




前言
声明,本文用的是jdk1.8
前面章节回顾:
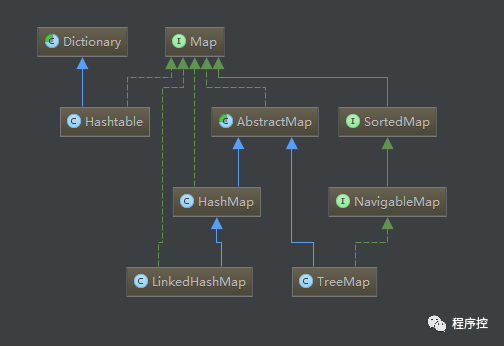
Java集合是Java提供的工具包,包含了常用的数据结构:集合、链表、队列、栈、数组、映射等。Java集合工具包位置是java.util.*,Java集合主要可以划分为4个部分:List列表、Set集合、Map映射、工具类(Iterator迭代器、Enumeration枚举类、Arrays和Collections)。
Map简介和散列表的概念在上一篇【Java中的Map集合、散列表、红黑树介绍】中已经介绍,这里就不赘述了。本篇主要说的是Java集合中TreeMap和LinkedHashMap~~
一、TreeMap剖析
TreeMap定义:
public class TreeMap<K,V> extends AbstractMap<K,V>implements NavigableMap<K,V>, Cloneable, java.io.Serializable { }
TreeMap简介:
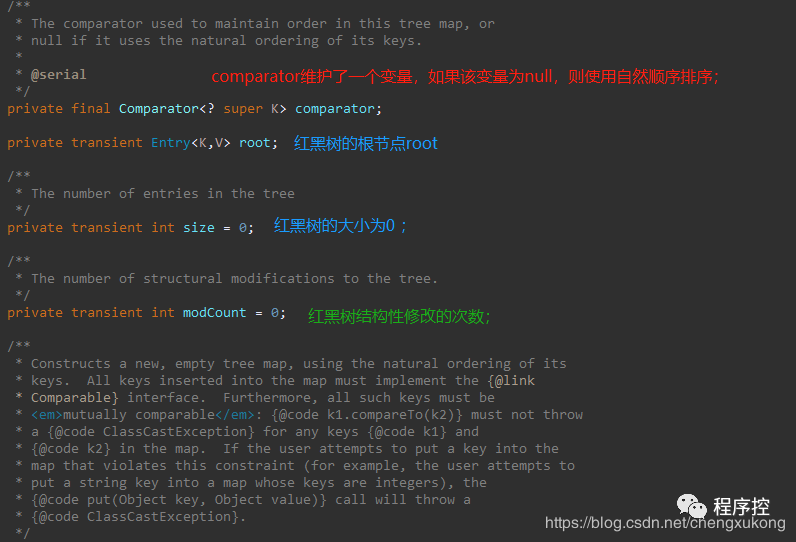
TreeMap 是一个有序的key-value集合(根据元素的Key进行排序),不允许key为null。 底层是红黑树,它方法的时间复杂度都不会太高:log(n)。 TreeMap的映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。 TreeMap是非同步的, 它的iterator 方法返回的迭代器是快速失败fail-fast的。 使用Comparator或者Comparable来比较key是否相等与排序的问题 TreeMap包含几个重要的成员变量: root, size, comparator。root 是红黑树的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
TreeMap源码分析:
先来了解下TreeMap的属性~
1、构造函数(了解即可)
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。public TreeMap() {comparator = null;}创建的TreeMap包含Mappublic TreeMap(Map<? extends K, ? extends V> m) {comparator = null;putAll(m);}指定Tree的比较器public TreeMap(Comparator<? super K> comparator) {this.comparator = comparator;}创建的TreeSet包含copyFrompublic TreeMap(SortedMap<K, ? extends V> m) {comparator = m.comparator();try {buildFromSorted(m.size(), m.entrySet().iterator(), null, null);} catch (java.io.IOException cannotHappen) {} catch (ClassNotFoundException cannotHappen) {}}
我们可以看出每个构造方法内部都指定了Comparator,TreeMap有序是通过Comparator来进行比较的,如果comparator为null,那么就使用自然顺序。如果value是整数,自然顺序指的就是我们平常排序的顺序1、2、3、4、5这种。
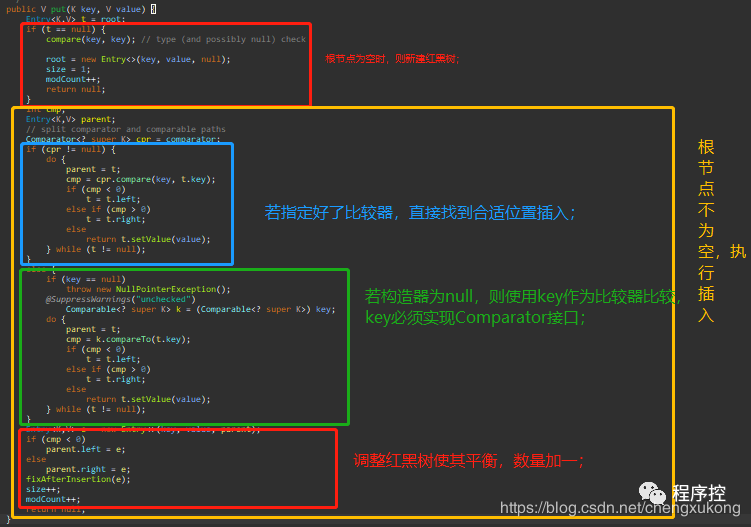
2、put()方法:放入对象
我们来看看TreeMap的核心put方法,读懂了这个就可以了解TreeMap的精髓了~
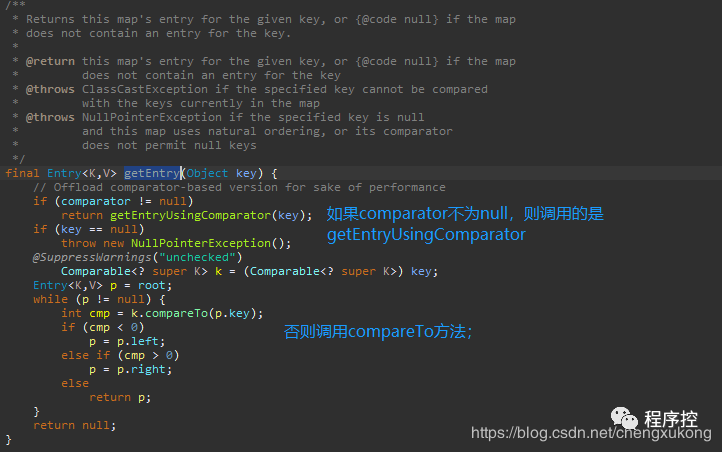
3、get()方法:根据Key获取Value

再进入getEntry()方法研究研究:
4、remove():移除对应元素
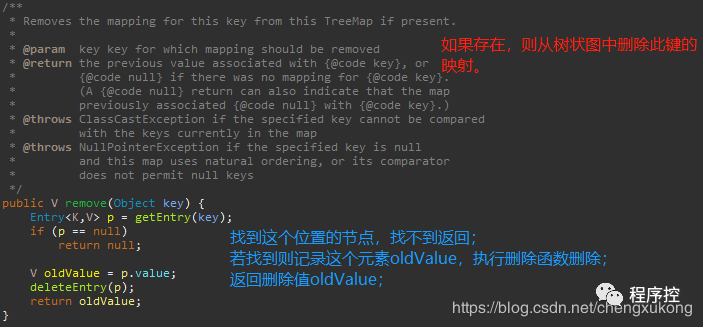
删除节点的时候调用的是deleteEntry(Entry<K,V> p)方法,这个方法主要是删除节点并且平衡红黑树。
5、clear():清空

TreeMap特点,应用场景?
TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)
2、LinkedHashMap剖析
LinkedHashMap定义:
public class LinkedHashMap<K,V> extends HashMap<K,V>implements Map<K,V> { }
LinkedHashMap简介:
LinkedHashMap增加了时间和空间上的开销,底层通过一个一个双向链表保证了元素迭代的顺序,迭代顺序可以是插入顺序或者访问顺序。
LinkedHashMap允许Key和Value为空,非线程安全的。 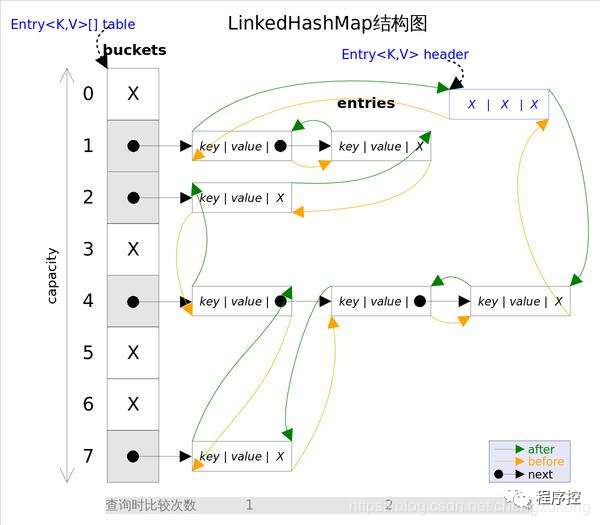
上面图为LinkedHashMap整体结构图,内部的循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点。
迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。
先来了解下LinkedHashMap的属性~
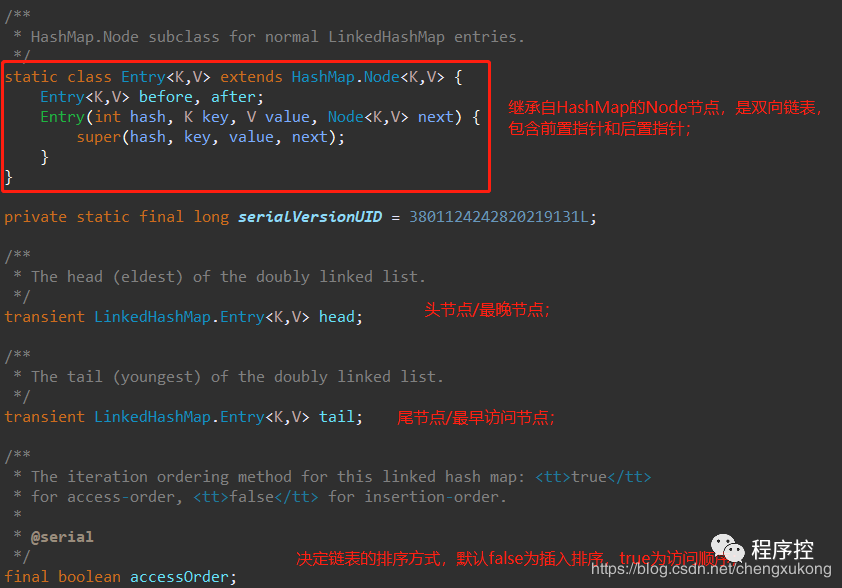
我们看到属性:Entry继承自HashMap的Node节点,包含前置指针和后置指针;头结点head和尾节点tail;
还有一个很重要的boolean型属性accessOrder,决定链表的排序方式,默认false为插入排序(head和tail存储头节点和尾节点),true为访问顺序(head为最晚访问,tail为最早访问)。
构造函数
// 构造一个初始容量和负载因子的、按照插入顺序的LinkedListpublic LinkedHashMap(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor);accessOrder = false;}// 构造一个初始容量的LinkedHashMap,取得键值对的顺序是插入顺序public LinkedHashMap(int initialCapacity) {super(initialCapacity);accessOrder = false;}// 用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序public LinkedHashMap() {super();accessOrder = false;}// 通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值public LinkedHashMap(Map<? extends K, ? extends V> m) {super();accessOrder = false;putMapEntries(m, false);}// 根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMappublic LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {super(initialCapacity, loadFactor);this.accessOrder = accessOrder;}
我们可以看出前四个都默认了accessOrder 参数为false,则链表的顺序则是插入顺序,只有最后一个构造方法,可以传入accessOrder 参数,true的时候则是按照访问顺序来排序底层链表的。
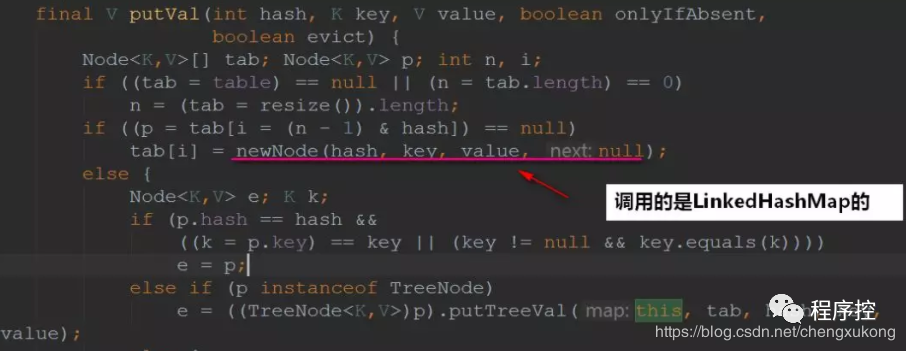
put():放入元素

是不是看着眼熟~~,没错,就是HashMap的put方法,我们调用LinkedHashMap的put方法的底层会调用HashMap的put方法来操作
但是,其中在putVal()创建节点的时候,调用的是LinkedHashMap重写的方法。
get():获得元素
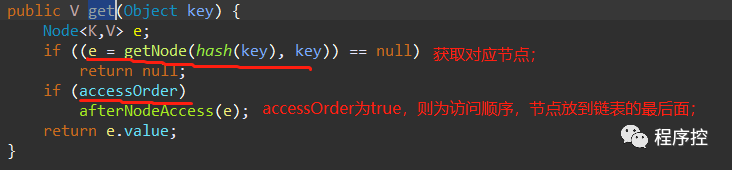
如果true,则为访问顺序(head为最晚访问,tail为最早访问),进去afterNodeAccess方法看:
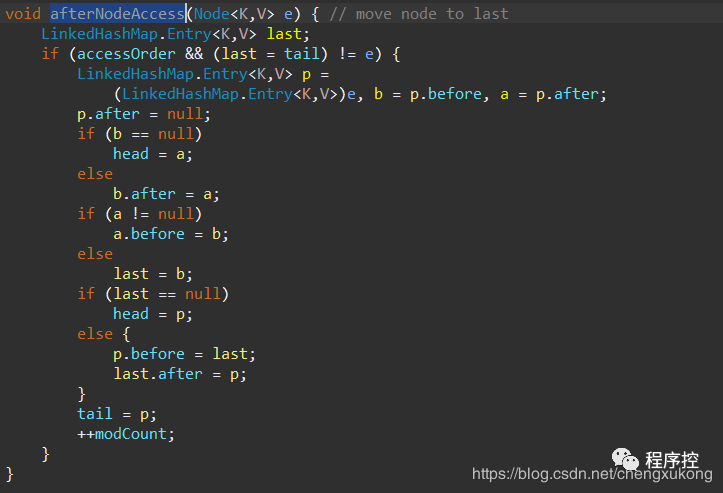
其实这个很好理解了,内部就是操作链表,将节点插入到链表的最末尾
remove()方法:移除元素
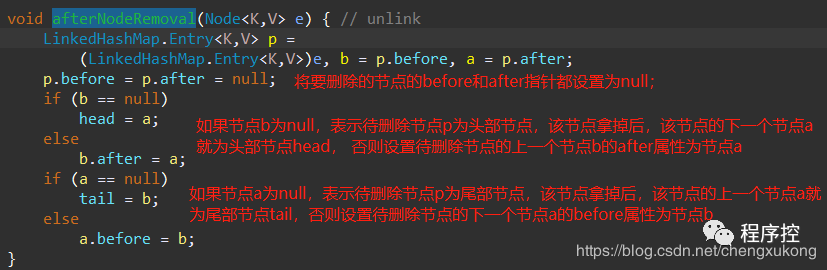
对于remove方法,在LinkedHashMap中没有重写,它调用的是父类的HashMap的remove()方法,在LinkedHashMap中重写的是:afterNodeRemoval(Node<K,V> e)这个方法,我们看下HashMap的内部就明白了~

原来这里面定义好了,接下来我们看afterNodeRemoval()这个方法
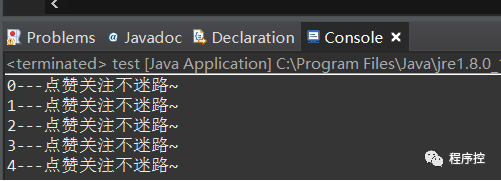
光说不干假把式,测试一波插入顺序和访问顺序的遍历帮助大家理解~
LinkedHashMap<Integer, String> test = new LinkedHashMap<>();String value = "点赞关注不迷路~";for (int i = 0; i < 5; i++) {test.put(i, value);}// 遍历Set<Integer> set = test.keySet();for (Integer s : set) {String mapValue = test.get(s);System.out.println(s + "---" + mapValue);}
得到测试结果:(插入的顺序和我们遍历得到的顺序一样,即默认false的插入顺序)
接着,我们来测试一下以访问顺序来进行插入和遍历
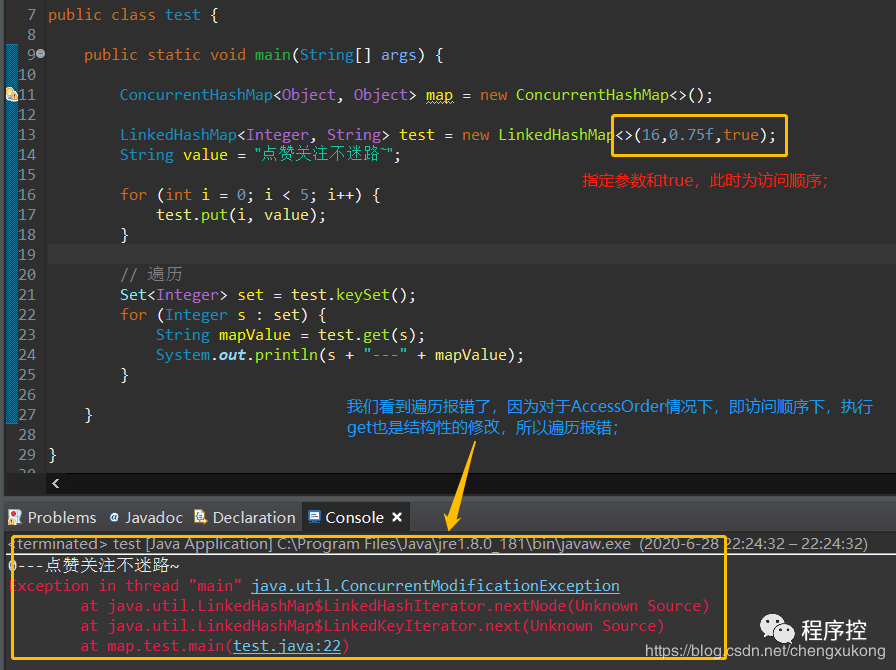
代码看似是没有问题,但是运行会出错的!在顺序访问下,使用get方法获取value值也是结构性的修改;
因为在访问顺序下,执行get也是结构性的修改(需要根据访问时间修改),所以变遍历并发修改异常,换种方式来看看效果:
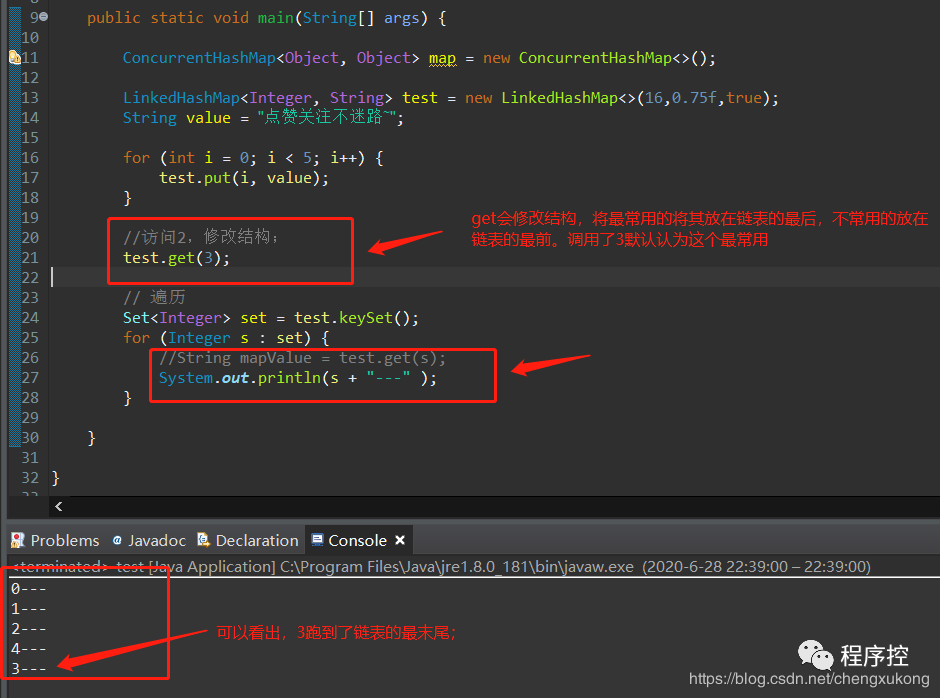
唠叨两句访问顺序
个人感觉访问顺序不重写用处不大,因为最常被使用的元素再遍历的时候却放在了最后边,在LinkedHashMap中我也没找到对应的方法来进行调用。
一个removeEldestEntry()方法,重写它可以删除最久未被使用的元素。一个是afterNodeInsertion()方法,新增时判断是否需要删除最久未被使用的元素。
利用LinkedHashMap实现LRU算法缓存
忘了LRU算法?🆗,我先来帮助大家回忆下,坐稳~
LRU,即Least Recently Used,最近最久未使用法。即最近使用的页面数据会在未来一段时期内仍然被使用,已经很久没有使用的页面很有可能在未来较长的一段时间内仍然不会被使用。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。Redis里面的缓存淘汰机制也有这个思想~
在计算机中大量使用了这个机制,它的合理性在于优先筛选热点数据,所谓热点数据,就是最近最多使用的数据!因为,利用LRU我们可以解决很多实际开发中的问题,并且很符合业务场景。
如下代码所示,一个简单的缓存:
public class LRUCache extends LinkedHashMap {private static final long serialVersionUID = 1L;protected int maxElements;public LRUCache(int maxSize) {super(maxSize, 0.75F, true);// 传入指定的缓存最大容量maxElements = maxSize;}//实现LRU的关键方法,如果map里面的元素个数大于了缓存最大容量,则删除链表的顶端元素protected boolean removeEldestEntry(java.util.Map.Entry eldest) {return size() > maxElements;}}
这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。
LinkedHashMap可以实现LRU算法的缓存基于两点:
提供了上述的第五个构造方法,可以让用户指定实现LRU。
三、总结
总结下TreeMap~
TreeMap底层是红黑树,能够实现Map集合有序,方法的时间复杂度都不会太高:log(n)
TreeMap是非同步的。它的iterator 方法返回的迭代器是fail-fast的。
若在构造方法中传递了Comparator对象,那么就会以Comparator对象的方法进行比较。
否则,则使用Comparable的
compareTo(T o)
方法来比较。
总结下LinkedHashMap~
LinkedHashMap 是LinkedList+HashMap,它是线程不安全的,允许key为null,value为null。 继承自HashMap,内部维护了一个双向链表
可以设置两种遍历顺序:访问顺序和插入顺序,默认是插入顺序的
LinkedHashMap遍历的是内部维护的双向链表,所以说初始容量对LinkedHashMap遍历是不受影响的
絮叨叨
你知道的越多,你不知道的也越多。
建议:多读书,多看视频,少吃零食,多撸代码



