




作者简介

211工程院校贵州大学管理学院硕士研究生、互联网金融行业资深DevOps研发工程师. 曾在国内多家知名互联网公司 平安科技、微众银行、顺丰科技、魅族任职. 具有多年国内一线互联网公司自动化运维平台设计与开发经验。
前言:
比如一个用户注册的WEB页面中,当提交了用户的账号密码等信息之后,将会发送一封激活邮件至用户的电子邮箱。在该场景中用户点击注册按钮后http应立即返回响应而无需等待后续的邮件发送任务成功后才返回。这就可以用一种异步的形式去处理发送邮件这一任务,这种异步操作可以用队列服务来实现。否则如果用同步的方式等到邮件发送成功再对客户端进行http响应,那么在这段时间内,客户端的请求将会被卡住。
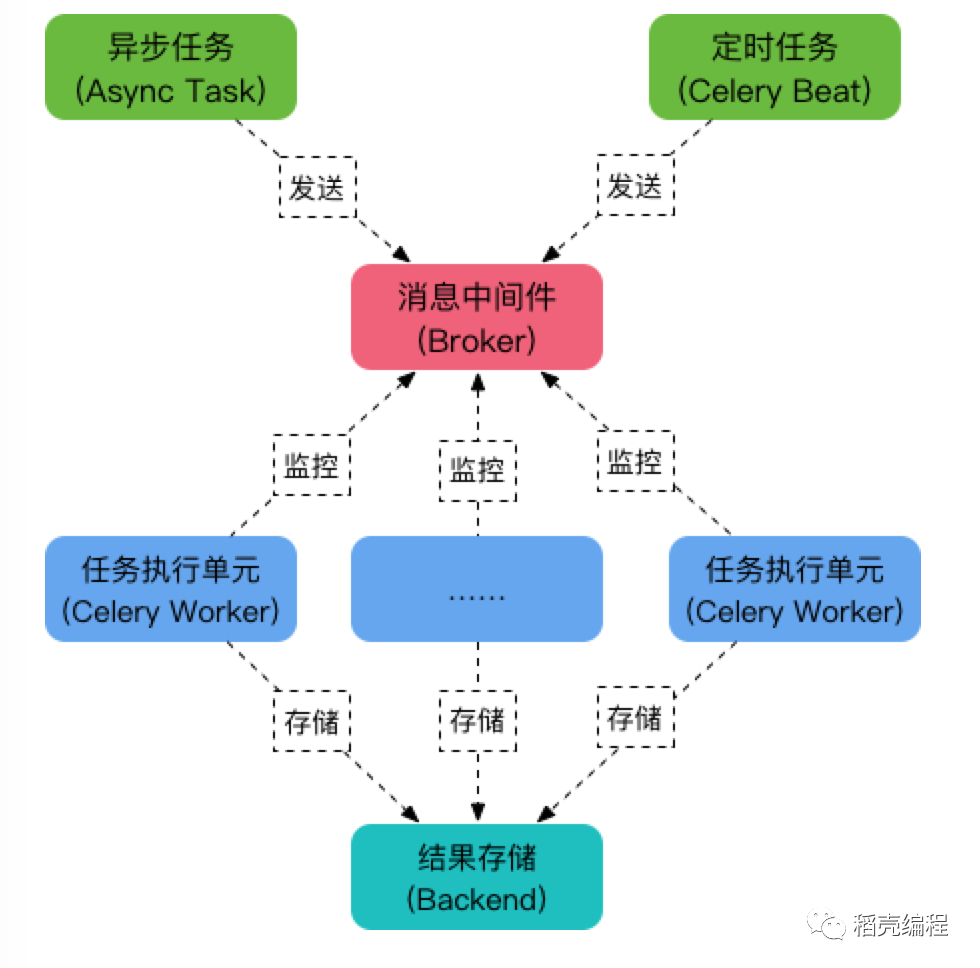
Celery是Python语言实现的分布式队列服务,可以用它来实现定时任务与异步任务,核心角色如下:
Task: 就是你要做的事情, 例如一个注册流程里面有很多任务, 给用户发验证邮件就是一个任务, 这种耗时任务可以交给Celery去处理; 还有一种任务是定时任务, 比如每天定时统计网站的注册人数, 这个也可以交给Celery周期性的处理。
Broker: 在Celery中它介于生产者和消费者之间, 这个角色相当于数据结构中的队列。例如一个Web系统中, 生产者是处理核心业务的Web程序,业务中可能会产生一些耗时的任务比如短信、邮件的发送等。生产者会将任务发送给Broker,就是把这个任务暂时放到队列中,等待消费者来处理。Celery本身不提供队列服务, 一般用Redis或者RabbitMQ来扮演Broker的角色。
Worker: 就是那个一直在后台执行任务的人, 也称为任务的消费者, 它会实时地监控队列中有没有任务, 如果有就立即取出来执行.消费者是Worker是专门用于执行任务的后台服务. Worker将实时监控队列中是否有新的任务, 如果有就拿出来进行处理.
Beat: 是一个定时任务调度器,它会根据配置定时将任务发送给Broker, 等待Worker来消费。
Backend: 用于保存任务的执行结果,每个任务都有返回值,比如发送邮件的服务会告诉我们有没有发送成功, 这个结果就是存在Backend中。
Celery架构如下图所示:
2.1 示例代码
import time
from celery import Celery, platforms
broker = 'redis://127.0.0.1:6379'
backend = 'redis://127.0.0.1:6379'
platforms.C_FORCE_ROOT = True
app = Celery(__file__, broker=broker, backend=backend)
@app.task
def add(x, y):
time.sleep(5)
return x + y2.2 代码说明
注:
在本例中Celery的backend和broker采用的方案均为redis.
推荐安装Python redis库的版文本为2.10.6,使用其他过于新的版本可能会有问题.
pip install redis==2.10.6
上面的代码做了几件事:
创建了一个Celery实例app task.py
指定消息中间件用redis, URL为redis://127.0.0.1:6379
指定存储用 redis, URL为redis://127.0.0.1:6379
创建了一个Celery任务add, 当函数被@app.task装饰后, 就成为可被 Celery 调度的任务。
2.3 运行Celery实例
celery worker -A tasks --loglevel=info
参数 -A 指定了Celery app的位置,本例是在 tasks.py 中,Celery会自动在该文件中寻找Celery对象实例
参数 --loglevel 指定了日志级别, 默认为 warning, 也可以使用 -l info 来表示.
现在,我们可以在应用程序中使用delay()方法来调用任务.
In [10]: from tasks import add
In [11]: t = add.delay(1, 2)
在上面, 我们从task.py文件中导入了add任务对象,然后使用delay()方法将任务发送到消息中间件(Broker),Celery Worker 进程监控到该任务后,就会进行执行,我们将窗口切换到Worker的启动窗口,会看到多了两条日志:

以上说明任务已经被调度并执行成功,可以看到虽然任务函数add需要等待5秒才返回执行结果,但由于它是一个异步任务,所以不会阻塞当前的主程序。
4.1 Celery实例关键启动配置项说明
当通过命令启动Celery实例时如:
指定worker工作方式为prefork
celery worker --app=worker.app --pool=prefork --concurrency=4
指定worker工作方式为Gevent
celery worker --app=worker.app --pool=gevent --concurrency=100
4.1.1 pool参数说明:
worker实例执行池的工作方式有以下几种,分别是 prefork(默认使用)、solo、eventlet、gevent,本文主要讨论prefork和gevent这两种实例启动方式,worker执行池pool参数的值如果未指定,默认采用的是prefork的方式。
prefork的运行基于python的multiprocessing包, 因为Python存在一个全局解释器所GIL, 也就是在任意时刻只能有一个线程在解释器中运行,所以Python的多线程是不能使用多CPU核心的,但是多进程可以规避GIL,能够更好的利用主机资源。如果Celery实例所执行的任务的类型是CPU密集型的,也就是这个任务的大部分时间都在进行CPU运算,这种情况下用prefork方式的pool将会得到性能上的提升;可用的CPU数量限制了并发进程数量,也就是并发的prefork数量不能多于CPU的核心数量,默认情况下celery会自动判断CPU核数,并启动相应数量的prefork,也可以通过参数concurrency来指定,但是concurrency参数的数值不应该超过当前主机的CPU核心数量。
当Celery的worker实例所执行的任务类型为IO密集型任务时,例如通过HTTP请求从RESTAPI获取数据时, 时间损耗主要在HTTP请求到服务器响应这个时间段内,这段时间没有用到CPU,时间的消耗主要存在于网络IO上,这种类型的任务就是一个IO密集型的任务。IO密集型的任务使用Gevent协程来实现并发可以大幅提升代码性能,由于gevent工作方式中的并发数量与CPU核数无关, concurrency参数的值可以相应设置大一些如100,如果不设置该参数,那么concurrency的默认值为CPU的核心数量,在gevent方式中采用如此低的concurrency是不明智的。
5.1. prefork模式下的内存溢出问题
现象celery worker启动时采用的Pool为prefork, 项目运行一段时间后,worker卡死, 具体表现在celery日志中提示receive Task, 但是该任务没有执行。在Google上搜索该情况,初步判定问题出在内存泄露上,worker在prefork模式下处理任务可能会出现死锁或内存泄露等情况。
解决方案:
配置max_tasks_per_child_settings该参数配置在使用prefork模式下的worker,该参数定义了每个worker能够执行的最大任务数量,当达到最大任务数之后就会被销毁重新创建新的worker 进程, 这个选项在遇到无法控制来自封闭源代码C扩展的内存泄漏时非常有用
max_memory_per_child 该参数配置在使用prefork模式下的worker,可以配置工作进程在被新进程替换之前可以执行的最大驻留内存量
time_limits 选项可以应用在prefork和gevent模式的pool下, 单个任务可能永远运行,如果有许多任务等待某个永远不会发生的事件,则会无限期地阻止工作进程处理新任务。防止这种情况发生的最佳方法是启用时间限制.
5.2.通过supervisor管理celery进程时需添加的配置项:
supervisord结合celery时 在supervisord中应该加入以下几个配置,通过supervisord重启celery时, 可能遇到进程杀的不完整的情况,通过加入以下两个参数可解决问题.
;stopasgroup=false 该参数要用于supervisord管理的子进程,这个子进程本身还有
子进程。那么我们如果仅仅干掉supervisord的子进程的话,子进程的子进程
有可能会变成孤儿进程。所以可以通过设置这个选项,把整个子进程的
整个进程组都干掉。设置为true的话,一般killasgroup也会被设置为true。
需要注意的是,该选项发送的是stop信号
默认为false。
;killasgroup=false ; 这个和上面的stopasgroup类似,不过发送的是kill信号。
6
结束语


