





 将数据与地理信息结合起来的图能使人们印象深刻,人们只要轻轻一瞥,就能看到很多有用的信息,这种直观的数据可视化的表达力令人震惊。
将数据与地理信息结合起来的图能使人们印象深刻,人们只要轻轻一瞥,就能看到很多有用的信息,这种直观的数据可视化的表达力令人震惊。
这类图被称为等值域图(面量图),维基百科把它定义为:主题性的地图,根据地图上显示的统计变量(如人口密度或人均收入)的量度,以阴影或图案显示各地区的信息。
我们假设它们是需要考虑地理边界限制的地图,我们可以使用python的plotly工具包制作等值域图。
01. 绘制幸福指数地图
从一个简单的例子入手,首先需要做的是载入plotly模块:
import plotly as pyimport plotly.graph_objs as go
接下来,创建一个’data‘变量,并将其传递到go.Figure()方法中以生成等值域图。
让我们从一张世界地图开始吧!我们对’data‘变量的定义如下:
data = dict(type = 'choropleth',locations = ['China','Canada','Brazil'],locationmode='country names',colorscale = ['Viridis'],z=[10,20,30])
'data'变量是一个字典。我们把“类型”定义为choropleth。在‘location'中,我们给出不同国家的名称,而在locationmode中,实现一种方法,即通过国家名称指定位置。最后,我们指定要分配给每个国家的颜色比例和值。
我们用以下方法生成图像:
map = go.Figure(data=[data])py.offline.plot(map)
然后获取一张世界地图。此时,当我们将鼠标悬停在一个国家上时,我们就会得到它的名称和指定的值。
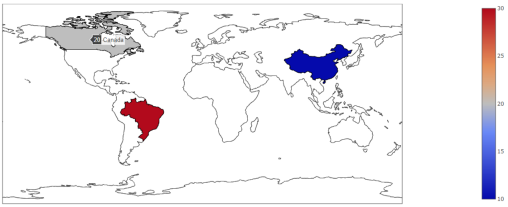
我们可以通过绘制每个国家的幸福指数来让这幅地图变得更有趣,而非任意分配几个国家的幸福指数。根据2017年世界幸福报告的数据集(https://www.kaggle.com/unsdsn/world-happiness),使用下面的代码创建等值域图:
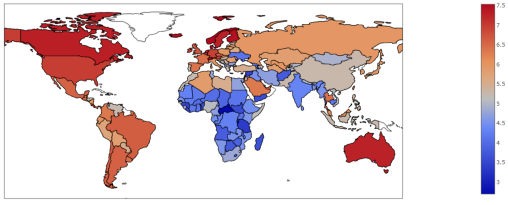
import plotly as pyimport plotly.graph_objs as goimport pandas as pddf = pd.read_csv("2017.csv")data = dict (type = 'choropleth',locations = df['Country'],locationmode='country names',colorscale = ['Viridis'],z=df['Happiness.Score'])map = go.Figure(data=[data])py.offline.plot(map)
生成下图,不需要任何统计分析,我们可以自信地说,一些最幸福的国家在欧洲和北美,而一些最不幸福的国家集中在非洲。这就是地理可视化的力量。
现在让我们对美国做一些细致的数据可视化。
首先更改'data'变量,使locationmode值指定美国各州。接下来我们添加一个‘layout’变量,它允许我们自定义地图的某些方面。在这种情况下,地图聚焦在美国,而非显示整个世界,这是默认的。当然,也可以把世界地图聚焦在亚洲、欧洲、非洲、北美洲或南美洲。
我们将亚利桑那州,加利福尼亚州和佛蒙特州加入location列表,代码如下:
data = dict (type = 'choropleth',locations = ['AZ','CA','VT'],locationmode='USA-states',colorscale = ['Viridis'],z=[10,20,30])lyt = dict(geo=dict(scope='usa'))map = go.Figure(data=[data], layout = lyt)py.offline.plot(map)
得到了这张图:
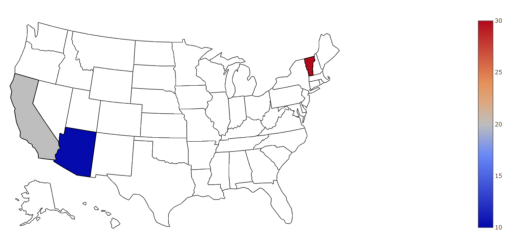
我们现在可以开始做一些有趣的事情了。
02. 绘制蜜蜂数量地图
众所周知,世界上蜜蜂的数量正在迅速减少。这是非常可怕的!因为吃货们将会买不到美味的蜂蜜坚果麦片了!那么,吃货们应该怎么快速了解到蜂蜜坚果麦片?现在,用我们的绘图技术来看看哪个州的蜂群最多吧。
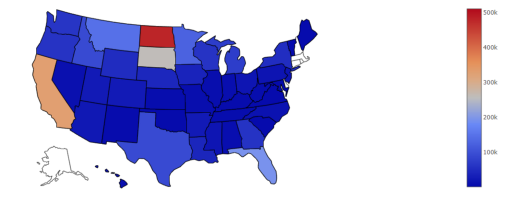
df = pd.read_csv("honeyproduction.csv")data = dict (type = 'choropleth',locations = df['state'],locationmode='USA-states',colorscale = ['Viridis'],z=df['numcol'])lyt = dict(geo=dict(scope='usa'))map = go.Figure(data=[data], layout = lyt)py.offline.plot(map)
从下地图可以看出,北达科他州是美国蜂群最多的州,其次是加州,美国其他地区还有很大的发展空间。我们还缺少阿拉斯加和右上方的几个州的一些数据,但这是这个数据集的限制,所以我们忽略不计。
03. 绘制失业率地图
刚才我们已经谈到了幸福指数和蜂群。现在来谈一个比较沉重的话题——失业。我们再细致一点,不考虑国家或州,我们可以画出每个州的各个区。我们
将从数据集里获得2016年每个区的失业率百分比。(http://raw.githubusercontent.com/plotly/datasets/master/laucnty16.csv)
每个单独的区都可以用一个5位数的FIP号码唯一标识。我们从导入开始,注意这一次我们导入了plot .figure_factory
import plotly as pyimport plotly.figure_factory as ffimport numpy as npimport pandas as pd
接下来我们读取FIP数据和失业率
colorscale=["#f7fbff","#ebf3fb","#deebf7","#d2e3f3","#c6dbef","#b3d2e9","#9ecae1", "#85bcdb","#6baed6","#57a0ce","#4292c6","#3082be","#2171b5","#1361a9","#08519c","#0b4083","#08306b"]endpts = list(np.linspace(1, 12, len(colorscale) - 1))
并将所有这些参数传递给我们的choropleth方法
fig = ff.create_choropleth(fips=fips, values=values, colorscale= colorscale, binning_endpoints=endpts)py.offline.plot(fig)
得到下面的图:
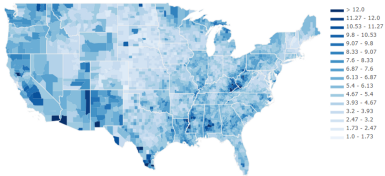
哇哦,好漂亮!
使用这样的图表,我们可以快速地找出失业率较高的地区(用红色圈出)。
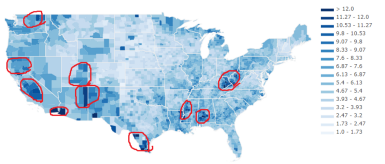
通过这种数据可视化方法,我们可以做出更深的探索,比如,找出这些地区有更多失业率的原因,以及可以采取哪些举措降低失业率等等。
- E N D -
◇本文作者


◇指导老师

长按二维码关注我们喔~

长按二维码关注沈浩老师喔~

