一、单机版kafka的搭建
1.1、准备工作
1.2、下载安装包
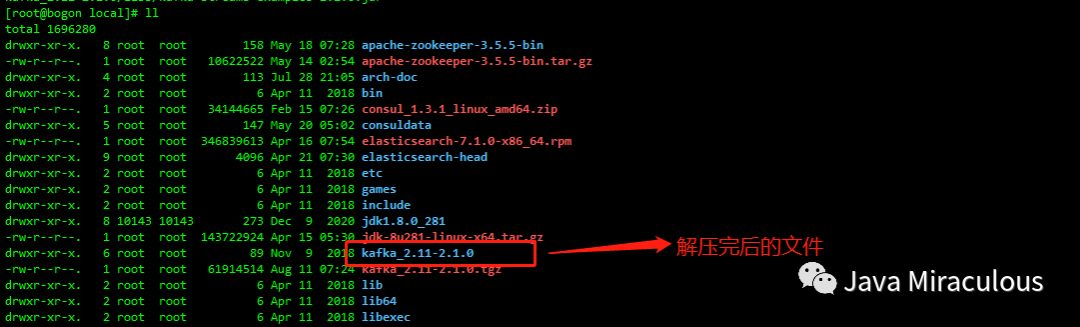
1.3、上传并解压安装包
1.4、启动kafka
bin/kafka-server-start.sh -daemon config/server.properties

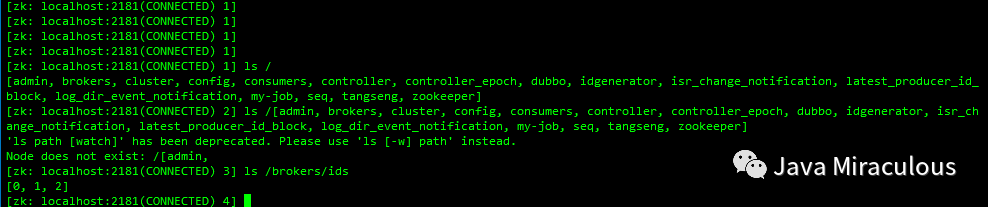
1.5、连接上zk客户端查看kafka相关节点

1.6、创建、查看、删除topic
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic xiaop
bin/kafka-topics.sh --list --zookeeper 127.0.0.1:2181
bin/kafka-topics.sh --delete --topic xiaop --zookeeper 127.0.0.1:2181

注:删除完后再创建一遍,下面演示需要用到
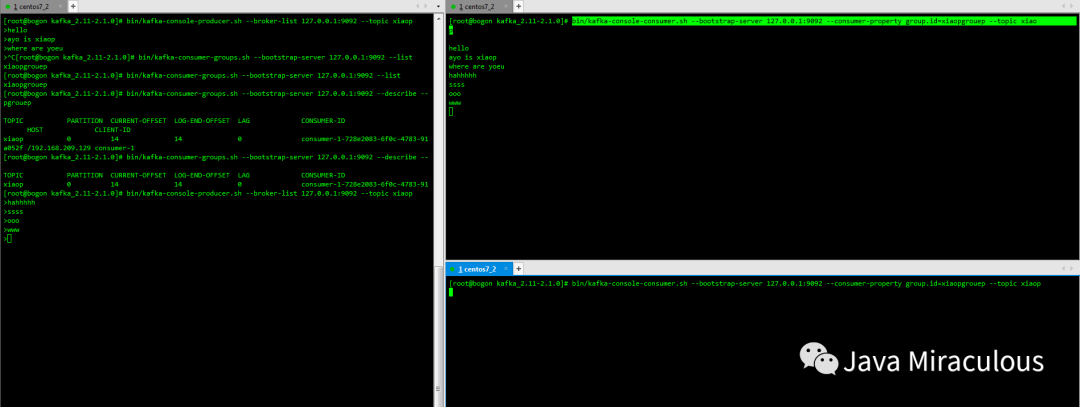
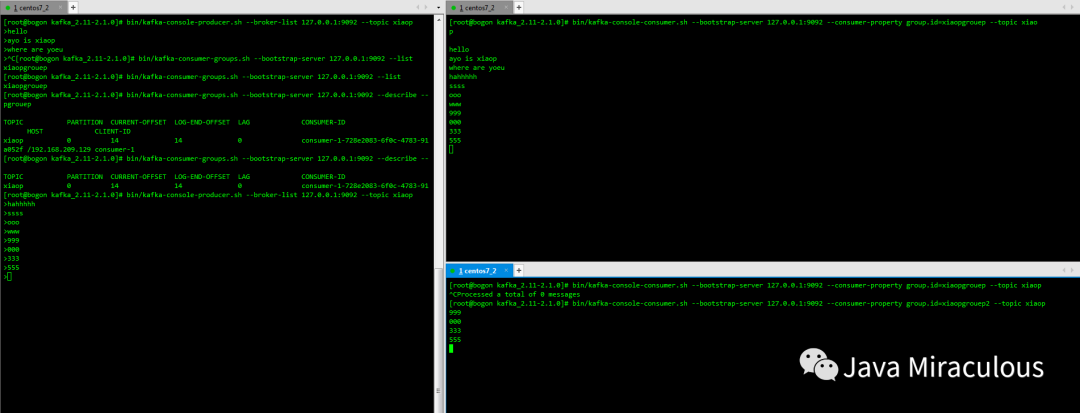
1.7、发送消息和消费消息
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic xiaop
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --consumer-property group.id=xiaopgrouep --topic xiaop

bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --consumer-property group.id=xiaopgrouep --from-beginning --topic xiaop
1.8、查看消费者组以及消费者的消费偏移量
bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list

bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group xiaopgrouep

CURRENT-OFFSET:当前消费偏移量
LOG-END-OFFSET:结束的偏移量
LAG:落后消费的消息数
注:我这的xiaopgrouep中多了个e,是因为我键盘联电导致,不必在意
1.9、单播消费和多播消费
二、集群版kafka的搭建
注:
我的服务器信息如下
三台服务器ip地址:
192.168.209.128,192.168.209.129,192.168.209.130
zk集群:
192.168.209.128:2181,192.168.209.129:2181,192.168.209.130:2181
kafka集群:
192.168.209.128:9092,192.168.209.129:9092,192.168.209.130:9092
2.1、修改配置文件
vi usr/local/kafka_2.11-2.1.0/config/server.properties
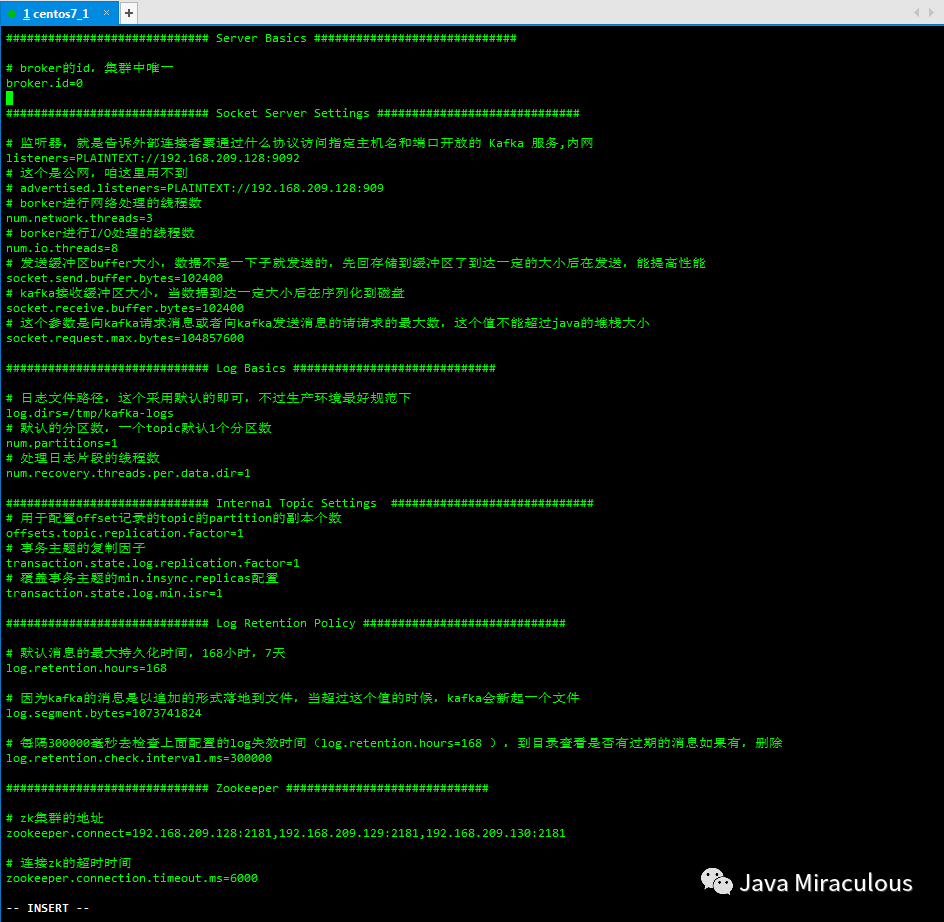
############################# Server Basics ############################## broker的id,集群中唯一broker.id=0############################# Socket Server Settings ############################## 监听器,就是告诉外部连接者要通过什么协议访问指定主机名和端口开放的 Kafka 服务,内网listeners=PLAINTEXT://192.168.209.128:9092# 这个是公网,咱这里用不到# advertised.listeners=PLAINTEXT://192.168.209.128:909# borker进行网络处理的线程数num.network.threads=3# borker进行I/O处理的线程数num.io.threads=8# 发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能socket.send.buffer.bytes=102400# kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘socket.receive.buffer.bytes=102400# 这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小socket.request.max.bytes=104857600############################# Log Basics ############################## 日志文件路径,这个采用默认的即可,不过生产环境最好规范下log.dirs=/tmp/kafka-logs# 默认的分区数,一个topic默认1个分区数num.partitions=1# 处理日志片段的线程数num.recovery.threads.per.data.dir=1############################# Internal Topic Settings ############################## 用于配置offset记录的topic的partition的副本个数offsets.topic.replication.factor=1# 事务主题的复制因子transaction.state.log.replication.factor=1# 覆盖事务主题的min.insync.replicas配置transaction.state.log.min.isr=1############################ Log Retention Policy ############################## 默认消息的最大持久化时间,168小时,7天log.retention.hours=168# 因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件log.segment.bytes=1073741824# 每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除log.retention.check.interval.ms=300000############################# Zookeeper ############################## zk集群的地址zookeeper.connect=192.168.209.128:2181,192.168.209.129:2181,192.168.209.130:2181# 连接zk的超时时间zookeeper.connection.timeout.ms=6000############################# Group Coordinator Settings ############################## 这个参数的主要效果就是让coordinator推迟空消费组接收到成员加入请求后本应立即开启的rebalance。在实际使用时,假设你预估你的所有consumer组成员加入需要在10s内完成,那么你就可以设置该参数=10000group.initial.rebalance.delay.ms=0
scp server.properties root@192.168.209.129:/usr/local/kafka_2.11-2.1.0/config
scp server.properties root@192.168.209.130:/usr/local/kafka_2.11-2.1.0/config
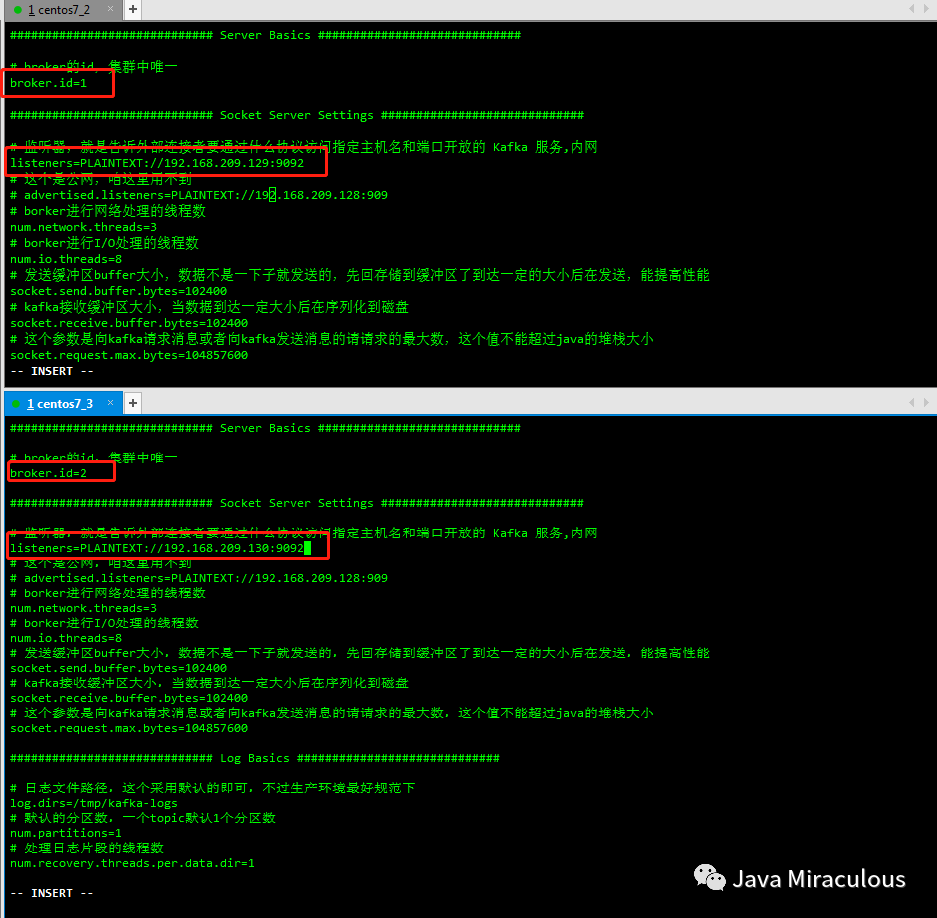
2.2、依次启动三台kafka服务
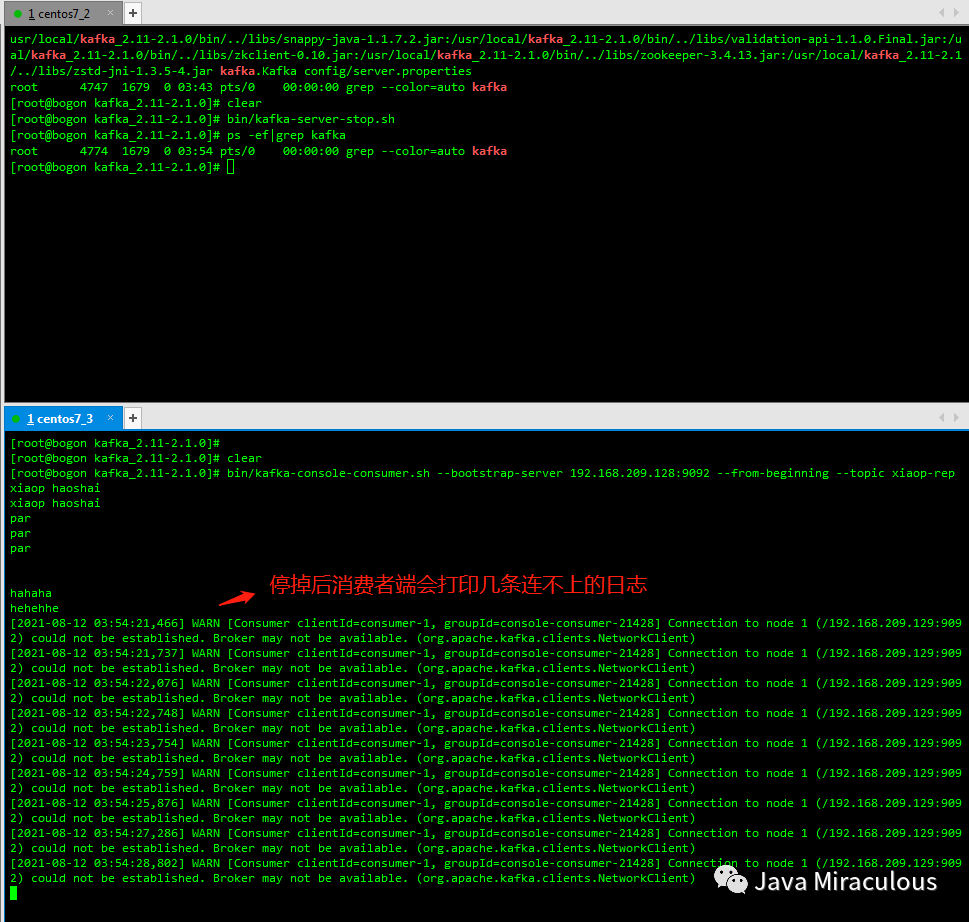
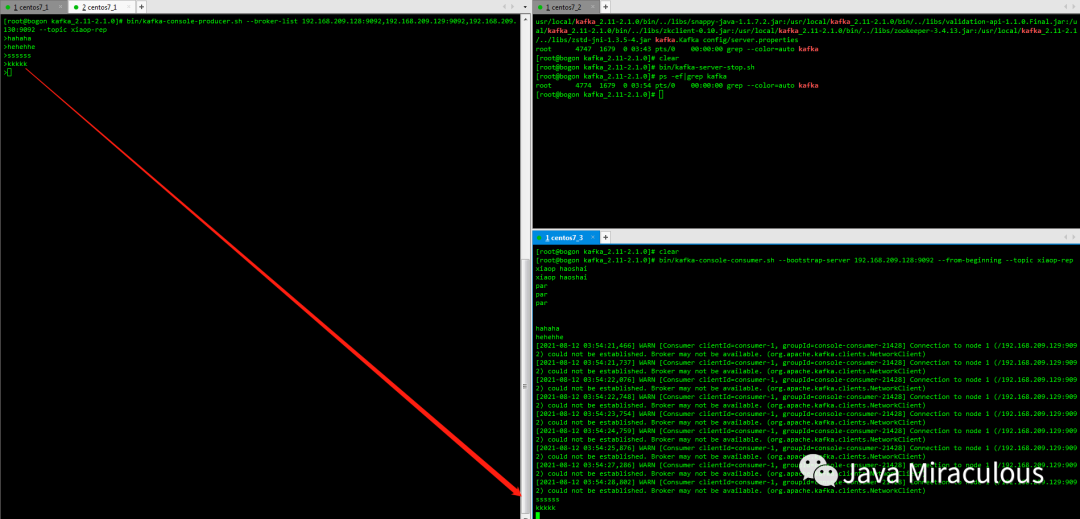
注:启动前删除server.properties中log.dirs对应目录中的kafka-logs,因为上面跑单机的时候产生的文件,不删除的话kafka集群起不来,另外防火墙要开放9092端口
tail -200f usr/local/kafka_2.11-2.1.0/logs/server.log
2.3、进行一些操作
bin/kafka-topics.sh --create --zookeeper 192.168.209.128:2181,192.168.209.129:2181,192.168.209.130:2181 --replication-factor 3 --partitions 2 --topic xiaop-rep

bin/kafka-topics.sh --describe --zookeeper 192.168.209.128:2181,192.168.209.129:2181,192.168.209.130:2181 --topic xiaop-rep
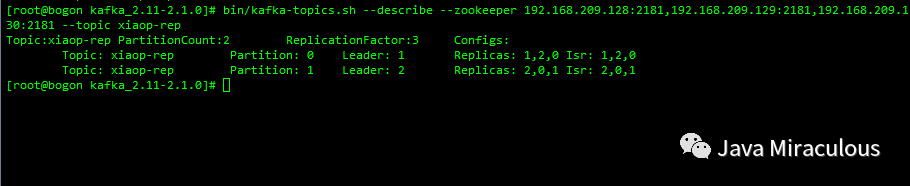
第一行是所有分区的概要信息,之后的每一行表示每一个partition的信息
leader:负责给定partition的所有读写请求
replicas:某个partition在哪几个broker上存在备份。不管这个节点是不是leader,甚至这个节点挂了,也会列出。
isr:replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
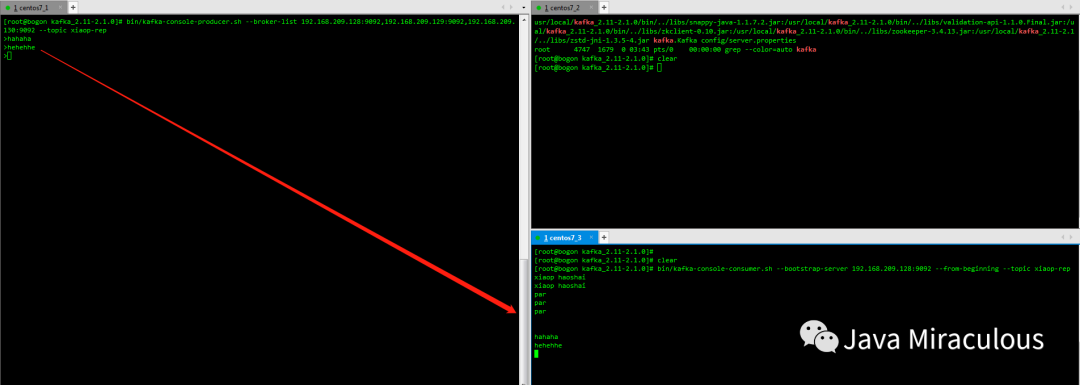
bin/kafka-console-producer.sh --broker-list 192.168.209.128:9092,192.168.209.129:9092,192.168.209.130:9092 --topic xiaop-rep
bin/kafka-console-consumer.sh --bootstrap-server 192.168.209.128:9092 --from-beginning --topic xiaop-rep