




“ 顺序:1生成数据表-2数据表检查-3数据表清洗-4数据预处理-5数据提取-6数据筛选-7数据汇总-8数据统计-9数据输出
进度:完成1、2、3、4、5、9。”

01
—
数据筛选
1、按条件筛选:变量.loc[(变量['列名']>1)&/|(变量['列名']==1),[['列名'……]]
与:&
dtOut[202]:cno cname cpno ccredit0 1 数据库 5.0 41 2 数 学 NaN 22 3 信息系统 1.0 43 4 操作系统 6.0 30 5 数据结构 7.0 41 6 数据处理 NaN 22 7 PASCAL语言 6.0 4dt.loc[(dt['cno']>1)&(dt['ccredit']==4),['cno','cname','ccredit']]Out[201]:cno cname ccredit2 3 信息系统 40 5 数据结构 42 7 PASCAL语言 4
或:|
dt.loc[(dt['cno']>1)|(dt['ccredit']==4),['cno','cname','ccredit']]Out[203]:cno cname ccredit0 1 数据库 41 2 数 学 22 3 信息系统 43 4 操作系统 30 5 数据结构 41 6 数据处理 22 7 PASCAL语言 4
非:!=
dt.loc[(dt['cname']!='数据处理')|(dt['ccredit']==4),['cno','cname','ccredit']]Out[205]:cno cname ccredit0 1 数据库 41 2 数 学 22 3 信息系统 43 4 操作系统 30 5 数据结构 42 7 PASCAL语言 4
2、excel 中 sumifs :以上.列名.sum()
dt.loc[(dt['cno']>1)&(dt['ccredit']==4),['cno','cname','ccredit']].ccredit.sum()Out[204]: 12
3、excel 中的 countifs:以上.列名.count()
dt.loc[(dt['cname']!='数据处理')|(dt['ccredit']==4),['cno','cname','ccredit']].cname.count()Out[207]: 6
4、变量.query('列名==列名/[值……]')
dt.query('cno<ccredit')Out[212]:cno cname cpno ccredit0 1 数据库 5.0 42 3 信息系统 1.0 4dt.query('cno==[2,3]')Out[214]:cno cname cpno ccredit1 2 数 学 NaN 22 3 信息系统 1.0 4

02
—
数据汇总
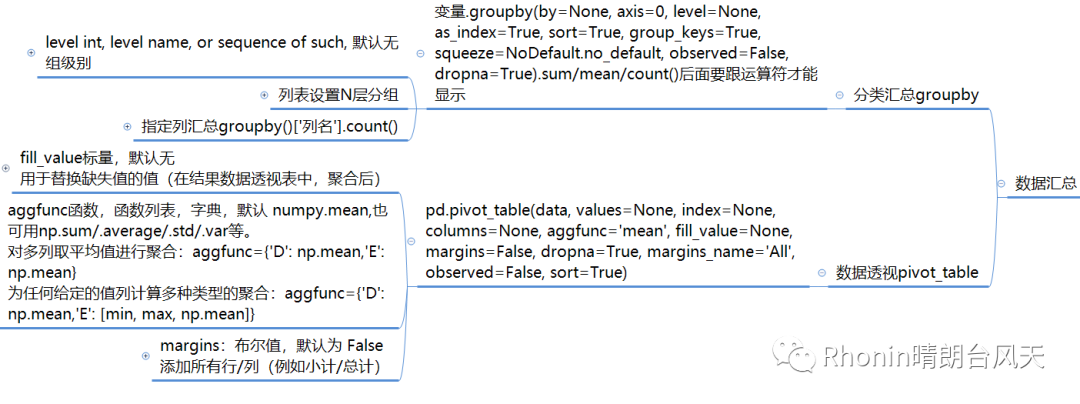
1、分类汇总groupby
变量.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True).sum/mean/count()后面要跟运算符才能显示。
level int, level name, or sequence of such, 默认无。组级别
dt.groupby(level=0).mean()Out[224]:cno cpno ccredit0 1.5 3.5 4.51 2.5 3.0 3.52 3.5 2.5 4.53 4.0 6.0 3.0
列表设置N层分组
dt.groupby(['cno','ccredit']).sum()Out[226]:cpnocno ccredit1 4 5.02 2 0.05 2.03 4 1.05 3.04 3 6.05 4.0
指定列汇总groupby()['列名'].count()
dt.groupby('cno')['ccredit'].count()Out[228]:cno1 12 23 24 2Name: ccredit, dtype: int64
2、数据透视pivot_table
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
fill_value标量,默认无。用于替换缺失值的值(在结果数据透视表中,聚合后)
pd.pivot_table(dt,values='ccredit',index=['cno'],columns=['cname'])Out[230]:cname 数据库 信息系统 操作系统 数 学cno1 4.0 NaN NaN NaN2 NaN NaN NaN 3.53 NaN 4.5 NaN NaN4 NaN NaN 4.0 NaNpd.pivot_table(dt,values='ccredit',index=['cno'],columns=['cname'],fill_value=0)Out[231]:cname 数据库 信息系统 操作系统 数 学cno1 4 0.0 0 0.02 0 0.0 0 3.53 0 4.5 0 0.04 0 0.0 4 0.0
aggfunc函数,函数列表,字典,默认 numpy.mean,也可用np.sum/.average/.std/.var等。
对多列取平均值进行聚合:aggfunc={'D': np.mean,'E': np.mean}
为任何给定的值列计算多种类型的聚合:aggfunc={'D': np.mean,'E': [min, max, np.mean]}
pd.pivot_table(dt,values='ccredit',index=['cno'],columns=['cname'],aggfunc=np.sum)Out[232]:cname 数据库 信息系统 操作系统 数 学cno1 4.0 NaN NaN NaN2 NaN NaN NaN 7.03 NaN 9.0 NaN NaN4 NaN NaN 8.0 NaNpd.pivot_table(dt,values='ccredit',index=['cno'],columns=['cname'],aggfunc=np.std)Out[233]:cname 信息系统 操作系统 数 学cno2 NaN NaN 2.121323 0.707107 NaN NaN4 NaN 1.414214 NaN
margins:布尔值,默认为 False。添加所有行/列(例如小计/总计)
pd.pivot_table(dt,values='ccredit',index=['cno'],columns=['cname'],aggfunc=np.sum,margins=True)Out[234]:cname 数据库 信息系统 操作系统 数 学 Allcno1 4.0 NaN NaN NaN 42 NaN NaN NaN 7.0 73 NaN 9.0 NaN NaN 94 NaN NaN 8.0 NaN 8All 4.0 9.0 8.0 7.0 28
03
—
数据统计
1、数据采样:变量.sample(n=,weights=[权重],replace=False采用不放回)
dt.sample(n=3)Out[235]:cno cname cpno ccredit0 1 数据库 5.0 42 3 信息系统 1.0 42 4 操作系统 4.0 5
以下以前已有学习过,不再赘述:Python55-Pandas库与Series、DataFrame数据类型
2、描述统计:变量.describe().roud(2).T
3、标准差:.std()
4、协方差:.cov()
5、相关分析:.corr()
至此咱们关于pandas比较基础的数据处理学完了,等什么时候有空咱们搞多点数据好好操练操练。
本来我还没打算那么快进入数据挖掘,想把基础打好多练练代码,但因为个人原因,近期会开始了解一些算法模型,大家一起加油鸭!

