






手写数字识别是一个十分具有挑战性的问题。在实际生活中,对手写文本或数字进行识别分类是一个很重要的功能,数字识别的应用包括邮政分拣、银行支票处理、表单数据输入等领域。
走进机器学习
尽管深度学习算法在识别手写数字这一任务上使用CNN(卷积神经网络)已经取得了突破性的进展,但是我们依然需要学习掌握sklearn这个工具的分类算法,特别是针对这种非结构化的数据。本文旨在通过一个简单的案例来演示如何使用Scikit-Learn识别手写数字,抛砖引玉来引导读者们进入机器学习的知识殿堂。
sklearn简介
Sklearn (全称 Scikit-Learn) 是基于 Python 语言的机器学习工具。它建立在 NumPy, SciPy, Pandas 和 Matplotlib 之上,里面的 API 的设计非常好,所有对象的接口简单,很适合新手上路。
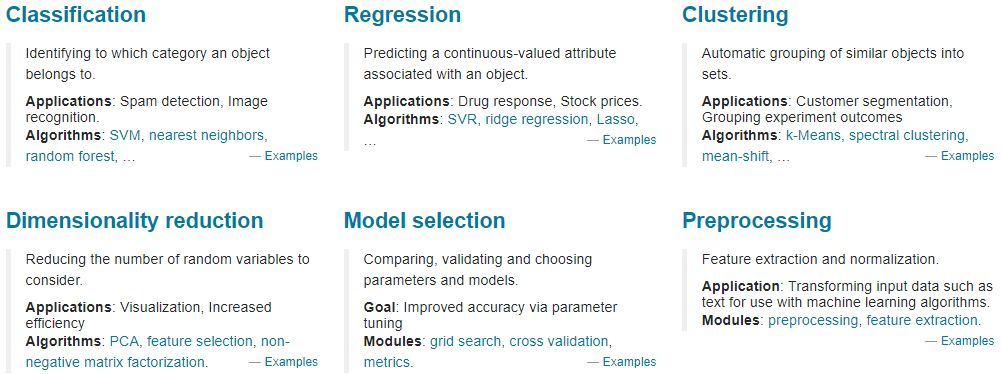
在 Sklearn 里面有六大任务模块:分别是分类、回归、聚类、降维、模型选择和预处理
分类:识别某个对象属于哪个类别,常用的算法有:SVM(支持向量机)、nearest neighbors(最近邻)、random forest(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:SVR(支持向量机)、 ridge regression(岭回归)、Lasso,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:k-Means、spectral clustering、mean-shift,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:PCA(主成分分析)、feature selection(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:grid search(网格搜索)、cross validation(交叉验证)、 metrics(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:preprocessing,feature extraction,常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
安装SKlearn
Scikit-learn需要:
Python(> = 2.7或> = 3.4),
NumPy(> = 1.8.2),
SciPy(> = 0.13.3)。
【注意】Scikit-learn 0.20是支持Python 2.7和Python 3.4的最后一个版本。Scikit-learn 0.21将需要Python 3.5或更高版本。
如果你已经安装了numpy和scipy,那么安装scikit-learn的最简单方法就是使用 pip
或者conda
1pip install -U scikit-learn
2conda install scikit-learn
如果你尚未安装NumPy或SciPy,你也可以使用conda或pip安装它们。使用pip时,请确保使用binary wheels,并且不会从源头重新编译NumPy和SciPy,这可能在使用特定配置的操作系统和硬件(例如Raspberry Pi上的Linux)时发生。从源代码构建numpy和scipy可能很复杂(特别是在Windows上),需要仔细配置以确保它们与线性代数例程的优化实现相关联。为了方便,我们可以使用如下所述的第三方发行版本。
数据集介绍
Digits数据集包含1797张8x8像素的图像,每个图像都是一个灰色的手写数字。

获取方法
1from sklearn import datasets
2digits = datasets.load_digits()
算法选择
sklearn 实现了很多算法,面对这么多的算法,如何去选择呢?其实选择的主要考虑的就是需要解决的问题以及数据量的大小。sklearn官方提供了一个选择算法的引导图。这里提供翻译好的中文版本,供大家参考:

在本文中,我们将使用Scikit-Learn的数字数据集正确识别手写的单个数字(即0-9),这是一个Python库,其中包含许多有用的算法,我们将在这些算法上进行修改与实现,并使用Logistic回归 的分类器来完成手写数字的识别,并预测一些未知的手写数字的值。
Scikit-Learn库的四步建模模式:
导入所需要的使用的模型。
制作模型实例。
依据数据训练模型并存储从数据中所学习到的信息。
使用训练过程中学习到的模型信息来预测识别新数据的结果。
准备工作
首先为模型导入必要的库并加载数字数据集,导入scikit-learn库的svm模块。我们可以创建一个SVC类型的估算器,然后选择一个初始设置,分配值C和gamma通用值,这些值可以在后续的分析过程中进行对应的调整。
1from sklearn import svm
2svc = svm.SVC(gamma=0.001, C=100)
3
4import numpy as np
5import pandas as pd
6import matplotlib.pyplot as plt
7from sklearn import datasets
8digits = datasets.load_digits()
9# 导入库并加载数据集数据展示
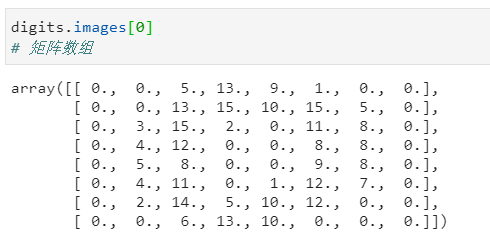
手写数字的图像包含在digits.images数组中。此数组的每个元素都是一副图像,该图像由一个8x8数值矩阵标识,矩阵中的数值代表从0(白色)到15(黑色)的灰度。
1digits.images[0]
2# 矩阵数组
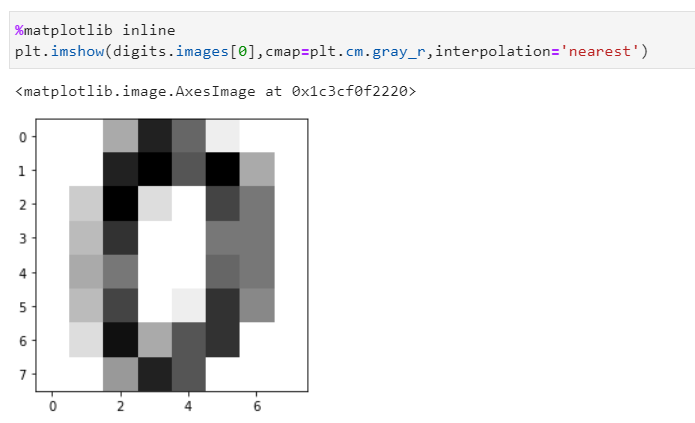
我们的数据集以数字存储。通过以下命令可以获取数字的灰度图像。
1%matplotlib inline
2plt.imshow(digits.images[0],cmap=plt.cm.gray_r,interpolation='nearest')
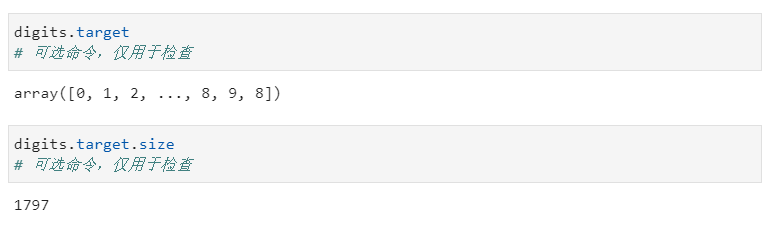
由图像(即目标)表示的数值包含在digit.targets数组中。数据集也是由1797张图像组成的训练集,可以通过以下命令查看。
1digits.target
2digits.target.size
数据分组
该数据集包含1797个元素,我们选择将前1791个数据视为训练集,并使用后6个数据作为验证集来进行验证。我们通过使用matplotlib库可以详细看到这六位数字。
1import matplotlib.pyplot as plt
2%matplotlib inline
3plt.subplot(321)
4plt.imshow(digits.images[1791],cmap=plt.cm.gray_r,interpolation='nearest')
5plt.subplot(322)
6plt.imshow(digits.images[1792],cmap=plt.cm.gray_r,interpolation='nearest')
7plt.subplot(323)
8plt.imshow(digits.images[1793],cmap=plt.cm.gray_r,interpolation='nearest')
9plt.subplot(324)
10plt.imshow(digits.images[1794],cmap=plt.cm.gray_r,interpolation='nearest')
11plt.subplot(325)
12plt.imshow(digits.images[1795],cmap=plt.cm.gray_r,interpolation='nearest')
13plt.subplot(326)
14plt.imshow(digits.images[1796],cmap=plt.cm.gray_r,interpolation='nearest')

SVC估算
接下来开始训练我们先前定义的SVC估算器。
1svc.fit(digits.data[1:1790],digits.target[1:1790])
2# 拟合模型
然后测试估计器,使其识别验证数据集的后六位数字。
1svc.predict(digits.data[1791:1796])
2# 预测模型

如我们所见,svc估算器已完成学习并可识别大部分手写数字,并正确预估了六位数字中的五位。
使用Logistic算法训练模型
logistic算法简介
Logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,虽然名字中有“回归”二字,但实际却是一种分类学习方法。对于回归这个概念,简单的说,回归就是用一条线对N个数据点进行一个拟合,这个拟合的过程就叫做回归。Logistic回归分类算法就是对数据集建立回归公式,以此进行分类。
Logistic回归优点:
1、实现简单;
2、分类时计算量非常小,速度很快,存储资源低;
缺点:
1、容易欠拟合,一般准确度不太高
2、只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),但必须线性可分。
接下来让我们来看看Scikit-Learn四步建模模式。
我们需要将数据集分为训练集和测试集,以确保在训练模型后能够较好的预测识别新数据。
1from sklearn.model_selection import train_test_split
2x_train,x_test,y_train,y_test = train_test_split(digits.data,digits.target,test_size=0.25,random_state=0)
3# 将数据集分为训练和测试集
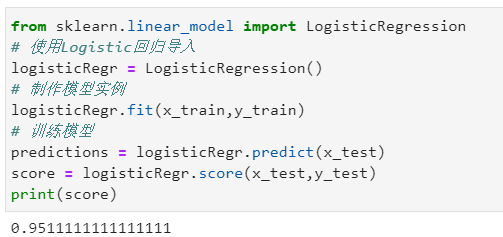
步骤一:导入我们所需要使用的模型
from sklearn.linear_model import LogisticRegression
# 使用Logistic回归导入步骤二:制作模型的实例
logisticRegr = LogisticRegression()
# 制作模型实例步骤三:训练模型
logisticRegr.fit(x_train,y_train)
# 训练模型步骤四:验证预测的新数据并评估该模型的性能
predictions = logisticRegr.predict(x_test)
score = logisticRegr.score(x_test,y_test)
print(score)
评估准确性
什么是混淆矩阵?混淆矩阵是一个误差矩阵,通常我们可以通过混淆矩阵来评定监督学习算法的性能。在监督学习中混淆矩阵为方阵,方阵的大小通常为一个(真实值,预测值)或者(预测值,真实值),所以通过混淆矩阵我们更清晰的看出,预测集与真实集中混合的一部分。
混淆矩阵可以清晰的反映出真实值与预测值相互吻合的部分,也可以反映出与预测值不吻合的部分,如下图所示。
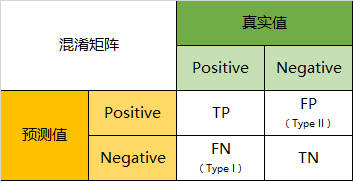
实现预测值与真实值在相同特征下的比较,如果同时成立则放入相对应的矩阵位置,如果不成立则放入不相匹配的矩阵位置,
将真实值与预测值相互匹配与不匹配项放入矩阵中,我们称这个矩阵为混淆矩阵。
使用sklearn绘制混淆矩阵
1import matplotlib.pyplot as plt
2import seaborn as sns
3from sklearn import metrics
4cm = metrics.confusion_matrix(y_test,predictions)
5plt.figure(figsize=(9,9))
6sns.heatmap(cm,annot=True,fmt=".3f",linewidths=.5,square=True,cmap='RdPu',linecolor="pink")
7plt.ylabel('Actual label')
8plt.xlabel('Predicted label')
9all_sample_title='Accuracy score:{0}'.format(score)
10plt.title(all_sample_title,size=15)
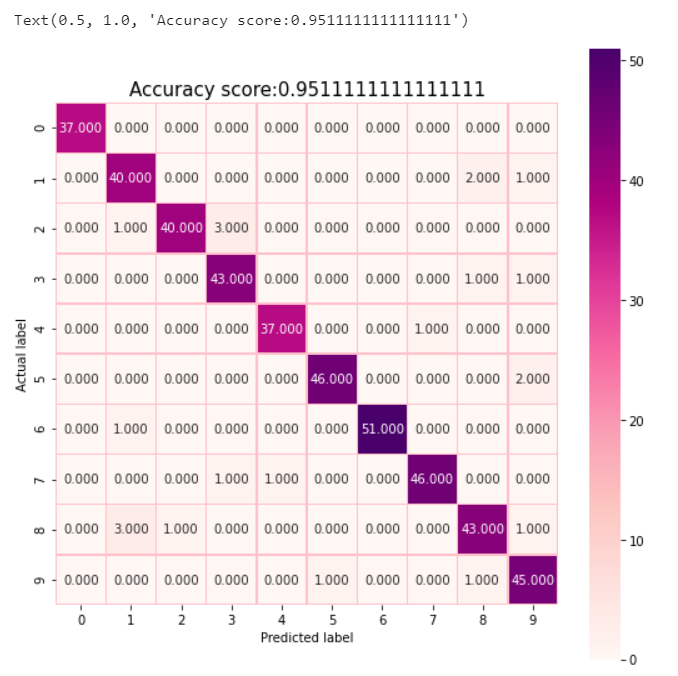
矩阵的第九行数据表示 有关数字8的数据有48个,有3个被误判为1,1个被误判为2,1个被误判为9。从整体观察混淆矩阵,效果还是不错的。
从本文中,我们可以学习如何轻松导入数据集、使用Scikit-Learn构建模型、训练模型、使用模型进行预测以及找到我们识别数字的准确性。
在本案例中,我们可以清楚的看到该模型在95%的情况下识别准确度为100%,因此,该模型在95%的情况下都可以正常进行运作。
本文作者



指导老师

长按二维码关注我们

欢迎关注微信公众号
“沈浩老师“

原文链接:
https://medium.com/@navyashree.raghupatro/recognizing-handwritten-digits-with-scikit-learn-8d248dc01b6d
