符和数字formatted_article_text = re.sub('[^a-zA-Z]', ' ', article_text )formatted_article_text = re.sub(r's+', ' ', formatted_article_text)
sentence_list = nltk.sent_tokenize(article_text)
stopwords = nltk.corpus.stopwords.words('english')word_frequencies = {}for word in nltk.word_tokenize(formatted_article_text):if word not in stopwords:if word not in word_frequencies.keys():word_frequencies[word] = 1else:word_frequencies[word] += 1
来自nltk库的所有英语停用词都存储在stopwords变量中。遍历所有句子,检查单词是否为停用词。如果该单词不是停用词,需要在word_frequencies词典中检查其是否存在。如果不存在,则将其作为键插入,并将其值设置为1。如果已经存在,则将其计数增加1。
maximum_frequncy = max(word_frequencies.values())for word in word_frequencies.keys():word_frequencies[word] = (word_frequencies[word]/maximum_frequncy)
要找到加权频率,需要将单词的频率除以出现频率最高的单词的频率。
以下为word_frequencies词典的内容:
{'Reinforcement': 0.06944444444444445,'learning': 0.4583333333333333,'RL': 0.013888888888888888,'area': 0.013888888888888888,'machine': 0.041666666666666664,'concerned': 0.027777777777777776,'software': 0.013888888888888888,'agents': 0.013888888888888888,'ought': 0.013888888888888888,'take': 0.027777777777777776,'actions': 0.1527777777777778,'environment': 0.08333333333333333,'order': 0.041666666666666664,'maximize': 0.041666666666666664,'notion': 0.027777777777777776,'cumulative': 0.041666666666666664,…………}
我们已经计算了加权频率。现在,可以通过将每个单词的加权频率相加来计算每个句子的分数:
sentence_scores = {}for sent in sentence_list:for word in nltk.word_tokenize(sent.lower()):if word in word_frequencies.keys():if len(sent.split(' ')) < 30:if sent not in sentence_scores.keys():sentence_scores[sent] = word_frequencies[word]else:sentence_scores[sent] += word_frequencies[word]
已经创建了句子_得分分数字典,该字典将把这些句子存储为键并将它们的出现存储为值。遍历所有句子,标记一个句子中的所有单词。如果单词存在于word_frequences中,并且句子也存在于句子_分数中,则将其计数加1,否则将其作为关键字插入句子_分数中并将其值设置为1。我们不考虑使用更长的句子,因此将句子长度设置为30。
句子_分数评分字典:
{'Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.': 2.347222222222222,'Reinforcement learning differs from supervised learning in not needing labeled input/output pairs to be presented, and in not needing sub-optimal actions to be explicitly corrected.': 1.5555555555555551,'Instead, the focus is on finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).': 0.4305555555555556,
句子分数字典由句子及其分数组成。现在,我们选择使用前N个句子来构成文章的摘要。
在这里,heapq库已被用来挑选前7个句子来总结文章。
import heapqsummary_sentences = heapq.nlargest(7, sentence_scores, key=sentence_scores.get)summary = ' '.join(summary_sentences)print(summary)
输出的文章摘要内容:

END
作者介绍:



指导老师:



