





原文地址: https://github.com/ipfs/ipfs/blob/master/papers/ipfs-cap2pfs/ipfs-p2p-file-system.pdf
摘要
星际文件系统(IPFS)是一种点对点的分布式文件系统,旨在使用相同的文件系统连接所有的计算机设备。在某些方面,IPFS类似于Web,但是IPFS可以被看作是一个独立的BitTorrent群,而且支持在同一个Git仓库中可交换对象。换而言之,IPFS提供了一种高吞吐的基于内容寻址的区块存储模型和基于内容寻址的超链接。这形成了一个广义的默克尔有向无环图(Merkle DAG)数据结构,在它上面可以构建版本化文件系统,区块链,甚至是永久性网站。IPFS结合了分布式哈希表,激励块交换和自认证命名空间。IPFS没有单点故障,而且节点之间不需要相互信任。
1.介绍
在构建全球化的分布式文件系统方面,已经有了很多尝试。有些系统已经取得了重要的成功,而另一些系统却彻底失败了。在众多的学术尝试中,AFS[6]已经取得了广泛成功,一直使用到现在。其他的[7,?]就没有获得一样的成功。在学术之外,最成功的系统是点到点的文件共享应用系统,主要面向大型媒体(音频和视频)。最值得注意的是,使用Napster,KaZaA和BitTorrent[2]部署的大型文件分发系统支持超过1亿用户同时在线。即使在今天,BitTorrent仍维持着一个日活数以千万节点的大规模部署[16]。通过这些应用系统可以看到,对比相应的学术性文件系统它们有更多的用户量和文件被分发。但是,这些应用系统并不是作为基础设施来设计的。虽然它们已经被一些系统成功的重新组合,但还没有出现全球化、低延迟、去中心化分发的通用文件系统。
也许是因为对于大多数场景已经有一个"足够好"的系统:HTTP。到目前为止,HTTP是过去被部署最成功的"文件分发系统"。结合浏览器,HTTP已经有巨大的技术和社会影响力。它已经成为了互联网传输文件的实际方式。然而,它没有采用最近15年的很多先进的文件分发技术。从一方面看,鉴于向后兼容性的限制协议条数和在当前模式中强大的参与者的投入,逐步发展Web基础架构几乎是不可能的。但是从另一方面看,从HTTP出现以来,已经出现了许多新的协议而且得到了广泛使用。缺乏的是升级设计:增强当前HTTP网络,和引入新的功能并且不降低用户体验。
行业长期使用HTTP,因为移动小文件相对廉价,甚至对于流量很大的小组织也是如此。但是,随着新的挑战,我们正在进入一个新的数据分发时代:(a)托管和分发PB级数据集, (b)跨组织的大数据计算,(c)大容量高清晰度按需或实时媒体流,(d)海量数据集的版本化和链接,(e)防止重要文件意外丢失,等等。其中许多可以归结为"大量数据,随处访问"。在关键特性和带宽问题的压力下,我们已经放弃了HTTP,而使用不同的数据分发协议。下一步是使它们成为网络本身的一部分。
与有效数据分发相正交,版本控制系统已经设法开发了重要数据协作工作流。Git,分布式源代码版本控制系统,开发了许多有用的方法来建模和实现分布式数据操作。Git工具链提供了多种版本控制功能,这正是大型的文件分发系统所严重缺乏的。受Git启发的新解决方案正在兴起,如Camlistore [?],一个个人文件存储系统,以及Dat [?]一个数据协作工具链和数据集包管理器。Git已经影响了分布式文件系统设计[9],因为它的内容寻址Merkle DAG数据模型可以实现强大的文件分发策略。还有待探讨的是,这种数据结构如何影响高吞吐量文件系统的设计,以及它如何升级Web本身。
本文介绍了IPFS,一种新颖的对等网络版本控制的文件系统,旨在调和这些问题。IPFS综合了过去许多成功系统的经验。精心专注于接口整合生成的一个系统的效果比各个部件的总和要好。IPFS的核心原则是将所有数据建模为同一Merkle DAG的一部分。
本节回顾了成功的对等系统的重要特性,而IPFS正是结合了这些特性。
分布式哈希表(DHT)被广泛用于协同和维护关于对等系统的元数据。例如,BitTorrent MainlineDHT用来跟踪一个种子群组里的对等节点。
2.1.1 KADEMLIA DHT
Kademlia[10](卡德米利亚)是一种流行的分布式哈希表(DHT),它提供了:
1. 大规模网络的高效查询:平均查询 [log2(n)] 节点。(例如,对于10,000,000个节点的网络只需要20跳)。
2. 低协调开销:它优化了发送给其他节点的控制消息的数量。
3. 通过优先选择长期在线节点来抵抗各种攻击。
4. 在对等应用中广泛使用,包括Gnutella和BitTorrent,形成了超过2000万个节点的网络[16]。
虽然一些对等文件系统直接在DHT中存储数据块,这"浪费了存储和带宽,因为数据存储在不需要的节点上"[5]。Coral DSHT在3个特别重要的方面扩展Kademlia:
1. Kademlia将值存储在ids与键值"最近"(使用XOR-distance计算距离)的节点中。这没有考虑应用程序数据局部性,忽略了"远程"节点可能已经有数据,并强制“最近”的节点存储数据,无论它们是否需要。这浪费了大量的存储和带宽。取而代之,Coral存储的是可以提供数据块的节点地址。
2. Coral扩大了DHT API,修改get_value(key)
为get_any_values(key)
(DSHT中的"sloppy")。
Coral用户只需要一个(在线)节点,而不是列表中所有的节点就可以正常工作。在返回结果中,Coral可以分发的仅是值的子集到"最近"的节点,避免热点(当某个key变得流行时,重载所有最近的节点)。
3. 此外,Coral根据区域和大小规划了一个隔离的DSHT层次结构,称为集群。这使得节点首先查询它们区域中的节点,"查找附近的数据而不查询远程节点"[5]从而大大减少查找的延迟。
# begin
#上述说明有点不好理解,加点注释
<-- 在Kademlia协议中,数据会直接保存到XOR更近的节点。但实际情况是,如果某些数据非常流行,其他节点也会大量查询,会因此造成拥塞,我们称为Hot-Spot -->
<-- Coral在每次寻址之后都会指定某个或某些节点短暂保存上次寻址的节点地址,以防止每次寻址都要重载一遍节点(即重新寻找一次) -->
<-- 在Coral中,将DSHT分成了三层,Level2对应两两延迟小于20ms,Level1对应两两延时小于60ms,Level0对应其他的全部节点 -->
# end
S/Kademlia [1]在两个特别重要的方面扩展了Kademlia,来防止恶意攻击。
1. S/Kademlia提供了保护NodeId生成和防止女巫(Sybill)攻击的方案。它要求节点生成KPI密钥对,从中派生它们的身份,并且互相签署它们的消息。一种包含一个工作证明密码难题的方案,使得生成女巫攻击的成本高昂。
2. S/Kademlia节点在不相交的路径上查找值,确保在网络中存在大量的不诚实节点的情况下,诚实节点也可以互相连接。甚至在恶意节点高达一半时,S/Kademlia也能达到0.85的成功率。
# begin
#上述说明有点不好理解,加点注释
<-- S/K节点ID的分配策略有三个:不能自由选择,不能大量生成,不能窃取和伪装-->
<-- S/K提出每次查询选择k个节点,放入d个不同的Bucket中。这个d个Bucket进行查找,d条查询路径做到不相交,单个bucket有实效的可能,但是只要d个bucket中有一条查询到了需要的信息,工作就完成了。通过不相交路径查询,解决了敌对路由攻击。-->
# end
BitTorrent[3]是一个非常成功的点对点文件共享系统,它成功地协调了不信任的对等网络节点(集群)相互分发文件块。从BitTorrent和它的生态系统的关键特征,IPFS得到启示如下:
1. BitTorrent的数据交换协议使用了类似针锋相对(tit-for-tat)的策略,即奖励贡献节点,惩罚只索取的节点。
2. BitTorrent节点会跟踪文件块的可用性,优先发送最稀缺的文件块。这减轻了种子节点的负担,使得非种子节点能相互交换数据(交易)。
3. 对于一些剥削带宽共享策略, BitTorrent的标准tit-for-tat策略是非常脆弱的。PropShare[8]是一种不同的对等带宽分配策略,可以更好地抵抗剥削性策略,提高集群的性能。
版本控制系统提供了随时间发生改变的文件进行建模的设施,并有效地分发不同的版本。流行的版本控制系统Git提供了强大的默克尔有向无环图(Merkle DAG)2 对象模型,以分布式友好的方式捕获文件系统树的变更。
1. 不可变更的对象表示文件(blob),目录(tree)和更改(commit)。
2. 对象通过内容的加密哈希散列来寻址内容。
3. 链接其他被嵌入的对象,形成一个Merkle DAG。这提供了许多有用的完整性和工作流属性。
4. 大多数版本元数据(分支、标签等)都只是指针引用,因此创建和更新的代价非常低。
5. 版本改变只是更新引用或者添加对象。
6. 向其他用户发布版本改变只是简单的传输对象和更新远程引用。
2.4 自我认证认文件系统 – SFS
/sfs/:‹Location›:‹HostID›
其中Location是服务器网络地址,而且:
HostID = hash(public_key || Location)
3. IPFS设计
IPFS是一个分布式文件系统,它综合了以前的对等系统成功的思想,包括DHTs,BitTorrent,Git和SFS。IPFS的贡献在于通过简化和演化的方式将已被验证的技术整合成在一个单一的内聚系统,而不只是简单的累加。IPFS为编写和部署应用提供了一个新平台,以及为大型数据的分发和版本管理提供了一个新系统。IPFS甚至可以进化自身网络。
IPFS是对等的;没有任何有特权节点。IPFS的节点在本地存储IPFS对象。节点之间互相连接并传输对象。这些对象表示文件和其他数据结构。IPFS协议被分为一个负责不同功能的子协议栈:
1. 身份 - 管理节点身份生成和验证。在3.1节描述。
2. 网络 - 管理与其他节点的连接,使用各种底层网络协议。配置化。在3.2节描述。
3. 路由 - 维护信息用来定位具体的节点和对象。响应本地和远程的查询。默认为DHT,但可更换。在3.3节描述。
4. 交换 - 一种新型块交换协议(BitSwap), 能控制有效块的分布。模拟市场,弱激励数据复制。交易策略可替换。在3.4节描述。
5. 对象 - 一张通过不可变对象连接形成的按内容寻址的默克尔有向无环图(Merkle DAG)。用于表示任意数据结构,例如,文件层次和通信系统。在3.5节描述。
6. 文件 - 受Git启发的版本化文件系统层次结构。在3.6节描述。
7. 命名 - 自我认证的可变名称系统。在3.7节描述。
3.1 身份
type NodeId Multihash
type Multihash []byte
// self-describing cryptographic hash digest
type PublicKey []byte
type PrivateKey []byte
// self-describing keys
type Node struct {
NodeId NodeID
PubKey PublicKey
PriKey PrivateKey
}
基于S/Kademlia的IPFS身份生成:
difficulty = ‹integer parameter›
n = Node{}
do {
n.PubKey, n.PrivKey = PKI.genKeyPair()
n.NodeId = hash(n.PubKey)
p = count_preceding_zero_bits(hash(n.NodeId))
}
第一次连接时,节点相互交换公钥,并进行检查:hash(other.PublicKey) 等于other.NodeId.。如果不等于,终止连接。
加密函数的注意事项:
IPFS更喜欢自描述的值,而不是锁定系统到一组特定的函数选择中。哈希摘要的值被存储在一个多重哈希格式中,它包括一个指明所使用的哈希函数的短头部,以及摘要长度。例如:
<function code><digest length><digest bytes>
它允许系统(a)根据使用情况选择最佳函数(例如:安全性更强VS性能更快),(b)随着功能选择的变化而演变。自描述值允许兼容使用不同的参数选择。
3.2 网络
IPFS节点与网络中的其他数百个节点定期通信,可能跨越广域网。IPFS网络栈的特点:
传输: IPFS可以使用任何传输协议,它最适合WebRTC DataChannels [?] (浏览器连接)或 uTP(LEDBAT [14])。
可靠性: 如果底层网络不提供可靠性,IPFS可以通过uTP (LEDBAT [14])或SCTP [15]提供可靠性。
连通性: IPFS还使用了ICE NAT遍历技术[13]。
完整性: 可以使用哈希校验和来检查消息的完整性。
真实性: 可以使用HMAC和发送者的公钥检查消息的真实性。
3.2.1 对等节点寻址注意事项
IPFS可以使用任何网络; 它不依赖或者直接访问IP层。这允许在覆盖网络中使用IPFS。IPFS将地址存储为多重地址(multiaddr)格式的
字节字符串,以便于给底层网络使用。multiaddr
提供了一种用来表示地址及其协议的方法,包括对封装的支持。例如:
# an SCTP/IPv4 connection ip4/10.20.30.40/sctp/1234/ # an SCTP/IPv4 connection proxied over TCP/IPv4 ip4/5.6.7.8/tcp/5678/ip4/1.2.3.4/sctp/1234/
3.3 路由
IPFS节点需要一个路由系统, 这个路由系统可以查找:(a)其他节点的网络地址和(b)可以服务特定对象的节点。IPFS使用一张基于S/Kademlia和Coral的DSHT实现这个功能,在2.1节中有过具体介绍。IPFS的对象大小和使用规模类似于Coral [5] 和Mainline
[16],因此,IPFS DHT根据其大小对存储的值进行划分。小的值(等于或小于1KB
)直接存储在DHT上。对于更大的值,DHT只存储值索引组,这个索引组就是可以为块服务的节点们的NodeIds。
DSHT的接口如下:
type IPFSRouting interface { FindPeer(node NodeId) gets a particular peer's network address SetValue(key []bytes, value []bytes) stores a small metadata value in DHT GetValue(key []bytes) retrieves small metadata value from DHT ProvideValue(key Multihash) announces this node can serve a large value FindValuePeers(key Multihash, min int) gets a number of peers serving a large value }
注意:不同的情况要求非常不同的路由系统(例如广域网中使用DHT,局域网中使用静态HT)。因此,IPFS路由系统可以根据用户的需求替换合适的。只要满足使用上面的接口,系统都能继续正常运行。
3.4 块交换 – Bitswap协议
在IPFS中,数据分发通过节点之间交换块来实现的,使用一个受BitTorrent启发的协议: BitSwap。和BitTorrent一样,BitSwap节点们在寻求一组块(want_list)时,另一组块可以提供交换(have_list)。与BitTorrent不同的是,Bitswap不局限于某个Torrent中的块。BitSwap作为一个持续市场运行,节点可以从中获取它们需要的块,而不管这些块是什么文件的一部分。在文件系统中,这些数据块可能来自完全不相关的文件。在市场上,节点聚集在一起进行交换。
虽然易货系统意味着可以创建虚拟货币,但这需要一个全局账本来跟踪和转移货币所有权。这可以作为一种BitSwap策略实现,在下文中会进一步阐述。
基本情况,BitSwap节点之间必须以块的形式互相提供直接值。当数据块在不同节点之间的分布是互补的,也就是说节点之间互相拥有对方想要的数据块的时候,这时才会工作的很好。但通常来说,情况并非如此。在有些情况下,节点必须为他们自己的块工作。如果一个节点没有其他节点所需的(或根本没有的)的数据块,它会以比节点自己想要的块更低的优先级去寻找其他节点想要的块。这会激励节点去缓存和传播稀有片段,即使节点对这些片段不感兴趣。
3.4.1 Bitswap 信用
这个协议必须也要激励节点去传播,尤其当他们不需要任何东西的时,因为他们也许拥有别人想要的块。因此,BitSwap节点会很积极去给它们的节点发送块,期待获得报酬。但是,必须防止水蛭攻(从不共享的自由下载节点)。一个简单的类似信用系统的方案,解决了这个问题:
1. 对等节点间会(通过验证字节数)互相跟踪他们之间的平衡程度。
2. 在概率上,根据一个随负债的增加而下降的函数,节点们向负债节点发送块。
注意,如果一个节点决定不发送到另一个节点,这个节点随后会忽略另一个节点的ignore_cooldown超时。这样可以防止发送者试图仅仅通过多次尝试而成功(BitSwap默认是10秒)。
3.4.2 Bitswap 策略
Bitswap节点采用的不同策略会对交易的整体表现有截然不同的影响。在BitTorrent中,虽然指定了一个标准策略(以牙还牙),但还实现了其他多种策略,从BitTyrant[8](尽可能共享),到BitThief[8](利用漏洞而从不共享),到PropShare[8](按比例共享)。一系列策略(好的和恶意的)同样可以由Bitswap节点实现。因此,功能选择应旨在:
1. 最大化节点的交易性能和整体的交换能力。
2. 防止某些只下载的节点利用和降低交换。
3. 有效应对和抵抗其他未知策略。
4. 对可信节点宽容。
未来,我们将对这些策略的空间进行探索。在实践工作中,一个功能选择是sigmoid,根据负债比例进行缩放:
在实践工作的一种功能选择是由Debt Retio缩放的Sigmoid
在实践中使用的一个选择性功能是sigmoid,根据负债率进行缩放:
让一个节点和其他对等节点的负债率r为:

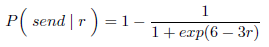

负债率是一种信用的度量:对之前有过大量数据成功交换的节点之间的债务宽容,而对未知、不受信任的节点毫不留情。这样(a)抵抗能创建大量新节点的攻击者(Sybill攻击),(b)保护之前成功交易关系,即使这个节点暂时无法提供价值,以及(c)最终会扼杀已经恶化的关系,直到它们有所改善。
3.4.3 BitSwap 账本
type Ledger struct {
owner NodeId
partner NodeId
bytes_sent int
bytes_recv int
timestamp Timestamp
}
3.4.4 BitSwap 详解
// Additional state kept
type BitSwap struct {
ledgers map[NodeId]Ledger
Ledgers known to this node, inc inactive
active map[NodeId]Peer
currently open connections to other nodes
need_list []Multihash
checksums of blocks this node needs
have_list []Multihash
checksums of blocks this node has
}
type Peer struct {
nodeid NodeId
ledger Ledger
Ledger between the node and this peer
last_seen Timestamp
timestamp of last received message
want_list []Multihash
checksums of all blocks wanted by peer
includes blocks wanted by peer's peers
}
// Protocol interface:
interface Peer {
open (nodeid :NodeId, ledger :Ledger);
send_want_list (want_list :WantList);
send_block (block :Block) -> (complete :Bool);
close (final :Bool);
}
对等连接的生命周期草图:
1. Open: 节点间发送分类账本ledgers直到互相接受。
2. Sending: 节点间交换want_lists 和blocks。
3. Close: 节点断开链接。
4. Ignored: (特殊情况下)如果一个节点采取避免发送的策略,对等节点被忽略(在超时期间)。
Peer.open(NodeId, Ledger).
当连接时,节点会使用一个Ledger初始化一个连接,该Ledger要么是从过去连接存储的,要么是一个新的被清零的。然后,向对等节点发送一条携带Ledger的公开消息。
在接收到Open消息时,对等节点可以选择是否接受此链接。如果(根据接受者的Ledger判断)发送者不是可信任的代理(传输低于零或者有很大的未偿还的债务),接收卡可以选择忽略这个请求。这应该以ignore_cooldown超时的概率完成,以便纠正错误并阻止攻击者。
如果连接成功,接收者用本地Ledger版本来初始化一个Peer对象以及设置last_seen时间戳。然后,将收到的Ledger与自己的分类账进行比较。如果两个账本完全一样,那么这个连接就被打开。如果账本不完全一致,那么此节点会创建一个新的被清零的账本并发送此账本。Peer.send_want_list(WantList)
当连接打开时,节点会广播他们的want_list给所有连接的对等节点。这种广播情况会发生在(a)打开连接时,(b)随机周期超时后,(c)在want_list改变后,和(d)在接收到一个新块后。
Peer.send_block(Block)
Peer.close(Bool)
关闭信号的最后一个参数表示断开连接的意图是否是发送方发起的。 如果为假,接收方可以选择立即重新打开连接。 这样可以避免过早关闭。
在以下两种情况下,一个对等节点连接被关闭:
silence_wait有效期超时,但未从对等节点接收任何消息(默认BitSwap使用30秒)。 节点发出Peer.close(false)。
该节点正在退出并且BitSwap正在关闭。在这种情况下,节点将发出Peer.close(true)。
关闭消息后,接收方和发送方都断开连接,清除所有已存储状态。 如果有必要的话,Ledger会保存为将来使用。
注意
非活动连接上的未open消息应被忽略。如果有一个send_block消息,接收方可以检查块是否需要和正确,如果符合,使用它。 不管怎样,所有这类乱序消息都会从接收方触发一条close(false)消息,以强制重新初始化连接。
3.5 Merkle DAG对象
内容寻址: 所有内容通过它的多重哈希校验唯一确认,包括链接。
防篡改: 所有内容都要通过它的校验和进行验证。如果数据被篡改或者损坏,IPFS会检测到。
重复数据删除: 所有具有完全相同内容的对象是一样的,并且只存储一次。这对索引对象或数据的公共部分非常有用,例如git trees和commits。
type IPFSLink struct {
Name string name or alias of this link
Hash Multihash cryptographic hash of target
Size int total size of target
}
type IPFSObject struct {
links []IPFSLink array of links
data []byte opaque content data
}
列出对象中的所有对象引用。例如:
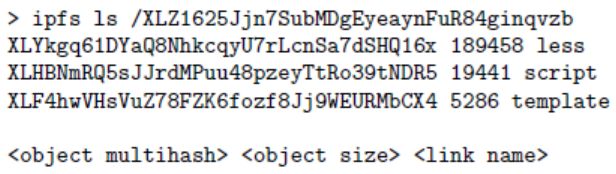
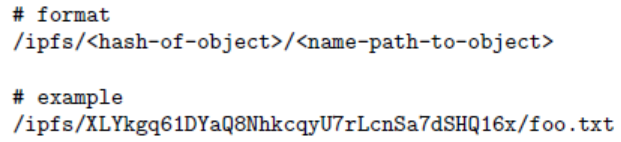
解决字符串路径查找,例如foo/bar/baz。给定一个对象,IPFS解析第一个路径组成部分为对象链接表中的一个哈希值,获取第二个对象,并与路径接下来的组成部分一直重复下去。因此,无论什么数据格式,字符串路径可以遍历Merkle DAG。
解决所有递归引用对象:

3.5.1 路径
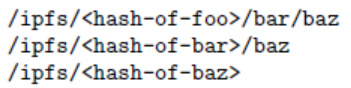
3.5.2 本地对象
3.5.3 对象固定
3.5.4 发布对象
3.5.5 对象级加密
type EncryptedObject struct {
Object []bytes raw object data encrypted
Tag []bytes optional tag for encryption groups
}
type SignedObject struct {
Object []bytes raw object data signed
Signature []bytes hmac signature
PublicKey []multihash multihash identifying key
}
3.6 文件
block: 可变大小的数据块。
list: 块或其他列表的集合。
tree: 块,列表或其他树的集合。
commit: 一棵树的版本历史记录的一个快照。
3.6.1 文件对象: blob
{
"data": "some data here", blobs have no links
}
3.6.2 文件对象: list

3.6.3 文件对象: tree
3.6.4 文件对象: commit


3.6.5 版本控制
3.6.6 文件系统路径
3.6.7 拆分文件为list和blob
就像在LIBFS[?]中一样使用Rabin Fingerprints [?]来选择一个比较合适的块边界。
使用rsync[?] rolling-checksum算法,来检测块在版本之间的改变。
允许用户针对特定文件指定高度优化的块拆分函数。
3.6.8 路径查找性能
基于路径访问变量对象图。检索每个对象都需要在DHT中查找它的密钥,连接到对等节点,并检索它的块。这是相当大的开销,尤其当查找路径包含许多组件时。这可以通过以下方法缓解:
tree caching: 由于所有对象都是哈希寻址的,它们可以被无限的缓存。此外,树在大小上通常较小,因此IPFS优先缓存它们而不是blob。 flattened trees: 对于任何给定的树,可以构造一棵特殊扁平的树用来列出从树中可以到达的所有对象。扁平树中的名字就是从原始树里分隔的路径,使用斜线分隔。

3.7 IPNS: 命名及可变状态
对象是永久的
这些是一个高性能分布式系统的关键属性,在这种分布式系统中,跨网络链路传输数据非常昂贵。对象内容寻址构建一个(a) 显著的带宽优化,(b) 不受信任的内容服务,(c) 永久链接, 和(d) 对任何对象及它的引用进行完整永久备份的能力的web。
3.7.1 自认证名称
回想一下在IPFS中:
NodeId = hash(node.PubKey)我们为每个用户分配一个可变的命名空间:
/ipns/<NodeId>用户可以发布一个用他的私钥签名的对象到这个路径,例如:
/ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm/当其他用户检索对象时,他们可以检查签名是否与公钥和NodeId相匹配。这验证了用户发布的对象的真实性,实现了可变状态的检索。
注意以下详情:
ipfs(行星际名称空间)单独的前缀是为程序和普通人读者在可变和不可变路径间建立一个容易辨认的区别。
因为这不是一个基于内容寻址的对象,所以发布它依赖于IPFS中唯一的可变状态分发系统,即路由系统。流程是(1) 将对象作为一个常规不可变的IPFS对象发布,(2) 将它的哈希在路由系统上作为一个元数据发布:
routing.setValue(NodeId, <ns-object-hash>)
发布的对象中的任何链接在命名空间中都作为子名称:

建议发布一个提交对象或其他具有版本历史记录的对象,以便客户端可以找到旧名称。由于它并不总是需要,因此保留作为一个用户选项。
注意当多个用户发布这个对象时,不能使用相同的方式发布它。
3.7.2 人性化名称
对等链接

DNS TXT IPNS记录
/ipns/<domain>是一个有效的域名,IPFS在它的DNS TXT记录中查找密钥
ipns。IPFS将该值解释为一个对象哈希或另一个IPNS路径:

Proquint可读的标识
Proquint[?]。如下:

缩短名称服务

3.8 使用IPFS
作为一个挂载的全局文件系统,挂载在/ipfs和/ipns下。
作为一个挂载的个人同步文件夹,自动进行版本管理,发布,以及备份任何写入。
作为一个加密的文件或者数据共享系统。
作为一个所有软件版本的包管理器。
作为虚拟机的根文件系统。
作为一个VM的引导文件系统 (在管理程序下)。
作为一个数据库: 应用程序可以直接写入Merkle DAG数据模型,并获得IPFS提供的所有版本控制,缓存和分发。
作为一个链接(和加密)的通信平台。
作为一个为大文件的完整性检查的CDN(不使用SSL)。
作为一个加密的CDN。
在网页上,作为一个web CDN。
作为一个新的链接不会消失的永久性网站。
(a) 一个导入到你自己应用中的IPFS库。
(b) 直接操作对象的命令行工具。
(c) 使用FUSE[?]或者作为内核模块挂载到文件系统。
4. 未来
5. 致谢
