







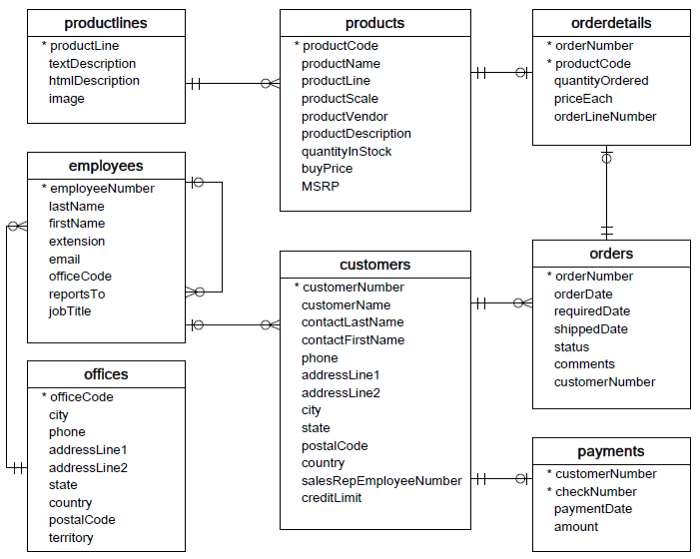
SQLite库含有一个高效的关系数据库管理系统(RDBMS),并且SQLite3升级了更多的功能,值得一提的是SQLite3是自包含的、无服务器的、零配置的。
SQLite3操作
本文将演示安装并加载必要的库,连接到数据库,进行相应的查询操作。下面使用的一些示例来自LucasMcL/]5-sql querys 02 chinook。如果您使用的是Python3以上的版本,则可能不需要安装。
安装数据库:
pip install pysqlite3
数据库操作:
1#导入数据库
2import sqlite3
3#连接数据库
4conn = sqlite3.connect('data/Chinook_Sqlite.sqlite')
5#实例化对象
6cur = conn.cursor()
现在我们已经连接到数据库,我们可以查询其中的数据。使用cursor对象执行查询然后只返回cursor对象。为了查看结果,我们需要在之后使用fetchaii()方法。使用select语句和where子句执行查询,以查看数据库中有多少表。where子句通常按某些条件筛选查询结果。在下面的示例中,我使用它返回数据库中“table”类型的对象的名称。每个SQLite数据库都有一个包含关于模式的信息的SQLITEHMART表。以分号结束查询表示语句结束。如果希望查询返回表中的所有记录,请使用星号(*)代替对象名称。
1#代码块:
2cur.execute("SELECT name FROM sqlite_master WHERE type='table';")
3print(cur.fetchall())
4#输出结果
5[('Album',), ('Artist',), ('Customer',), ('Employee',), ('Genre',), ('Invoice',), ('InvoiceLine',), ('MediaType',), ('Playlist',), ('PlaylistTrack',), ('Track',)]
此查询语句的输出返回数据库中的所有表。假设我们需要关于数据库中每个表的更详细的信息,pragma命令将会返回这些信息。
1#代码块:
2cur.execute("PRAGMA table_info(Employee)")
3info = cur.fetchall()
4print(*info, sep = "\n")
5#输出:
6(0, 'EmployeeId', 'INTEGER', 1, None, 1)
7(1, 'LastName', 'NVARCHAR(20)', 1, None, 0)
8(2, 'FirstName', 'NVARCHAR(20)', 1, None, 0)
9(3, 'Title', 'NVARCHAR(30)', 0, None, 0)
10(4, 'ReportsTo', 'INTEGER', 0, None, 0)
11(5, 'BirthDate', 'DATETIME', 0, None, 0)
12(6, 'HireDate', 'DATETIME', 0, None, 0)
13(7, 'Address', 'NVARCHAR(70)', 0, None, 0)
14(8, 'City', 'NVARCHAR(40)', 0, None, 0)
15(9, 'State', 'NVARCHAR(40)', 0, None, 0)
16(10, 'Country', 'NVARCHAR(40)', 0, None, 0)
17(11, 'PostalCode', 'NVARCHAR(10)', 0, None, 0)
18(12, 'Phone', 'NVARCHAR(24)', 0, None, 0)
19(13, 'Fax', 'NVARCHAR(24)', 0, None, 0)
20(14, 'Email', 'NVARCHAR(60)', 0, None, 0)
此查询语句的输出返回Employee表的列ID、列名、列类型、非空值、默认值和主键。
如果希望输出的格式可以操作或处理数据,那么使用Pandas语句将查询结果包装到数据帧中从而提升效率。.description属性返回包含以下内容的列描述:
nametype_codedisplay_sizeinternal_sizeprecisionscalenull_ok
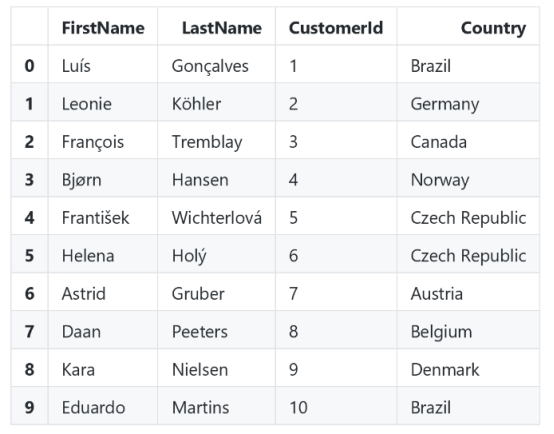
使用description属性,我们可以使用list comprehension获取每个列的名称。下面是一个查询语句,选择不在美国的客户、全名、id和国家/地区,结果用数据框包装起来。
1import pandas as pd
2cur.execute("""
3 SELECT FirstName, LastName, CustomerId, Country
4 FROM customer
5 WHERE country != 'USA'
6""")
7df = pd.DataFrame(cur.fetchall())
8df.columns = [x[0] for x in cur.description]
9df.head(10)
输出结果:
使用SQL进行筛选和排序
SQL查询只允许检索与任务相关的数据。我将介绍一些查询修饰符, order by是第一个。这个修饰符允许我们根据特定的特性对select语句的结果进行排序。
limit子句将输出限制为一定数量的结果。between运算符允许我们通过过滤设置值之间的结果来进一步选择特定数据。这在查询特定年龄组、时间范围等时非常有用。
下面我执行一个查询,从track表中选择数据,其中track的长度(毫秒)在205205和300000之间。结果按轨迹的毫秒数按降序排序,因此具有较长轨迹的轨迹将位于顶部。我还将此查询限制为仅输出10个结果。
1#代码块
2cur.execute("""
3 SELECT Name, AlbumId, TrackId, Milliseconds
4 FROM track
5 WHERE Milliseconds BETWEEN 205205 AND 300000
6 ORDER BY Milliseconds Desc
7 LIMIT 10
8""")
9info = cur.fetchall()
10print(*info, sep = "\n")
11
12#输出:
13('Breathe', 212, 2613, 299781)
14('Queixa', 23, 524, 299676)
15('Getaway Car', 10, 97, 299598)
16('Winterlong', 201, 2485, 299389)
17('Cherub Rock', 202, 2491, 299389)
18('Sonata for Solo Violin: IV: Presto', 325, 3480, 299350)
19('Linha Do Equador', 21, 218, 299337)
20('Who Are You (Single Edit Version)', 221, 2749, 299232)
21('Garden', 181, 2201, 299154)
22('The Spirit Of Radio', 196, 2406, 299154)
聚合函数
这些SQL函数在执行统计分析时非常有用。我们可以得到一列中的平均值、最小值和最大值,以及值的总和。使用count函数返回满足特定条件的记录数。 groupby函数将返回按集合列分组的结果。例如,按性别、品种或国籍对结果进行分组。
下面是每个国家的总销售额查询示例,结果按每个国家分组。我还将总数的总和称为“总销售额”,以便按每个国家的总销售额对结果进行分组。
1#代码块:
2cur.execute('''
3 SELECT i.billingcountry, sum(total) as 'TotalSales'
4 FROM invoice AS i
5 GROUP BY billingcountry
6 ORDER BY totalsales DESC
7 '''
8)
9info = cur.fetchall()
10print(*info, sep = "\n")
11
12#输出:
13('USA', 523.0600000000003)
14('Canada', 303.9599999999999)
15('France', 195.09999999999994)
16('Brazil', 190.09999999999997)
17('Germany', 156.48)
18('United Kingdom', 112.85999999999999)
19('Czech Republic', 90.24000000000001)
20('Portugal', 77.23999999999998)
21('India', 75.25999999999999)
22('Chile', 46.62)
23('Hungary', 45.62)
24('Ireland', 45.62)
25('Austria', 42.62)
26('Finland', 41.620000000000005)
27('Netherlands', 40.62)
28('Norway', 39.62)
29('Sweden', 38.620000000000005)
30('Argentina', 37.620000000000005)
31('Australia', 37.620000000000005)
32('Denmark', 37.620000000000005)
33('Italy', 37.620000000000005)
34('Poland', 37.620000000000005)
35('Belgium', 37.62)
36('Spain', 37.62)
如果您想进一步了解SQLaggregators和select语句,zetcode上提供了一些非常有用的示例。
结论
SQL是一个很有价值的工具,可以在数据库中筛选出我们需要的特定信息。结合SQL与Pandas可以让你操作的数据成为任何所需要的目标格式。本教程只触及了简单的SQL使用场景,如果需更进一步学习,请通过using和on语句来进一步学习join操作。



指导老师:


长按二维码关注我们

欢迎关注公众号:沈浩老师

原文链接:
https://medium.com/@jwong853/sql-in-data-science-af0b4492bcd
