





点击蓝字 · 关注我们

# 概述
K-means聚类是一种非常著名且功能强大的无监督机器学习算法。它用于解决许多复杂的无人监督的机器学习问题。在我们开始之前,让我们看一下我们将要理解的点。
# 目录
介绍
K-means 算法如何工作?
如何选择 K 的值?
Elbow Method.(肘部方法)
Silhouette Method.(轮廓方法)
k -means 的优势。
k - means 的缺点。
介绍
K-means聚类算法简单的定义:K-means 聚类算法尝试以聚类形式对类似项进行分组。组数由 K 表示。
举一个例子。假设你去一家蔬菜店买蔬菜,你会发现,蔬菜会被安排在一组他们的类型。就像所有的胡萝卜都会放在一个地方一样,土豆也会放在一起保存,等等。由此你会发现他们正在形成一个组或集群,其中每个蔬菜都保存在他们形成集群的组中。
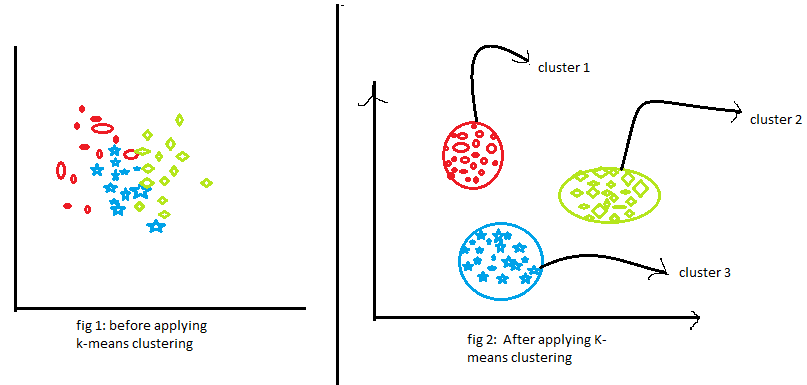
在上面的例子帮助下,我们可以理解这个图中的内容从而了解k-means算法。
如上图所示。第一个图显示了应用 k-means 聚类算法之前的数据。这里所有三个不同的类别的数据都混在了一起。当你在现实世界中看到这样的数据时,你将无法找出不同的类别。
第二个图中显示了应用 K-means 聚类算法后的数据。可以看到,所有的数据被分为三个不同的类别,这些类别也被称为群集
# K-means 聚类算法如何工作?
k-means 群集尝试以群集的形式对类似类型的项进行分组。它查找项之间的相似性,并将它们分组到群集中。主要分三个步骤工作:
选择 k 值。
初始化质心。
选择每个点分组并更新质心。
重复步骤3直到质心坐标收敛。
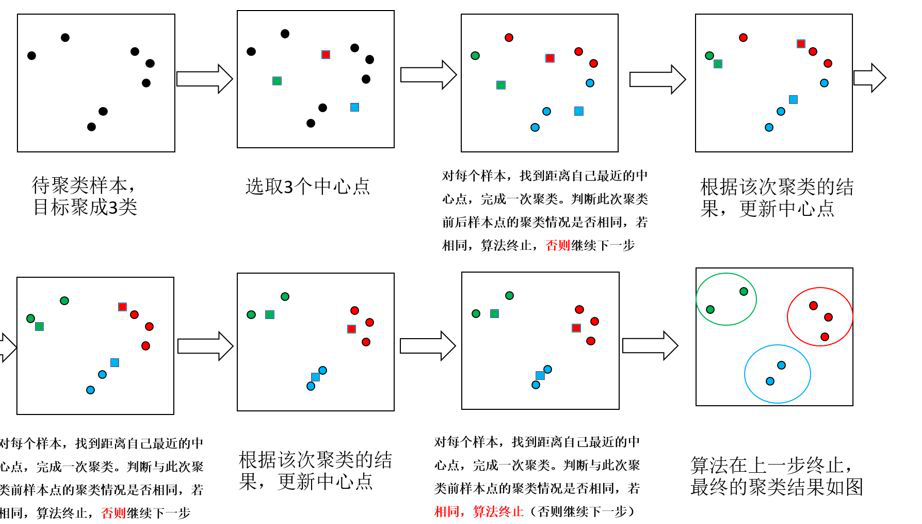
如图所示,其中○点为原来的数据,□为质心点
注:请注意,K-means 聚类使用欧氏距离法来找出点之间的距离。
# 如何选择 K 的值?
k-means聚类算法中最具挑战性的任务之一是选择 k值。正确的 k 值应该是什么?如何选择 k 值?如果随机选择 k 值,则它可能是正确的或错误的。如果选择错误的值,则它将直接影响模型性能。而目前常用的有两种方法确定 k 的右值。
Elbow method(肘部方法)
Silhouette Method(剪影方法)
现在,让我们一个详细地了解这两个概念
肘部方法
肘部方法是最有名的方法之一,你可以通过该方法选择正确的值 k 和提高你的模型性能。我们还可以通过执行超参数调优,以选择 k 的最佳值。让我们看看这种方法是如何工作的。
它是一种经验方法,通过选取k值的范围,计算在每个对应k值下的划分下,每个群集的质点与群集内质点的平方距离。并在其中取最好的值。
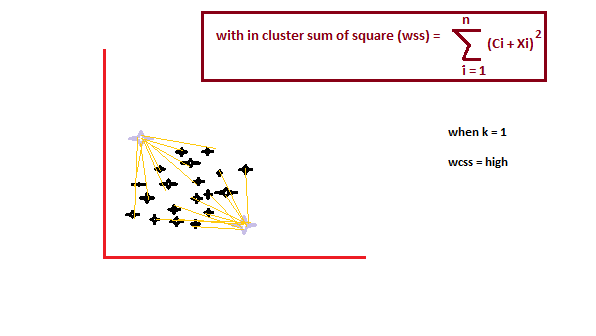
当 k 的值为 1 时,群集内平方距离值将很高。随着 k 的值增加,聚类内平方值的总和将减小。
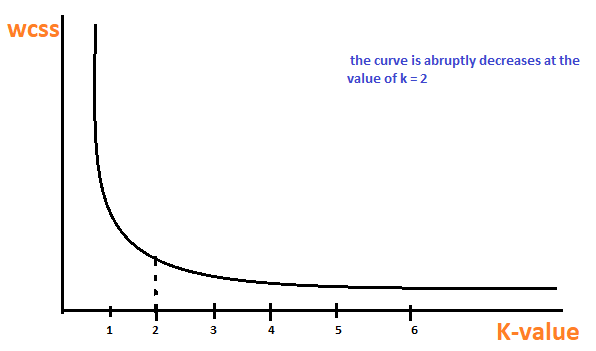
最后,我们以k 值为横坐标,聚类内平方和为纵坐标绘制一个图形,以获得 k 值。我们将仔细检查图表。在某些时候,平方和数值会突然减少(形状类似肘部)。由此得到最优的k值。如下图所示
剪影方法
剪影方法与上一种不同。该方法同样选取 k 值的范围,得到对应k值的划分后绘制剪影图。它计算每个点的轮廓系数,首先计算某个聚类内点的平均距离a(i)和点到下一个最近聚类的平均距离b(i)。

注意:a (i)值正常情况下小于 b (i) 值,最好 ai<<bi。
得到a(i)和b(i) 的值后。我们将使用以下公式计算轮廓系数。
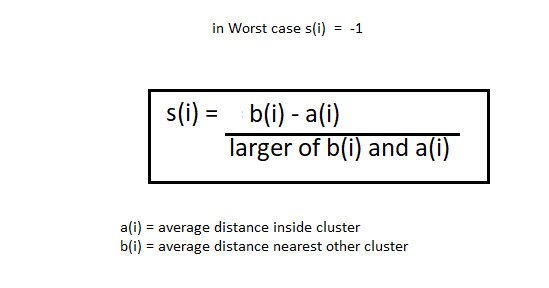
现在,我们可以计算聚类中所有点的轮廓系数并绘制剪影图。此绘图还有助于检测异常值。剪影的值介于 -1 到 1 之间。
请注意,对于与 -1 相等的剪影,情况最糟。
观察绘图并检查哪个 k 值更接近 1。
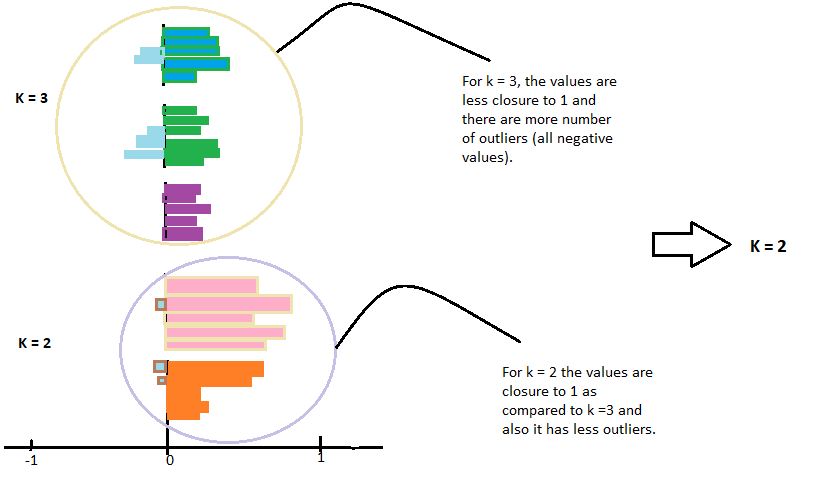
比较时可检查负值较少的绘图,这代表着异常值较少。然后选择 k 的值进行调整。
# K-means算法的优势
实现非常简单。
它可扩展到庞大的数据集,也可以更快地扩展到大型数据集。
可经常适应新的例子。
对于不同形状和大小的聚类的泛化。
# K-means算法的缺点
它对于异常值很敏感。
手动选择 k 值是一项艰巨的工作。
随着维度数量的增加,其可伸缩性会降低。
本文作者




扫码关注我们
微信号|cucbigdatalabs


扫二维码

关注沈浩老师
原文链接:
https://www.analyticsvidhya.com/blog/2020/10/a-simple-explanation-of-k-means-clustering/
