在任何数据库中存储生僻字,其实都和一个因素有关:字符集。
能否正常存储一个字符,首先是要看要存储的字符在数据库的当前字符集中是否能够表达。如果包含在数据库字符集中,则能够正常存储。如果字符集不支持,可以看国家字符集是否支持,通常这两者可以解决大多数问题。
但是注意,很多时候,本应正常存储的字符,可能在写入过程中,因为环境问题转换错误,丢失了正确的字符,而出现乱码。
标题中出现的生僻字读音:㼆 yíng ,㱔 suǒ,䶮 yǎn
- 乱码的情况
我们首先举一个例子:本应正常存储的字符,因为环境问题而出现乱码。
示范数据库的字符集:
SQL> select name,value$ from sys.props$ where name like '%CHARACTERSET';
NAME
--------------------------------------------------------------------------------
VALUE$
--------------------------------------------------------------------------------
NLS_NCHAR_CHARACTERSET
AL16UTF16
NLS_CHARACTERSET
AL32UTF8创建测试表,插入一个汉字。
SQL> create table mogdb (cname varchar2(20));
Table created.
SQL> insert into mogdb values('㼆');
1 row created.
SQL> select * from mogdb;
CNAME
--------------------
???
注意,此时的查询结果显示乱码,以问号形式输出。我们可以通过dump函数查看底层存储的真实编码:
SQL> select dump(cname,1016) from mogdb;
DUMP(CNAME,1016)
--------------------------------------------------------------------------------
Typ=1 Len=9 CharacterSet=AL32UTF8: ef,bf,bd,ef,bf,bd,ef,bf,bd以上输出是三个:ef bf bd 编码
- 特殊的EFBFBD 编码
这个输出往往让人费解,其根本原因是 Unicode 中定义了一个特殊字符「�」即 U+FFFD,用来表示无法显示的字符或是无法解析的数据,也被称作 Replacement Character。
维基百科对它的解释是:
The replacement character (often a black diamond with a white question mark or an empty square box) is a symbol found in the Unicode standard at code point U+FFFD in the Specials table. It is used to indicate problems when a system is unable to render a stream of data to a correct symbol.
Unicode 中的特殊字符 U+FFFD,对应 UTF-8 编码是 0xEF 0xBF 0xBD,就是以上我们看到的 EF BF BD。这个 EFBFBD 序列,如果试图以 GBK 解码,就会变成三个汉字:「锟斤拷」,即 EFBF BDEF BFBD更加使人困惑。
总之各种字符异常就是在这样的不同字符集转换中出现的。
此处 EF BF BD 的出现,是在 插入数据 时,因为转换丢失了正确的字符编码。这部分内容可以参考我以前写的文章。
让我们来修正这个问题。
- 设置客户端字符集
在这个测试中,SQL*Plus成为了一个客户端工具,用以连接数据库,需要对它的环境字符集进行设置。
[oracle12c@enmotech ~]$ export NLS_LANG=AMERICAN_AMERICA.UTF8
[oracle12c@enmotech ~]$ sqlplus / as sysdba
SQL*Plus: Release 12.2.0.1.0 Production on Fri Oct 8 16:09:13 2021
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
SQL> insert into mogdb values('㼆');
1 row created.
SQL> select * from mogdb;
CNAME
------------------------------------------------------------
���
㼆
SQL> select dump(cname,1016) from mogdb;
DUMP(CNAME,1016)
--------------------------------------------------------------------------------
Typ=1 Len=9 CharacterSet=AL32UTF8: ef,bf,bd,ef,bf,bd,ef,bf,bd
Typ=1 Len=3 CharacterSet=AL32UTF8: e3,bc,86
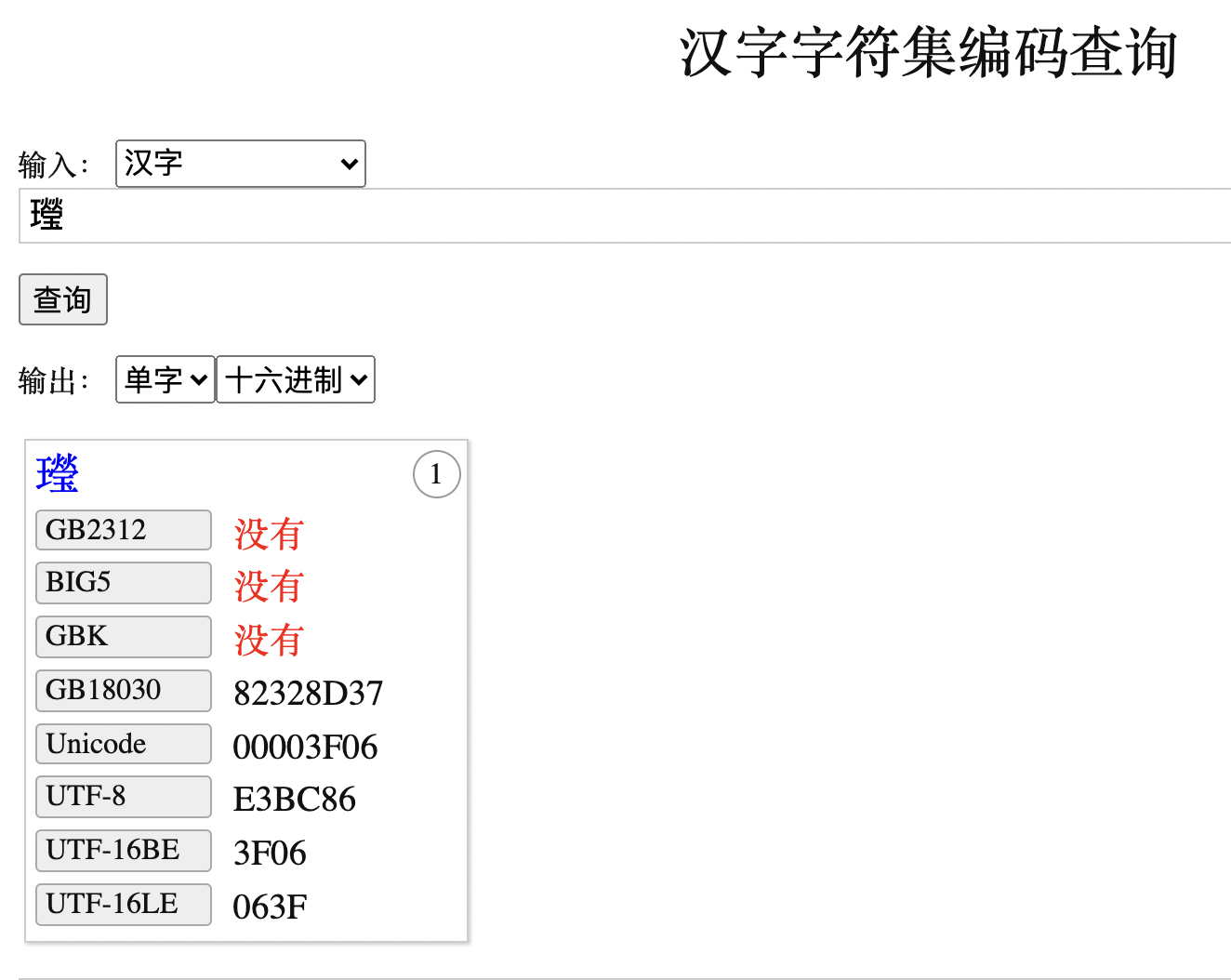
注意,此时这个汉字 ”㼆“被正确存入数据库中,E3 BC 86 正是其在 UTF8 字符集下的正确编码。查看字符编码的网站:https://www.qqxiuzi.cn/bianma/zifuji.php
- 生僻字的存储
所以其实绝大多数,网友提出的生僻字,在UTF8字符集中都是存在的,也就是在Oracle数据库的 AL32UTF8 字符集中都能够被正确存储。
SQL> insert into mogdb values('㱔');
1 row created.
SQL> insert into mogdb values('䶮');
1 row created.
SQL> select cname,dump(cname,1016) from mogdb;
CNAME
------------------------------------------------------------
DUMP(CNAME,1016)
--------------------------------------------------------------------------------
���
Typ=1 Len=9 CharacterSet=AL32UTF8: ef,bf,bd,ef,bf,bd,ef,bf,bd
㼆
Typ=1 Len=3 CharacterSet=AL32UTF8: e3,bc,86
㱔
Typ=1 Len=3 CharacterSet=AL32UTF8: e3,b1,94
CNAME
------------------------------------------------------------
DUMP(CNAME,1016)
--------------------------------------------------------------------------------
䶮
Typ=1 Len=3 CharacterSet=AL32UTF8: e4,b6,ae
当然,如果你使用的是 ZHS16GBK 字符集,则无法存储这些生僻字,可以通过国家字符集数据类型来进行扩展存储。
- 更生僻字的存储
在Unicode中,汉字被划分为以下几个区,以Windows为例给出了支持版本:
基本区:20902字。
扩展A区:6582字。(Windows XP原生支持至此)
扩展B区:42711字。(Windows Vista和Windows 7原生支持至此)
扩展C区:4149字。
扩展D区:222字。(Windows 8、Windows 8.1和Windows 10的早期版本支持至此)
扩展E区:5762字。(Windows 10创意者更新中提供了部分支持)
扩展F区:7473字。(不受支持)
㼆 字位于 A 区,而其简化形态 “王莹”则是位于 E区,大部分系统并不支持。
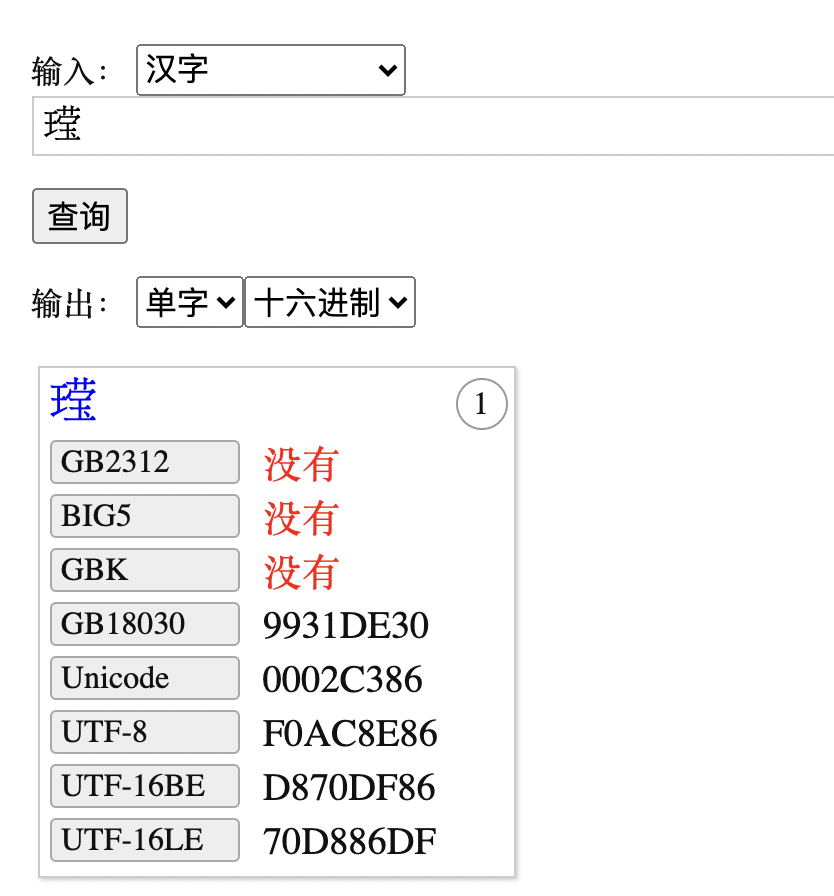
也就是说,虽然 :

这个字的编码:U+2C386 已经给出,但是对于客户端,如果不支持这个显示,则无法正常展示出来。
所以对于一个字符的支持,是包括数据库和客户端两部分的。现在有些输入法可以打出这些生僻字,但是系统不一定能够支持,也就给使用带来了很多麻烦。

在一些字典上这个字是存在的:
![《新华字典》不收[王莹]字考证](https://pic2.zhimg.com/v2-e89e625dcef1890e1d948e3758d4a1b1_1440w.jpg?source=172ae18b)
- 以编码的形式存储数据
SQL> truncate table mogdb;
Table truncated.
SQL> select utl_raw.cast_to_varchar2('e3bc86') from dual;
UTL_RAW.CAST_TO_VARCHAR2('E3BC86')
--------------------------------------------------------------------------------
㼆
SQL> select utl_raw.cast_to_varchar2('F0AC8E86') from dual;
UTL_RAW.CAST_TO_VARCHAR2('F0AC8E86')
--------------------------------------------------------------------------------
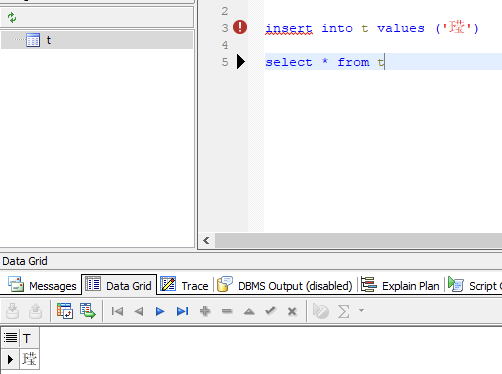
SQL> insert into mogdb values(utl_raw.cast_to_varchar2('e3bc86'));
1 row created.
SQL> insert into mogdb values(utl_raw.cast_to_varchar2('F0AC8E86'));
1 row created.
SQL> select * from mogdb;
CNAME
------------------------------------------------------------
㼆
SQL> select dump(cname,1016) from mogdb;
DUMP(CNAME,1016)
--------------------------------------------------------------------------------
Typ=1 Len=3 CharacterSet=AL32UTF8: e3,bc,86
Typ=1 Len=4 CharacterSet=AL32UTF8: f0,ac,8e,86
关于数据库的生僻字存储和乱码的情形,大抵如此。
- 关于一些支持广泛的字体