






一· 背景介绍
二· 什么是知识图谱?
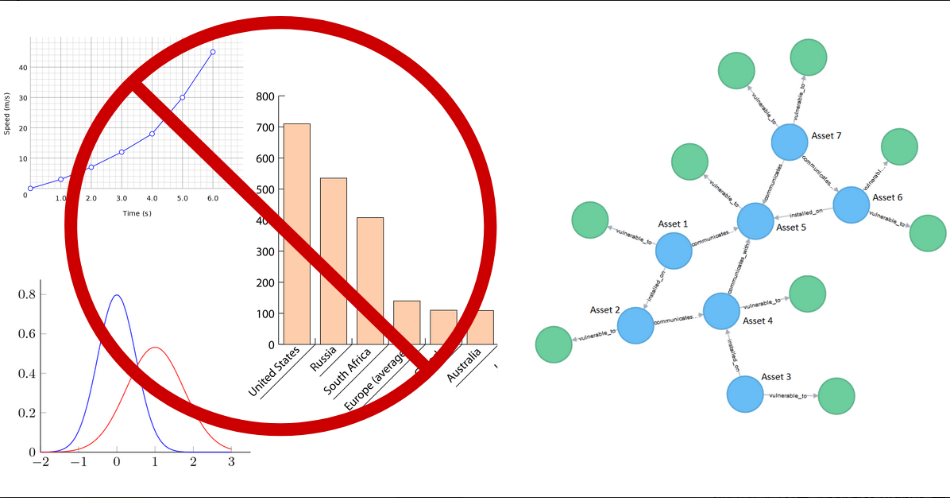
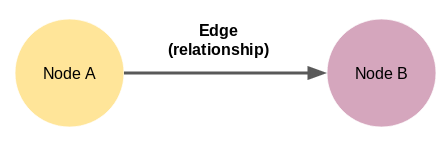
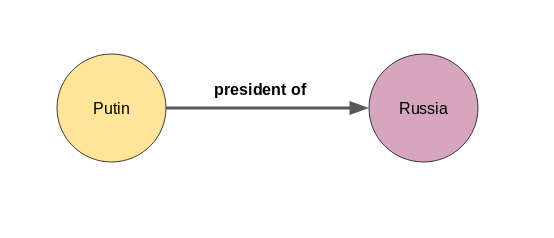
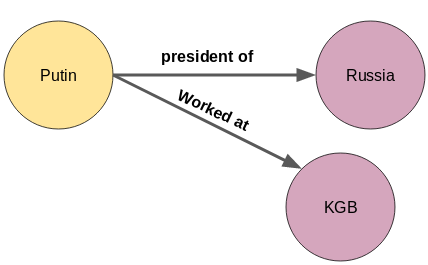
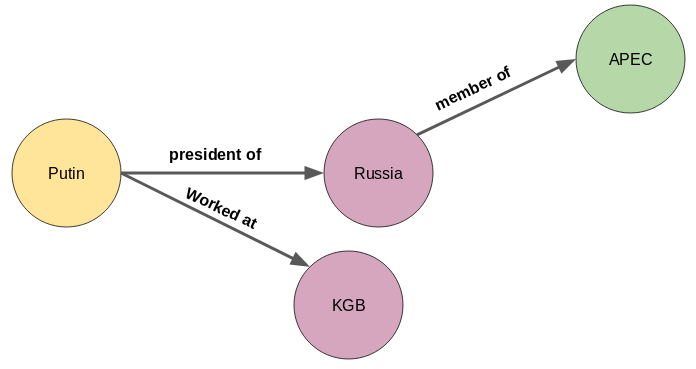
三· 如何在图中表示知识?
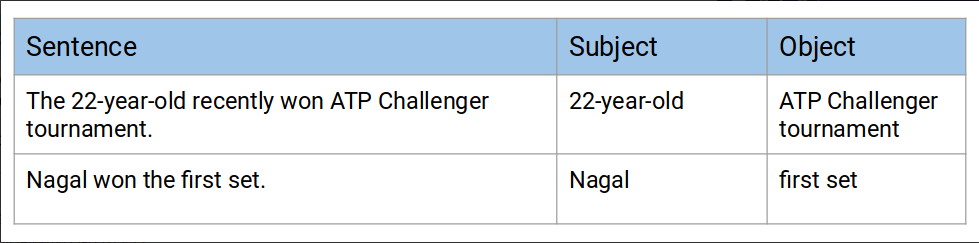
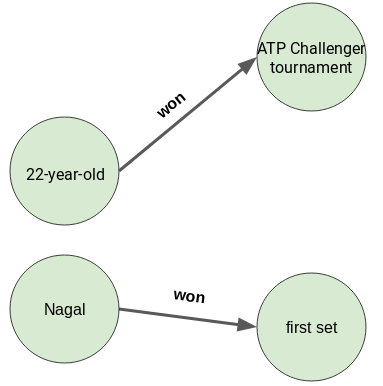
import spacynlp = spacy.load('en_core_web_sm')doc = nlp("The 22-year-old recently won ATP Challenger tournament.")for tok in doc:print(tok.text, "...", tok.dep_)
The … det22-year … amod– … punctold … nsubjrecently … advmodwon … ROOTATP … compoundChallenger … compoundtournament … dobj. … punct
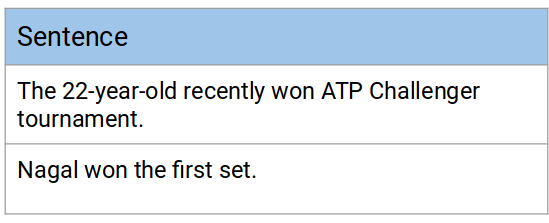
doc = nlp("Nagal won the first set.")for tok in doc:print(tok.text, "...", tok.dep_)
Nagal … nsubjwon … ROOTthe … detfirst … amodset … dobj. … punct
本文作者


指导老师


长按二维码关注我们
微信号 : cucbigdatalabs

欢迎关注沈浩老师
微信号 : artofdata
新浪微博:沈浩老师
文章转载自数艺学苑,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
