





分享嘉宾:周晖栋 bilibili
编辑整理:宋灵城 贝壳找房/东南大学
出品平台:DataFunTalk
导读:本文主要介绍Flink实时计算在bilibili的优化,将从以下四个方面展开:① Flink-connector稳定性优化;② Flink sql优化;③ Flink-runtime优化;④ 对未来的展望。
01
概述
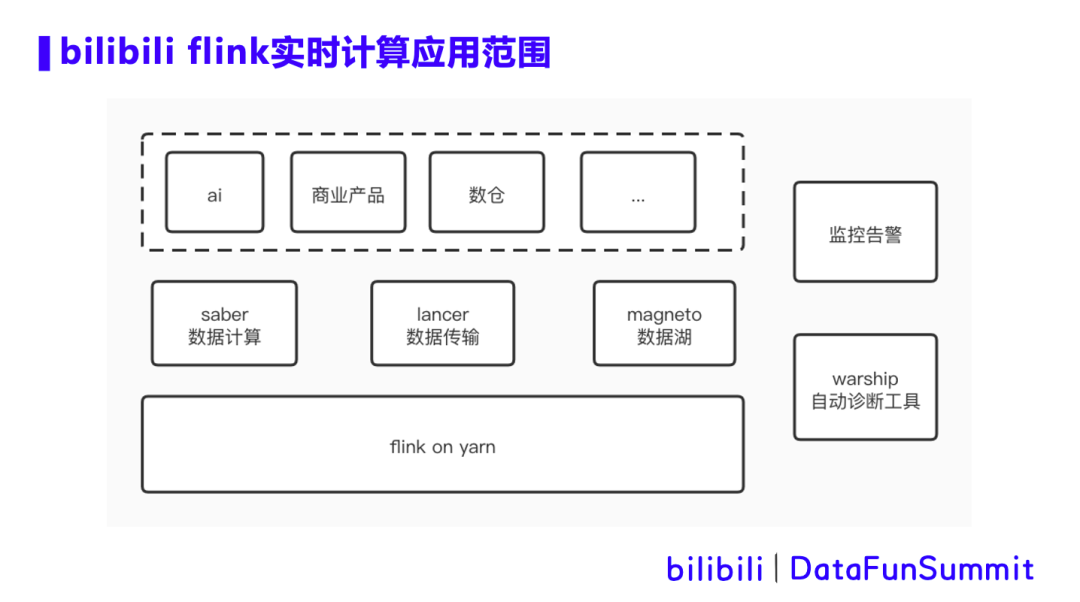
首先介绍下Flink实时计算在b站的应用场景。
在b站,Flink on yarn 主要支持3个场景,saber数据计算,lancer数据传输和magneto数据湖。
saber是b站的一个数据计算提交平台,主要支持业务方通过Flink sql和Flink jar的方式提交实时计算任务。目前平台有上千个任务在运行,并且仍在迅猛增长。
lancer是b站的数据传输系统,主要用于收集app端、服务端等各种数据上报,根据元数据的定义信息将数据写入kafka,hive等后端存储,用于下游处理使用。lancer承载了日增万亿数据规模。
magento是b站的数据湖项目,通过Flink将上游数据写入iceberg或者hudi。在基于hdfs的表上,magento支持数据的增删改操作,同时支持分钟级可见性。
以上三个系统支持了AI,商业产品和数据仓库等业务线的众多实时传输和实时计算业务场景。同时,针对平台上的Flink任务,我们配置了监控告警,以及warship自动诊断工具,用于辅助运维。今天主要分享在我们实践过程中遇到的痛点以及解决思路。
02
Flink-connector稳定性优化
1. hdfs集群局部热点问题
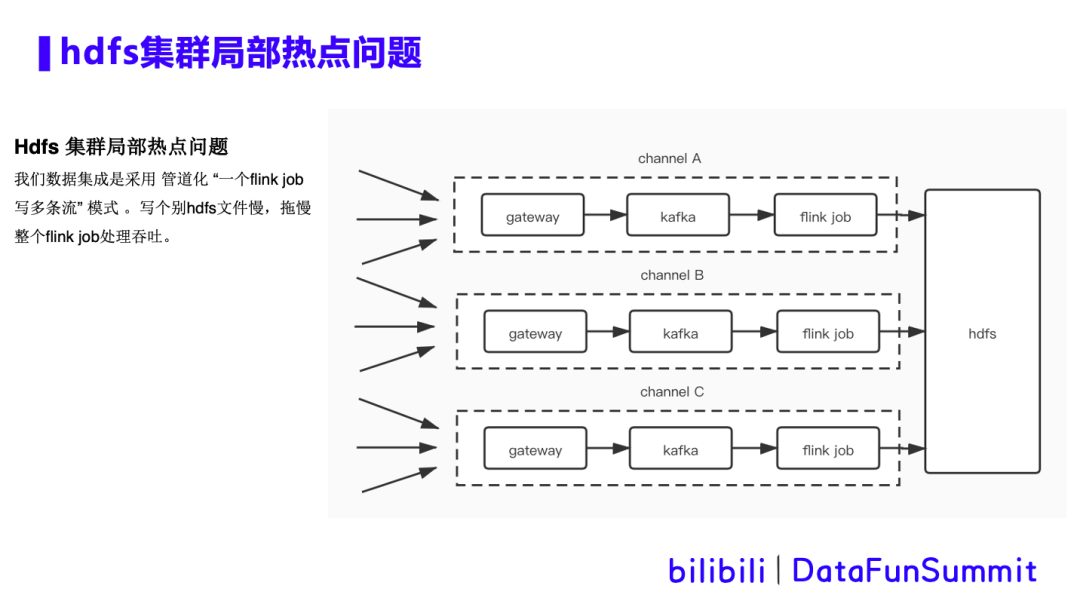
背景描述:Flink在写hdfs时遇到写个别hdfs文件慢的问题,也就是hdfs集群局部热点问题。由于b站数据集成是采用管道化的方式,即“一个Flink任务写多条流”的模式。数据集成过程中会出现几百个流存在于同一个kafka topic中的现象,并且由同一个Flink 任务分流写到多个hive表中。这就需要给任务设置很大的并行度,从而会同时打开超大数量的hdfs文件,这使得局部热点问题更加严重。当Flink任务做checkpoint时,hdfsSink会去做flush数据,close文件等操作,经常因为个别文件close慢,而拖累整体的吞吐。
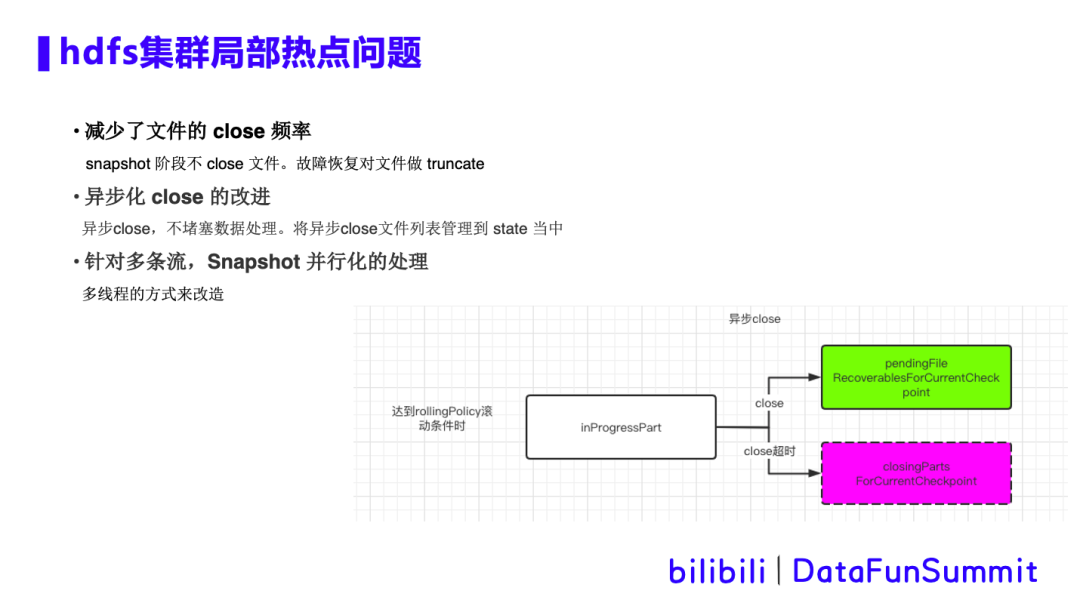
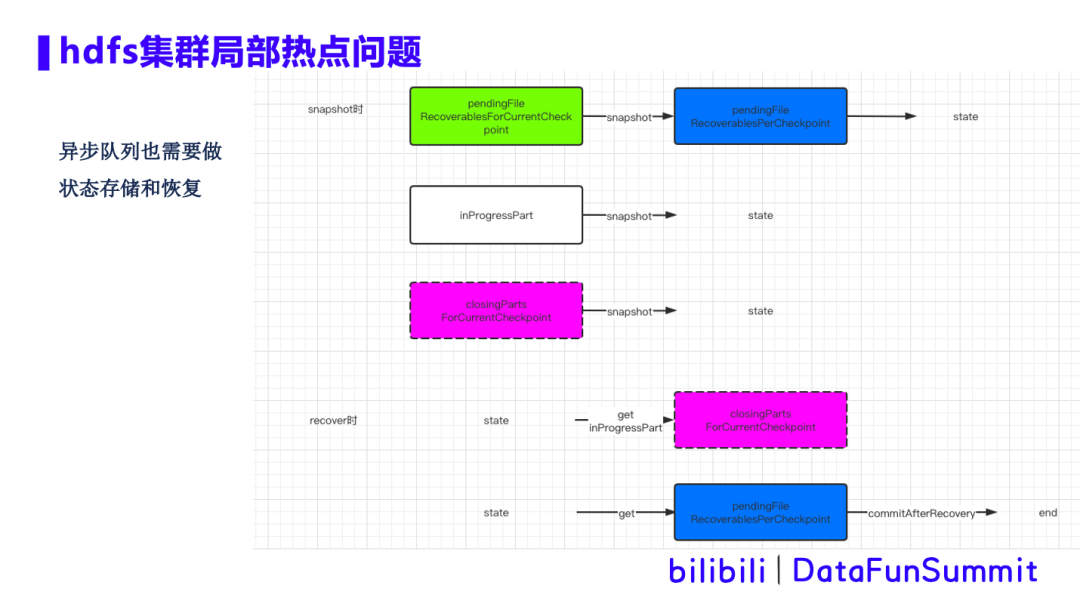
优化方案:针对hdfs局部热点问题,我们做了三点优化:
2. 分区read判断问题
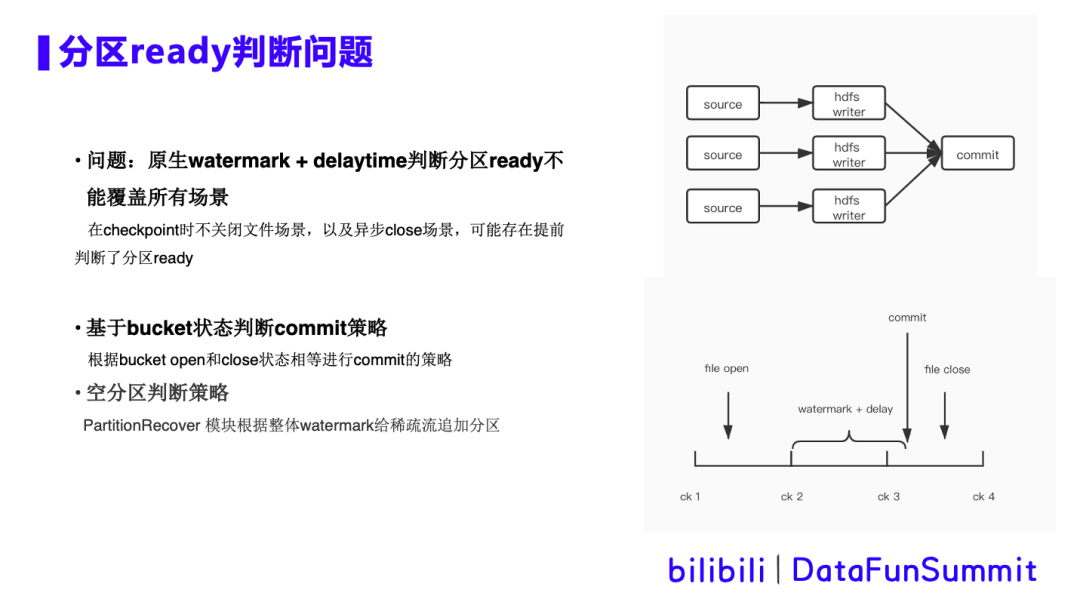
背景描述:右上角展示的是读取kafka数据写入hive的Flink任务的简单DAG图,由多并行度的hdfs writer算子和单并行度的commit算子组成。在commit算子接收上游所有算子checkpoint都已经完成,并且当前时间超过了watermark +delaytime时,我们就认为该hive分区已经ready了,可以commit hive分区了。然而在checkpoint时不关闭文件以及异步close的场景中,可能出现长时间文件未close的情况,那么超时后就会提前判断认为分区ready,从而提交hive分区,但由于文件未关闭,下游任务运行时就会出现报错。
优化方案:
3. 通用sink稳定性优化
背景描述:
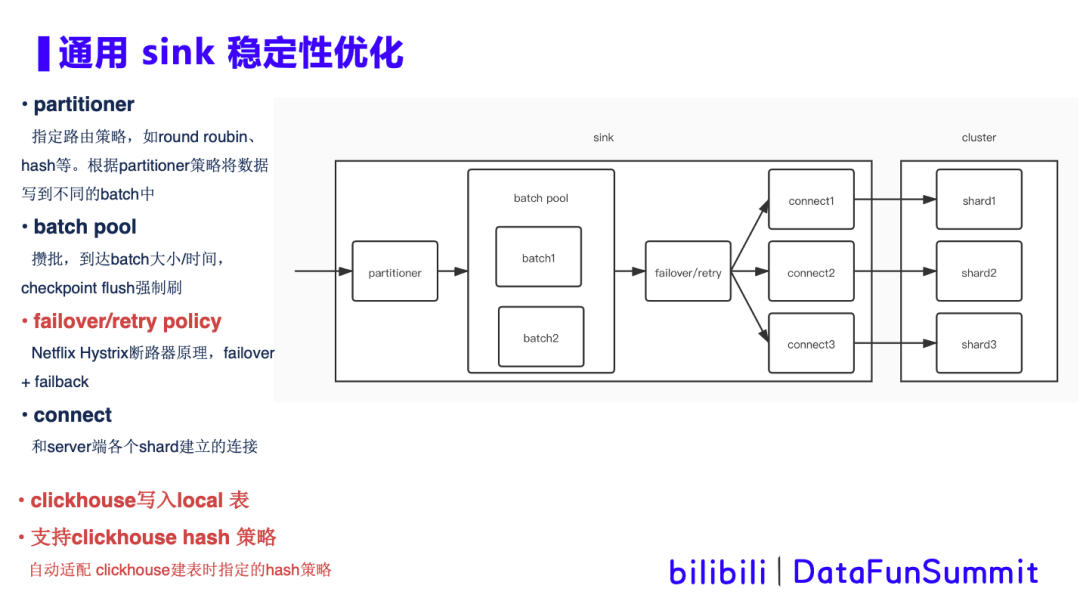
优化方案:
1. interval join优化
背景描述:在ai实时生成模型训练数据场景中,需要将feed流和click流进行join,将信息的展现和用户的点击关联在一起并输出,构成正例和反例,作为模型训练的数据输出。由于feed流和click流到达的先后顺序不定,需要使用interval join将数据缓存一段时间,等待左流、右流到达完成join。优化的两个需求如下:
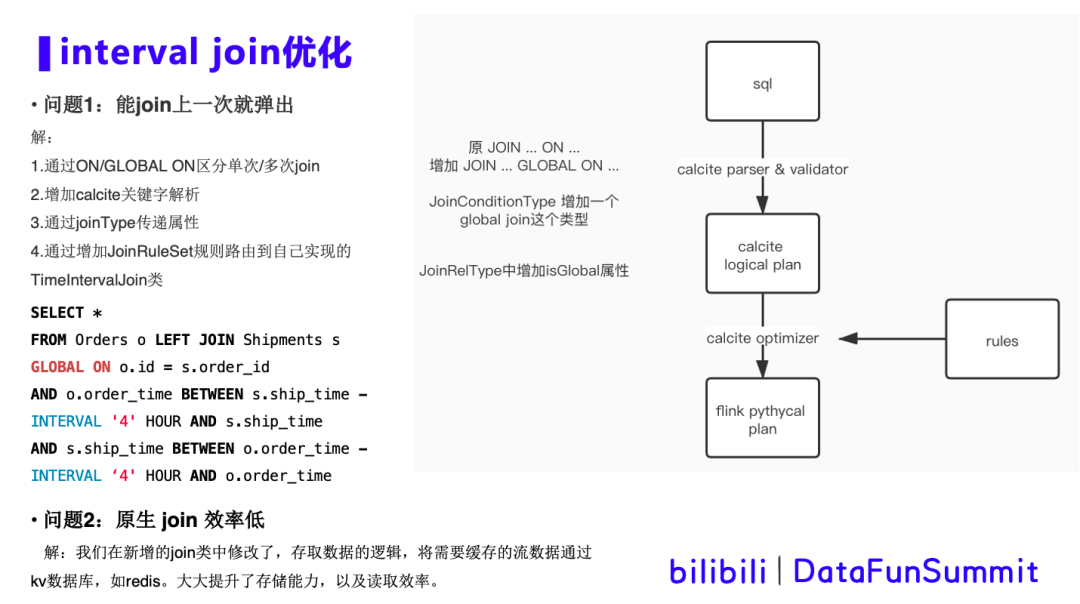
首先来了解一下Flink sql是如何解析并映射到对应的方法类,如上边的图所示:
2. kafka自定义分流优化
背景描述:
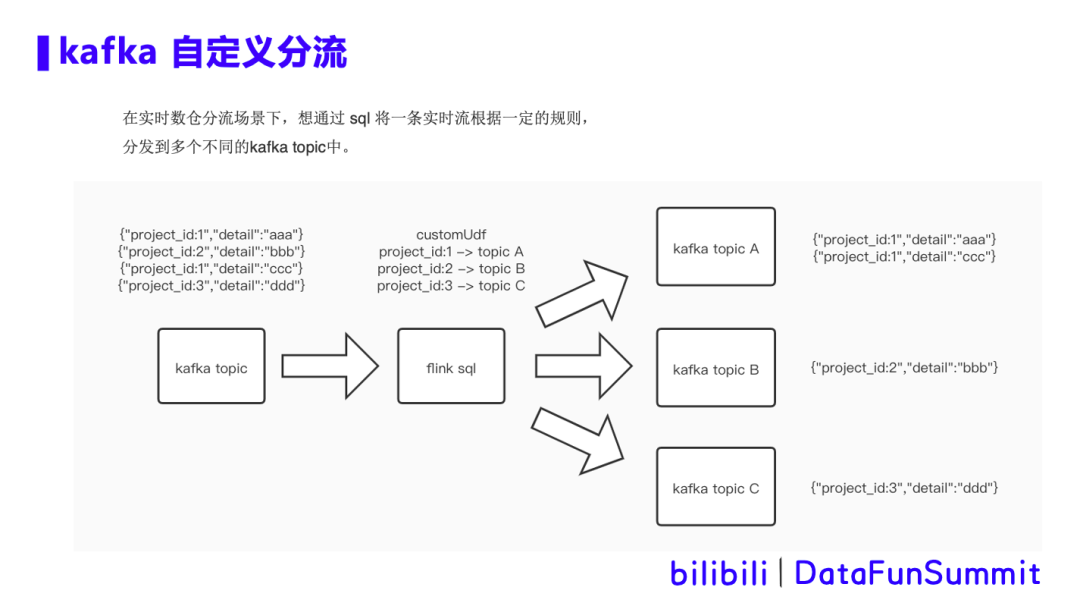
在实时数仓分流场景下,想通过sql将一条实时流根据一定的规则,分发到多个不同的kafka topic中。如图所示,通过自定义udf解析数据中project_id字段,将数据分流到a b c 三个topic中。
优化方案:

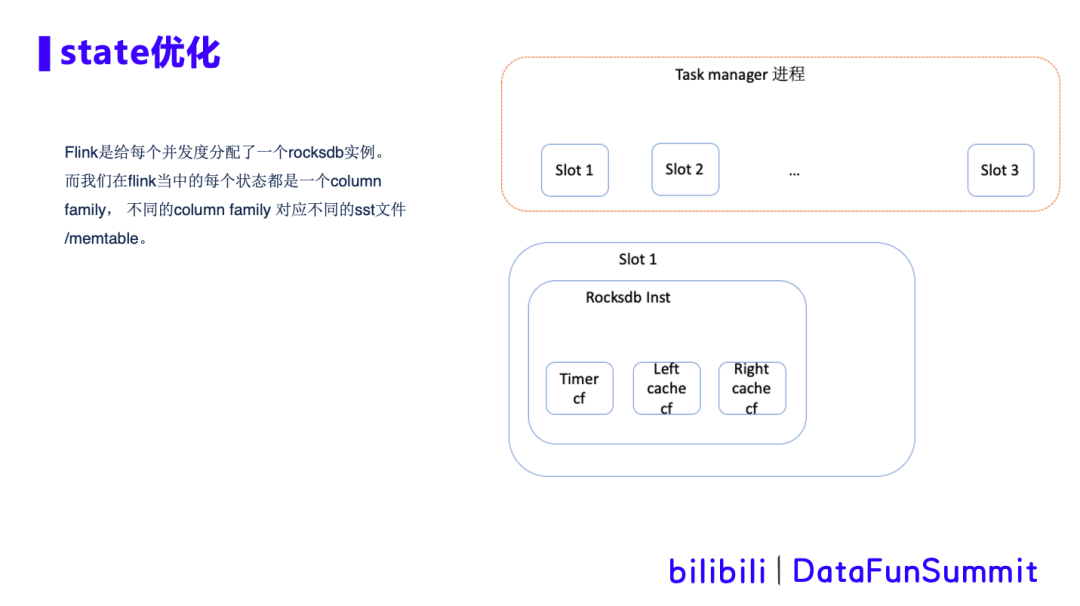
1. Flink state优化
针对Flink任务中超大state cache的场景,我们进行cache存储的调研和优化。在cache快速过期的场景下,比如interval join,之前提到的ai实时生成模型训练数据,feed流和click流做join,需要cache的数据量大,设定一个小时就过期,且没有update操作。Cache调研:
且同样可以通过kv高效查找数据。同时和checkpoint可以很好的结合,一个checkpoint对应一组rocksdb的sst文件,便于故障恢复的管理。
所以我们最终选择使用rocksdb最为state的cache。Rocksdb cache在Flink中的架构如下图所示:
rocksdb最显著的特征就是会compaction,rocksdb的存储是把记录按照key排序后分布到各个文件当中。如下图所示,rocksdb会将L0的小文件进行合并,保证L1开始各层文件中的key都是有序排列的,来提高读取时磁盘的读取效率。

但是在我们的场景中,当数据量增大,这种高频率的合并会占用大量的CPU资源,最终导致整个任务没法运行。针对这个问题,我们做了如下三个优化方案:
2. 全局并行度
在sql任务中,可以设置默认并行度,也可以对各个算子单独设置并行度。对用户来说,学习成本大,设置的也不一定合理。具体痛点如下所示:
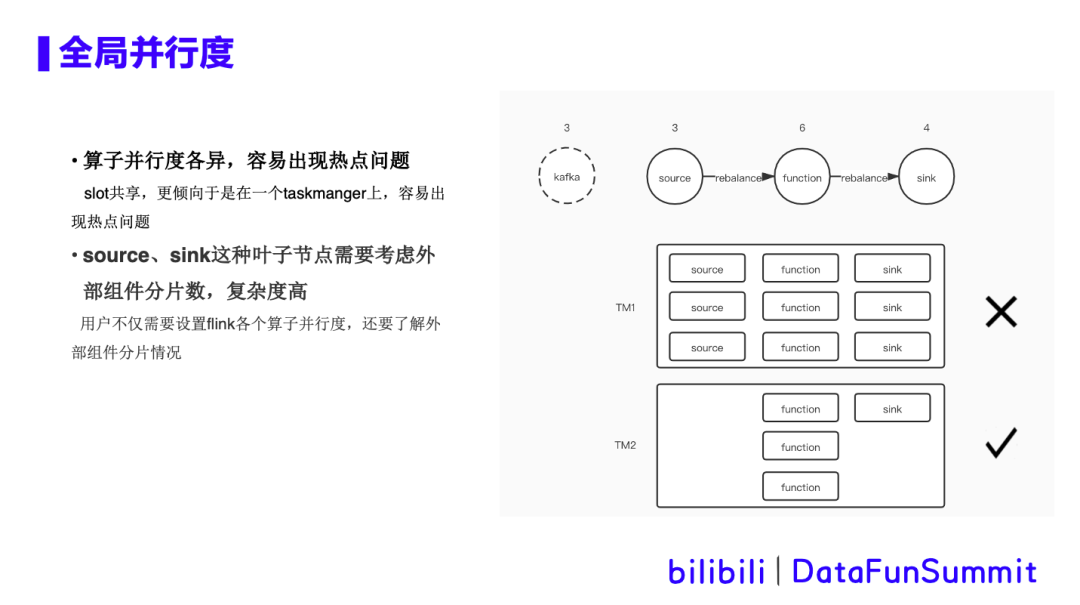
按照热点来看,上面这个task是有cpu热点,下面这个task cpu比较空闲。
优化方案:
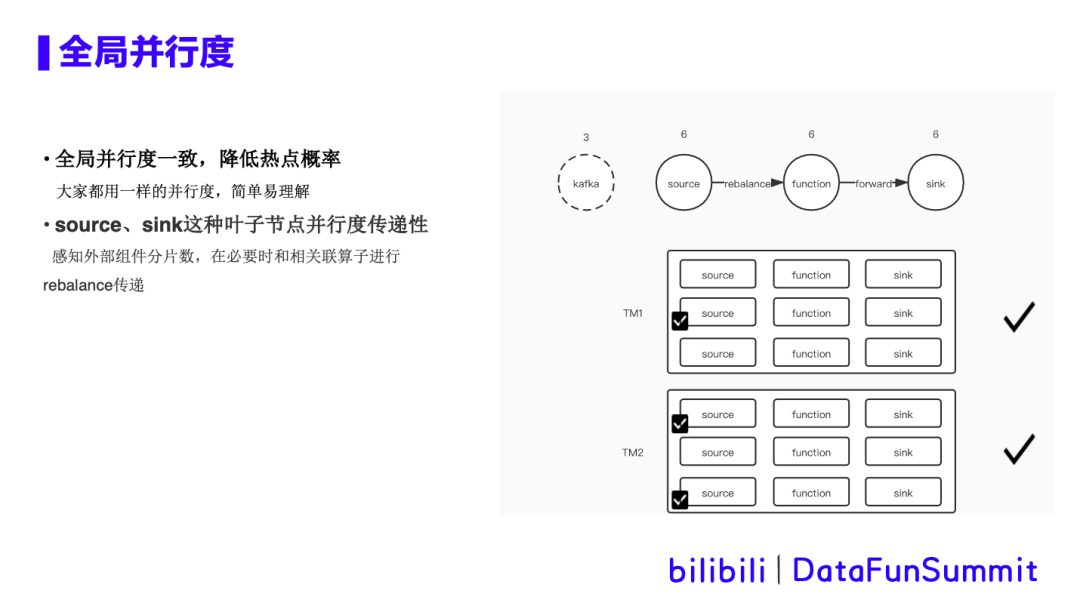
设置DEFAULT并行度:修改tableInfo当中并发度的默认值为-1,与正常的并发度设置做区分;
KAFKA topic partition数感知:Kafka sink和source加入检测topic partition个数的逻辑,用于在生成DAG的时候与并发度做比较;
DAG重启生成逻辑:在DAG最基础的调度单元中增加tpSize(topic partition size)这个属性,用与在DAG调度过程中,针对sink和source算子中不同并发度和tpSize做不同的处理。
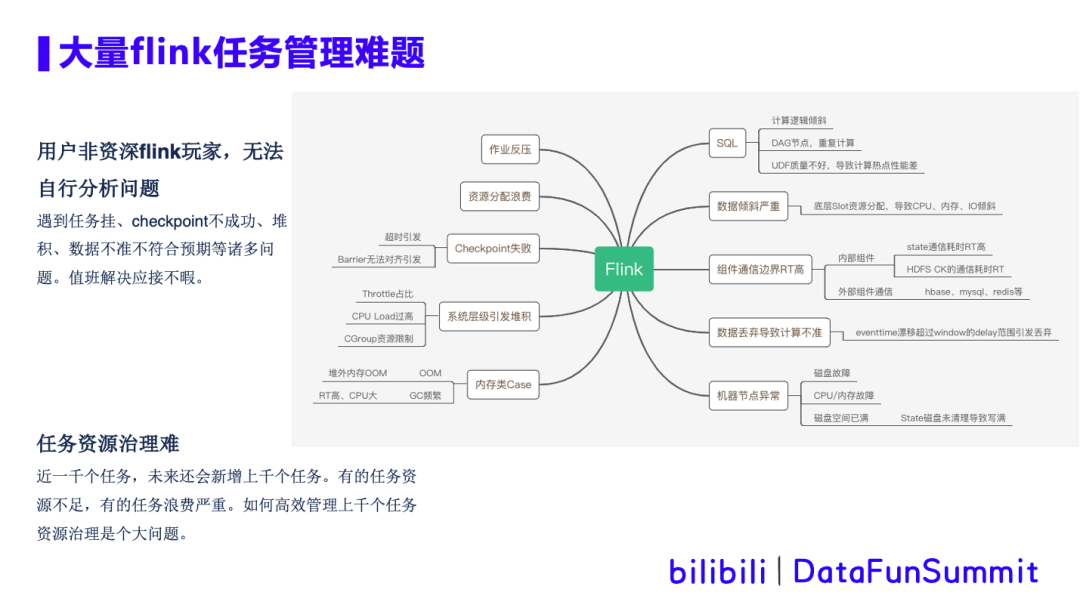
3. warship作业智能诊断工具
随着平台作业的日益增多,作业类型愈加复杂化,对作业的运维管理难度越来越大。
大部分用户非资深Flink玩家,在遇到任务挂、checkpoint不成功、堆积、数据不准不符合预期等诸多问题时,无法自主分析解决,这大量消耗了平台值班人员以及用户自身的时间。
所以我们通过warship这个作业智能诊断工具,来辅助线上作业的半自助化运维。warship智能诊断工具,能够自动收集平台(系统层、应用层)上所有的度量标准,并对收集的数据进行分析,并将分析结果以一种简单且易于理解的形式展示出来。同时可以根据历史监控指标采集,分析出资源不够或者资源浪费的任务,给出资源调整建议,未来做到AutoScale任务自动扩缩容。Warship工具的原理如下图所示:
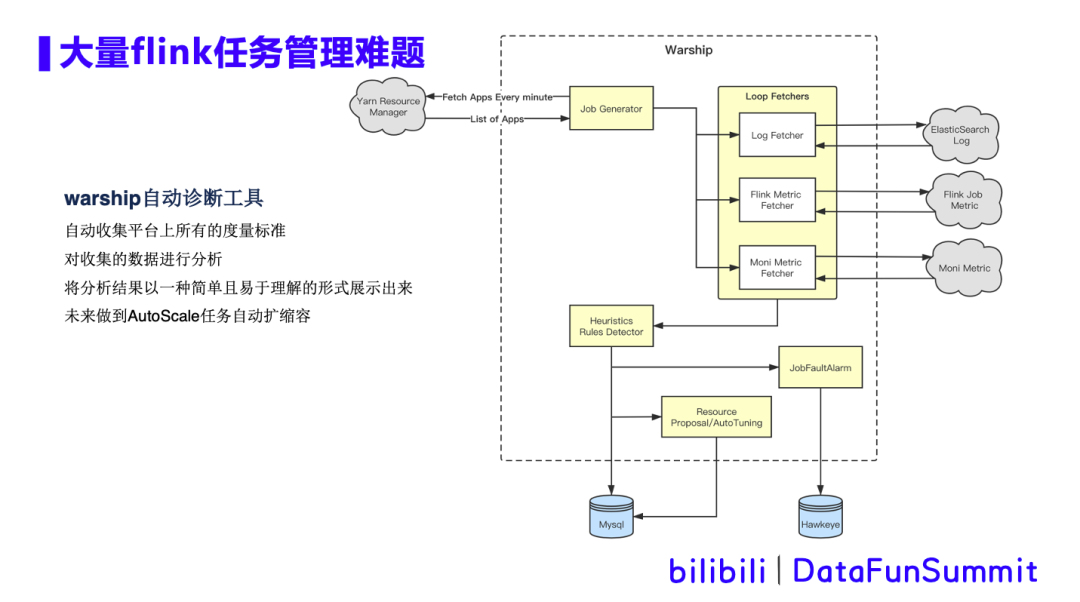
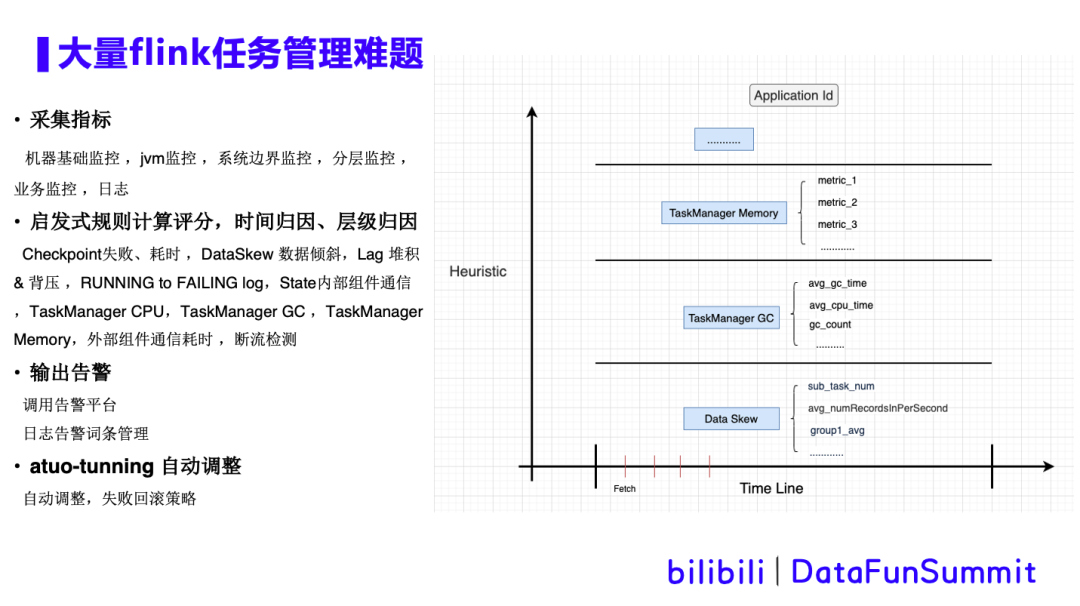
如上图,warship从yarn上获取正在运行的app列表,并采集es日志,Flink任务相关指标 ,以及机器级别指标等。这些采集的数据经过启发式算法规则计算、评分、时间归因或者层级归因后,调用告警平台,输出告警,同时进行自动调整并存入数据库。详细的过程如下图所示:
4. checkpoint metadata完整性判断
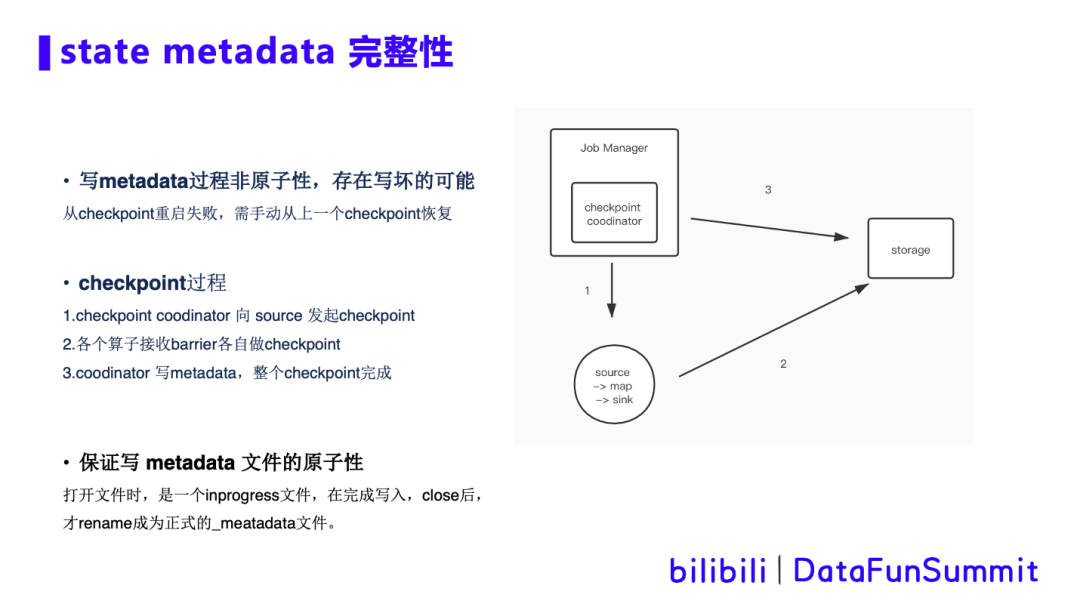
背景描述:我们都知道Flink任务做checkpoint大致分三个步骤:
这个过程中,步骤3是非原子性的,所以存在metadata写一半任务挂掉的场景,同时这个metadata文件已经生成,但不完整。当从checkpoint回复时,虽然找到这个metadata文件,但是由于其不完整,任务无法恢复,只能手动从上一个checkpoint恢复,如果在非工作时间出现这种场景,则大大拉长任务的恢复时间。
优化方案:避免这种情况的出现,我们需保证写metadata文件的原子性,要么成功,要么失败。解决思路和Flink hdfs sink一致。在打开文件时,文件格式是inprogress类型,在完成写入,并close后,才rename成为正式的_metadata文件,这样就能保证metadata文件的原子性。
checkpoint恢复时,发现没有正式的_metadata文件,就认为此次checkpoint没有成功。跳过此checkpoint,从上一个checkpoint恢复。
快速的去做Flink任务的恢复。因为在写kafka的场景中,通过快速的恢复,可以减少kafka断流的时间以及对下游的影响。
Q:Flink任务调度是否有专门的管理平台?
A:有的,前面提到saber就是我们sql以及jar的管理平台。
Q:Flink sql 新增udf,作业需要重启吗?
A:这块的定义是在任务提交前做的定义,所以新增或者修改udf内容是需要重启任务的。
Q:Flink背压堆积,怎么处理数据消积,峰值的问题?
A:主要通过具体问题具体分析,如果是有数据倾斜的情况,需要去做一些sql上的改变,把数据做打散的操作;如果是一些cpu不够的场景,会在cpu的监控上体现处理,如果所有的tm的cpu都比较高的话,对任务做一个整体的扩容。
Q:Flink任务是怎么做版本管理的?
A:在我们saber数据管理平台上做了分版本的管理,包括(1.8,1.11,1.12等版本),会根据不同版本,分别提交到对应的任务环境。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

活动推荐:

社群推荐:

关于我们:
🧐分享、点赞、在看,给个3连击呗!👇
