




点击蓝字 关注我们



1.前言
马里奥的出道可以追溯到1981年的街机游戏《大金刚》,那时还没有马里奥这个名字,只是单纯地将他设定为一个意大利人角色。
帽子加背带工作服、大鼻子和胡子等特征,离英雄的形象相差甚远。再加上少许肥胖的身材,稍不留神可能就会把我们的英雄马里奥当成在便利店打工的中年大叔。但是形象上所带来的个性和亲切感,却在玩家的心中根深蒂固。时光飞逝,如今笔者已经开始了研究生的生涯,可是每当想起童年时代,满满的都是开心和快乐的回忆。马里奥是我童年回忆里不可磨灭的一部分。
回到主题,那么什么是强化学习呢?
强化学习背后的思想是,代理(AI)将通过与环境进行交互(通过反复试验)并从奖励中获得积极或负面的反馈,从而从中学习。从与环境的互动中学习来自我们的自然经验。
例如,假设将一个小孩子放在一个他从未玩过的电子游戏的前面,将控制器放在他的手中,然后让他独自一人玩耍。小孩儿将通过按右键(动作)与环境互动(视频游戏)。他得到了一个硬币,即+1奖励。肯定的是,他只是了解在这场比赛中他必须拿到硬币。但是随后,他再次按下并触摸了一个敌人,他刚刚死了-1奖励。
通过反复试验与他的环境互动,小孩只知道在这种环境下,他需要获得硬币,但要避开敌人。在没有任何监督的情况下,孩子在玩游戏方面会越来越好。
人类和动物就是通过互动来学习的。强化学习只是从行动中学习的一种计算方法。
本文是强化学习系列的第一篇,本文旨在通过训练马里奥的游戏AI去激发大家对强化学习的兴趣。
2.训练的最终结果
可以看到我们的AI非常熟练地通过了关卡
3.环境配置
3.1 tensorflow-gpu安装
首先安装anaconda, 下载地址
https://www.anaconda.com/download
然后打开anaconda prompt (conda环境的命令行程序),输入
conda create -n tensorflow python=3.6
创建一个独立的tensorflow专用环境,并切换到此环境
activate tensorflow
安装tensorflow-gpu版本
conda install tensorflow-gpu
3.2 游戏环境安装
要训练游戏的话,就需要有游戏的运行环境,常用于AI训练的游戏环境有ViZDoom和gym。
在这里,我们介绍更加通用的游戏运行框架:
FCEUX:http://fceux.com/web/home.html
FCEUX支持所有的FC游戏,也就是说以后所有的童年游戏都可以拿来训练了,想想还是有点小激动的。
FCEUX需要多写一个lua脚本来与python交互,同时针对不同的游戏需要知道游戏内存的分布,从内存中直接获取状态、得分等数据。
进程间交互,本文选择了named pipe,socket也试过性能有点差。因此需要安装pywin32,直接pip安装即可。进程交互主要为:
①,输入控制指令,FC游戏一般只有“上下左右AB”这6个键的组合。
②,间隔一定帧数获取游戏状态和屏幕的rgb数组
本文对应的代码全部放在了
https://github.com/xushsh163/A3CSuperMario_Windows
将刚刚装好的模拟器路径配置到config.py的如下位置
FCEUX_PATH = 'E:\\fceux\\fceux.exe'
当然这是我模拟器安装的位置,大家可以根据自己的情况配置
在这里大家需要注意的是模拟器的路径里不要带有空格,否则会报错
然后大家就可以在anaconda启动刚才的tensorflow环境,切换到工程目录下执行
python A3CTrainer.py
就可以启动训练了
4.AI的成长记录
我从AI训练的不同阶段截取了一些视频来记录这个有趣的过程
一开始AI的随机性会很大,他甚至不知道该往哪个方向走
随着训练的进行会表现的越来越好
在训练过程中我们可以观察到,往往之前明明已经通过好几次的地方,还是时不时就掉坑里。
满怀期待要通关的时候看到这一幕,真的是忍不住嘲笑一番,“你丫也太傻逼了,这也能掉坑里!”
最终训练的成果大家在前文中已经看到了,这里不再放了。
看着AI慢慢成长的过程,就像看着自己的孩子成长一样,开始总觉得不成器,得骂,然后不经意间就发现已超越自己了,不胜唏嘘。
5. 强化学习框架
强化学习(Reinforcement Learning)流程
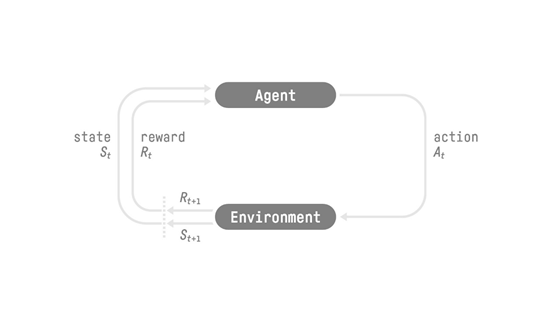
RL过程:状态,动作,奖励和下一个状态的循环
为了理解RL流程,让我们想象一下一个代理(Agent)正在学习玩平台游戏:
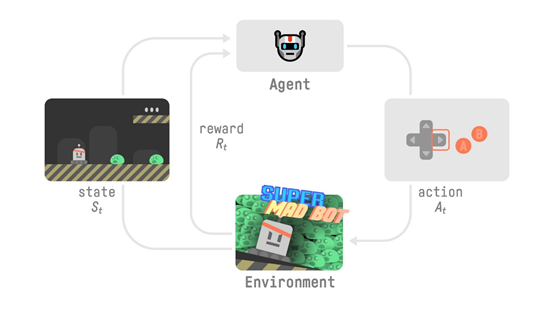
我们的代理从环境收到状态S0-我们收到游戏的第一帧(环境)。
•基于该状态S0,代理将执行操作A0-我们的代理将向右移动。
•环境过渡到新 状态S1-新框架。
•环境向代理人提供了一些奖励R1-我们还没有死(正面奖励+1)。
这个RL循环输出状态,动作和奖励以及下一个状态的序列。
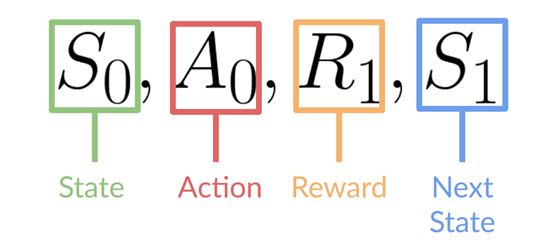
代理的目标是最大化其累积奖励,称为预期回报。
举个例子来说,简单的规则修改可以直接在A3Cwork.py中进行,如
if int(info['is_dead']) == 1:r -= 1episode_buffer.append([s,a,r,s1,d,v[0,0]])
加大对导致死亡的那一次操作的惩罚能够有效的提高训练效果,减少训练时间。
6.总结
希望通过训练游戏类强化学习帮助大家培养兴趣,入门人工智能。游戏AI学习的过程相对比较漫长,的如果你家里有空着的电脑就可以让它跑起来了,等下班回家的时候,它就能给你惊喜了,赶快试试吧。
参考链接:
https://thomassimonini.medium.com/an-introduction-to-deep-reinforcement-learning-17a565999c0c
https://zhuanlan.zhihu.com/p/53907806




指导老师:

