






// 介绍 //

// 文本挖掘的优势 //
文本挖掘可以节省时间,并且可以有效地分析非结构化数据,该数据占全球数据的近80%。
文本挖掘可以帮助进行预测分析。 文本挖掘用于汇总文档,并有助于跟踪一段时间内的意见。 文本挖掘技术,用于分析不同业务领域中的问题。 而且,它有助于从文本中提取概念并以更简单的方式呈现它。 使用“文本挖掘”索引的文本可用于预测分析。 可以插入任何词汇表以在他们感兴趣的领域中使用该术语。
例如,文本挖掘可用于使用某些单词或短语来过滤无关的电子邮件。这样的电子邮件将自动进入垃圾邮件。Text Mining还将向用于删除邮件的电子邮件发送警报,其中包含此类令人反感的单词或内容。
// 文本挖掘的应用 //
文本挖掘工具和技术正在迅速渗透从学术界和医疗保健到企业和社交媒体平台的行业。以下是我们周围一些最常见的文本挖掘应用程序:
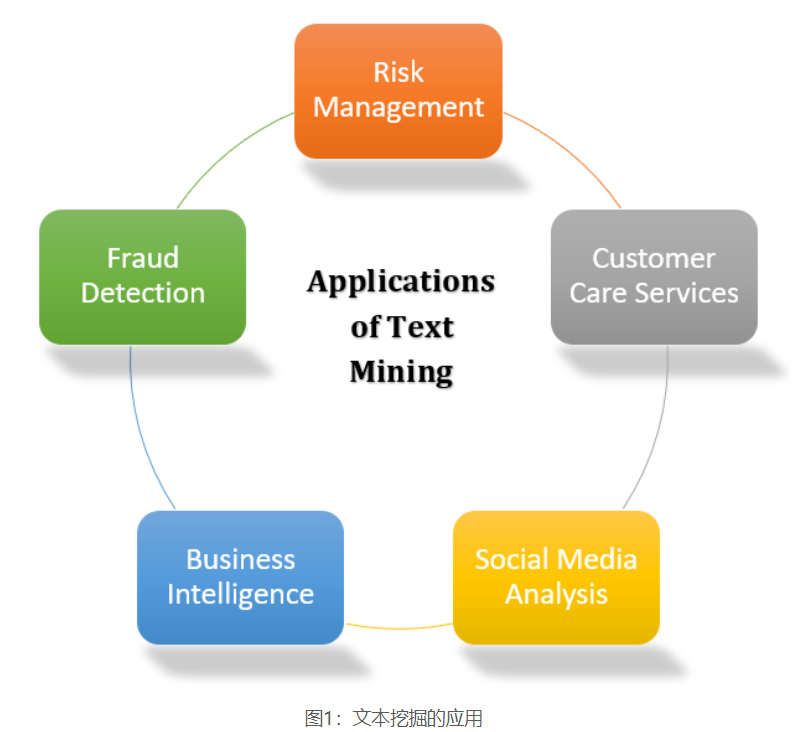
风险管理:商业部门失败的主要原因之一是缺乏适当的风险分析。由于文本挖掘工具和技术可以从成千上万个文本数据源中收集相关信息,并在提取的见解之间建立链接,因此,公司可以在适当的时候访问正确的信息,并提高其减轻潜在风险的能力。
欺诈检测:金融和保险公司主要利用此机会。通过将文本分析的结果与相关的结构化数据相结合,这些公司可以快速处理索赔,并更有效地检测和预防欺诈。
商业智能: 文本挖掘技术除了提供对客户行为和趋势的深刻见解之外,还可以帮助公司分析竞争对手的优势和劣势,从而在市场上获得竞争优势。
社交媒体分析:有许多专门用于分析社交媒体平台性能的文本挖掘工具。这些有助于跟踪和解释新闻,博客,电子邮件等中的文本。此外,文本挖掘工具可以有效地分析社交媒体上的帖子,喜欢和关注者的数量,从而使人们能够了解正在互动的网民的反应他们的品牌和在线内容。这项分析使社交媒体平台能够为其目标受众了解“热门”和“不热门”。
客户服务:诸如自然语言处理(NLP)之类的文本挖掘技术在客户服务领域中变得越来越重要。公司正在购买文本分析软件,以通过访问调查,客户反馈,电话等中的文本数据来改善他们的整体客户体验,旨在大幅缩短公司的响应时间。
// 案例研究-IPL 2020 Tweet分析 //
导入和快速查看数据集
colnames(IPL_Tweets)

接下来,我们将检查数据集中的空值和重复值。
anyNA(IPL_Tweets) #checking for missing values
sum(duplicated(IPL_Tweets)) #search for duplicate values

删除重复条目是有效数据分析的关键步骤。我们的数据集有7个重复值,可以使用以下代码将其删除:
IPL_Tweets=IPL_Tweets[duplicated(IPL_Tweets)!= "TRUE",] #Duplicated entries are removed
尽管我们的数据集中有19个变量,但是为了使事情变得简单,我们仅使用以下命令将tweets和相应的hashtag分别检索到两个分别称为Tweets和Hashtags的文件中。
rownumbers = c(1:nrow(IPL_Tweets))
Tweets=data.frame(doc_id=rownumbers,text=IPL_Tweets$tweet)
Hashtags= data.frame(doc_id=rownumbers, text=IPL_Tweets$hashtags)
让我们来看看我们的推文和标签。
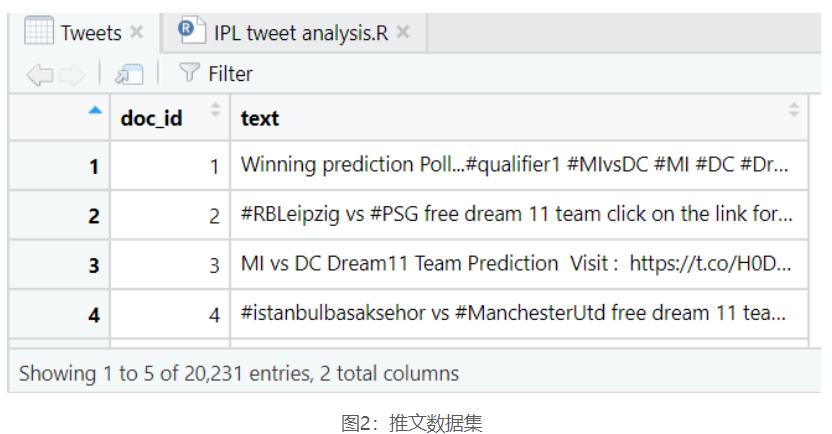
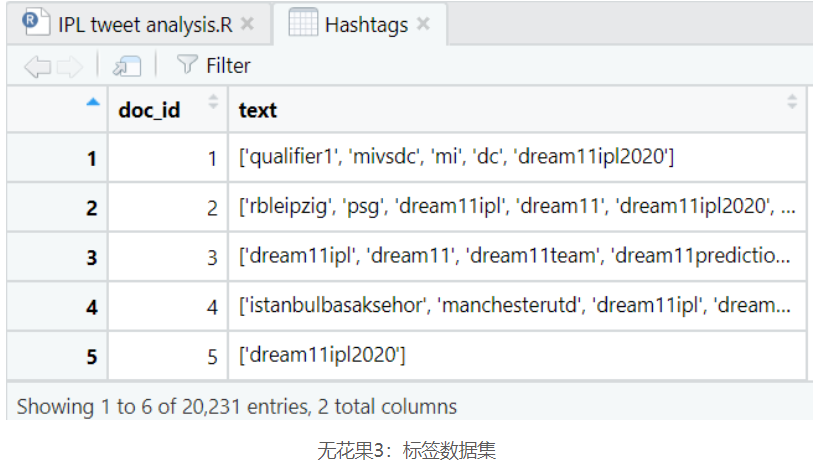
没有任何标签的推文很常见。因此,很明显,Hashtags数据集缺少一些条目,因此,我们还将使用-
Hashtags=Hashtags[Hashtags$text!= "[]",]
在执行完所有步骤之后,我们将获得带有20231个观察值和2列的Tweets和带有19971个观察值和2列的Hashtags。
// 安装和加载R软件包 //
本文的案例研究中使用了以下软件包:
tm用于文本挖掘操作,例如删除数字,特殊字符,标点符号和停用词。
用于词干的snowballc,这是将单词还原为基数或词根形式的过程,例如,词干算法会将单词“ fishing”,“ fished”和“ fisher”减少为词根“ fish”。
wordcloud和wordcloud2用于生成词云图。
RColorBrewer用于各种绘图中的调色板。
# Install
install.packages("tm") # for text mining
install.packages("SnowballC") # for text stemming
install.packages("wordcloud") # word-cloud generator
install.packages("RColorBrewer") # color palettes
install.packages("wordcloud2") # Word-cloud generator
# Load
library("tm")
library("SnowballC")
library("wordcloud")
library("RColorBrewer")
library(wordcloud2
// 清理文本数据 //
接下来要做的是从数据集中构造一个语料库并对其进行处理。在R中,语料库是文本文档的集合,可以在上面应用文本挖掘或NLP例程。
TextCorpus= Corpus(DataframeSource(Tweets)) #Corpus for Tweets
Hashcorpus=Corpus(DataframeSource(Hashtags)) #Corpus for Hashtags
由于数据集是以原始格式获得的,因此,数据集中会有很多不需要的东西,这可能会妨碍我们分析数据的目标。在以下步骤中,我们将清理和处理数据,以便在下一部分中进行分析。
将所有单词转换为小写。 删除标点符号和数字。 删除停用词。 消除多余的空白。 最后,文字发芽。
首先,我们将语料库中的所有单词和句子都转换为小写。也可以使用大写字母,但通常使用小写字母。此步骤减少了将相同的单词视为不同的唯一单词的机会,例如,即使“ Mining”和“ mining”相同,也将它们视为不同的单词,因此在此处将它们保留为小写即可解决。
#Converting to lowercase
TextCorpus1=tm_map(TextCorpus,content_transformer(tolower)) # for Tweets
Hashcorpus1=tm_map(Hashcorpus,content_transformer(tolower)) #for Hashtags
接下来,要从语料库中删除标点符号,我们执行以下代码,否则,在分析过程中将这些标点符号视为单独的文本元素,其结果中将不包含任何情感。同样,也不需要保留数据集中的数字,因此可以执行以下给定的代码从数据中删除数字。
#removing punctuation
TextCorpus2=tm_map(TextCorpus1,content_transformer(removePunctuation))
Hashcorpus2=tm_map(Hashcorpus1,content_transformer(removePunctuation))
#removing number
TextCorpus3=tm_map(TextCorpus2,content_transformer(removeNumbers))
Hashcorpus3=tm_map(Hashcorpus2,content_transformer(removeNumbers))
接下来我们要解决的是停用词的存在。通常,有些单词很常见,但提供的信息很少。这些称为停用词,您可能希望将其从分析中删除。一些常见的英语停用词包括“ I”,“ she'll”,“ the”等。在tm软件包中,共有174个常用英语停用词。
#removing stopwords
TextCorpus4=tm_map(TextCorpus3,content_transformer(removeWords),stopwords())
Hashcorpus4=tm_map(Hashcorpus3,content_transformer(removeWords), stopwords())
下一步是消除语料库中单词之间的多余空白。
#Removing Spaces between words
TextCorpus5 = tm_map (TextCorpus4, stripWhitespace)
HashCorpus5= tm_map(HashCorpus4,stripWhitespace)
最后也很重要的一点是, 文字发芽。这是将单词还原为词根形式的过程。词干处理将单词简化为其通用名称。例如,词干处理将单词“ fishing”,“ fished”和“ fisher”简化为词干“ fish”。
# Text stemming - which reduces words to their root form
TextCorpus6= tm_map(TextCorpus5,stemDocument)
HashCorpus6= tm_map(HashCorpus5,stemDocument)
// 安装和加载R软件包 //
文献长期矩阵或术语的文档矩阵是描述发生的文档集合中术语的频率的数学矩阵。在文档术语矩阵中,行对应于集合中的文档,列对应于术语。
当创建出现在一组文档中的术语数据库时,文档术语矩阵包含与文档相对应的行和与术语相对应的列。例如,如果一个人有以下两个(简短的)文档:
•D1 =“我喜欢数据库”
•D2 =“我讨厌数据库”
那么文档项矩阵将是:
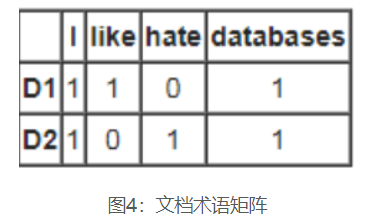
其中显示哪些文档包含哪些术语以及它们出现多少次。在R脚本中,以下代码用于创建文档术语矩阵。
#Building the Term Document Matrix for Tweets
DTM= DocumentTermMatrix(TextCorpus6)
DTM=as.matrix(DTM) #Converting into a double matrix
DTM.totalfreq=colSums(DTM) # calculate the term frequencies
summary(DTM.totalfreq) #summary calculation

摘要统计数据显示,推文的文档术语矩阵包含平均频率为12.87且最大频率为22778的单词。
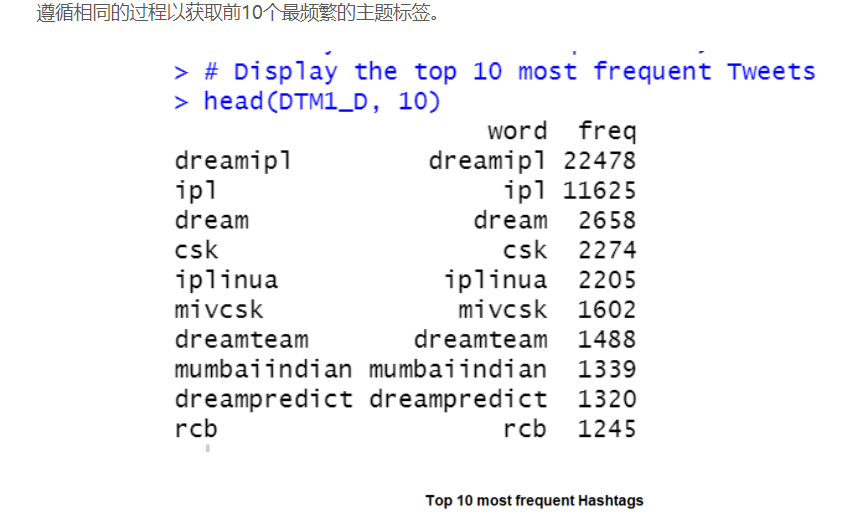
对于标签也遵循类似的方法。
#Building the Term Document Matrix for Hashtags
DTM1= DocumentTermMatrix(HashCorpus6)
DTM1=as.matrix(DTM1)
DTM1.totalfreq=colSums(DTM1)
summary(DTM1.totalfreq)

标签的文档术语矩阵的摘要统计信息具有平均频率为18.33,最大频率为22478的标签。
// 寻找最常用的单词 //
创建文档术语矩阵后,使用条形图绘制前10个最常用的单词是可视化该单词的常用数据的一种很好的基本方法。
因此,准备了解什么是IPL 2020中的#Trending?让我们来看看 !!
在此,通过降低频率值对第一个单词进行排序,然后进行绘制。
#Finding out the most frequent words in Tweets
#Sort by descending value of frequency
DTM_V=sort(DTM.totalfreq,decreasing=TRUE)
DTM_D=data.frame(word = names(DTM_V),freq=DTM_V)
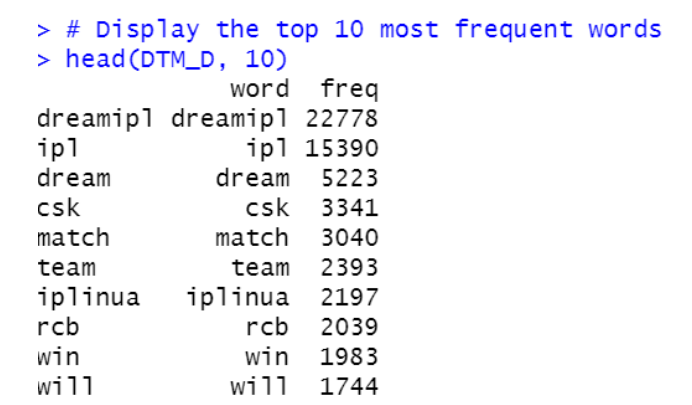
# Display the top 10 most frequent words
head(DTM_D, 10)
# Plot the most frequent words
barplot(DTM_D[1:10,]$freq, las = 2, names.arg = DTM_D[1:10,]$word,
col ="lightgreen", main ="Top 10 most frequent words in Tweets",
ylab = "Word frequencies")
它带有以下输出,如-
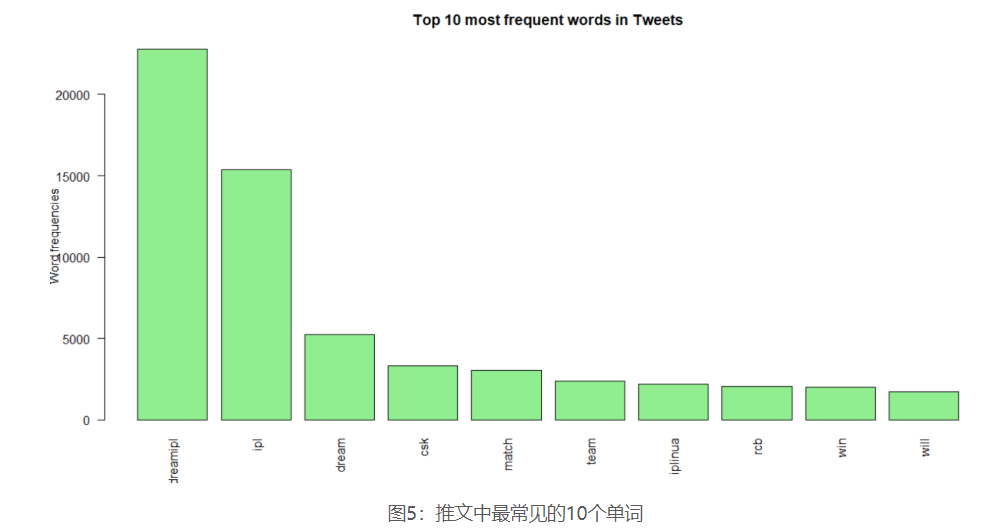
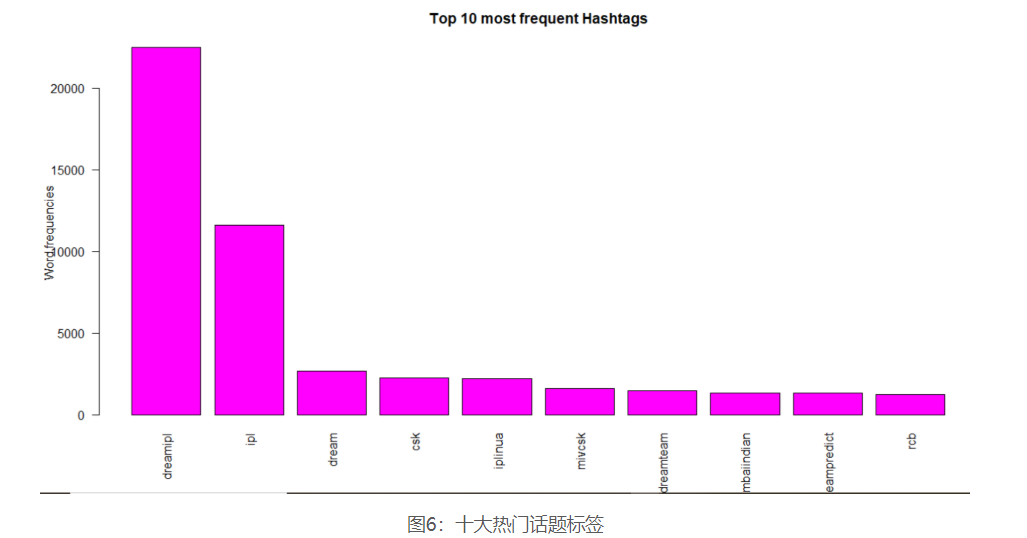
可以从此条形图中解释以下内容:
诸如“ dreamipl”之类的单词在推文中以及在标签中均以“ ipl”,“ dream”和“ csk”紧随其后。 在推文中,单词“ rcb”比主题标签更常见。“ iplinua”则相反。
词云是可视化和分析定性数据的最流行方法之一。单词的特征可以表示为单词云,如下所示:
词云增加了清晰度和简洁性。
最常用的关键字在词云中表现得更好。
词云是一种动态的交流工具。易于理解,易于共享,并且令人印象深刻。
wordcloud(words = colnames(DTM),freq=DTM.totalfreq,min.freq = 500,scale =c(5,0.5),
max.words=200,rot.per=0.30,colors=brewer.pal(n=8,"Dark2"), random.order=F)
上面的代码用于为IPL 2020 Tweets创建词云。
在wordcloud函数中,我们有一些参数,其实现方式简要介绍如下:
单词–获取单词集合以设计wordcloud
频率-这是为了获得条款的频率
Min.freq –最小频率项,将在wordcloud中
最大字数–字云中的最大字数。
比例–最大到最小频率术语的字体大小
颜色–为wordcloud中的单词添加颜色
rot.per –显示为垂直文本(旋转90度)的单词的百分比。我将其设置为0.30(30%),请根据您的喜好随意调整此设置。
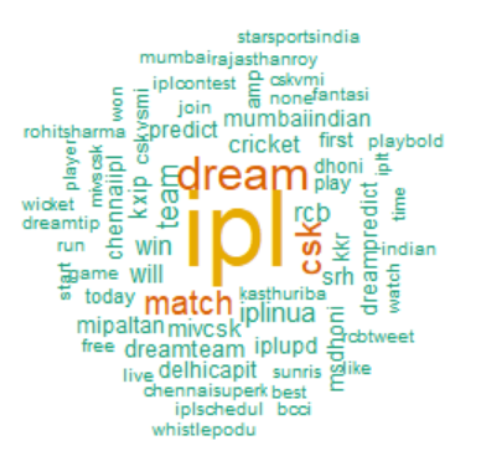
借助“ wordcloud2”包创建另一个wordcloud。与第一个相比,Wordcloud2提供了更多的选择来获得更多创意和色彩丰富的词云。在这里,从“ wordcloud2”创建了IPL 2020推文的wordcloud。
#word cloud 2
wordcloud2(data=DTM_D,size = 3, color = "random-light", backgroundColor = "white")
上面的代码创建了一个新的词云,因为-

最后,我们将计算单词联想。Ť他的技术可以有效地用于分析哪些词最经常发生在协会与调查答复,这有助于看到周围这些词的上下文中出现频率最高的词。
# Find associations
findAssocs(DocumentTermMatrix(TextCorpus6), terms = c("ipl","dream","csk"), corlimit = 0.25)
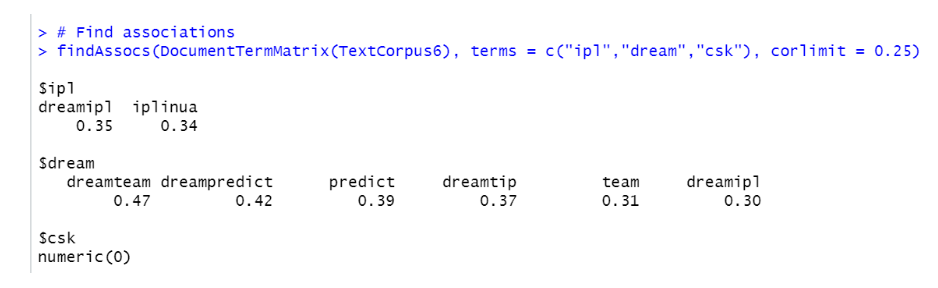
该脚本显示了哪些单词与频率最高的单词“ ipl”,“ dream”和“ csk”相关联,相关性最低,为25%。
// 结论 //
文本挖掘或文本分析是一项蓬勃发展的技术,但分析结果和深度仍因企业而异。本文简要介绍了有关读取文本数据,清除文本数据和转换的信息。它演示了如何创建单词频率表并绘制单词云,以识别文本中出现的突出主题。最后,使用相关性的突出单词联想分析有助于获得围绕突出主题的上下文。
///



- END -
本文作者:


指导老师:


长按关注我们

欢迎关注微信公众号“沈浩老师”

参考来源:
https://www.analyticsvidhya.com/blog/2020/11/text-mining-simplified-ipl-2020-tweet-analysis-with-r/?utm_source=feed&utm_medium=feed-articles&utm_campaign=feed
