




单纯使用采样数据来生成报告显然是太浪费了,Statspack/AWR报告仅仅展示了采样数据的极小部分,通常我们可以利用采样的性能数据从多角度展现数据的运行状况。
如果延长一定的时间维度,就可以清晰的展现数据库的运行趋势。比如数据库可能较长时间内一直运行正常,可是正常之中也许蕴含了很多隐患,某条SQL的逻辑读可能超高了,也有可能某个SQL的执行计划发生了改变,这些问题不会导致明显的数据库异常症状,但是隐藏起来可能带来不利影响,并且因为这些隐藏的问题,显然影响了数据库的运行性能。
通过查询某些特定的数据,如逻辑读、物理读等,绘制数据库的运行趋势曲线,可以从中一目了然的观察到数据库的性能波动,从而及早发现和解决问题。
通过如下一段SQL可以将AWR数据采样的逻辑读信息读取出来,由于缺省的AWR只保留7天的数据,所以查询全部数据即可:
set linesize 120
set pagesize 999
SELECT TO_CHAR (sn.begin_interval_time, 'yyyy-mm-dd HH24:MI:SS') snap_time,
(e.VALUE - lag(e.VALUE) over (order by e.snap_id)) logicalreads
FROM sys.wrh$_sysstat e,
v$statname n,
sys.wrm$_snapshot sn
WHERE e.instance_number = 1 AND sn.instance_number =1
AND e.snap_id = sn.snap_id
AND e.stat_id = n.stat_id
AND n.NAME = 'session logical reads'
ORDER BY 1
/
数据输出格式摘要如下:
SNAP_TIME LOGICALREADS
------------------- ------------
2010-10-01 22:59:20
2010-10-01 23:59:37 7914939
2010-10-02 00:59:42 5471360
2010-10-02 01:58:56 6079590
2010-10-02 02:59:06 27729779
2010-10-02 03:59:29 16280373
2010-10-02 04:59:36 27802054
2010-10-02 05:59:41 14229631
2010-10-02 06:59:52 11010246
2010-10-02 07:58:59 10974594
2010-10-02 08:59:07 24670094
2010-10-02 09:59:12 18264043
2010-10-02 10:59:38 18450890
2010-10-02 11:59:00 22340364
2010-10-02 12:59:12 20539730
2010-10-02 13:59:22 19583730
2010-10-02 14:59:30 18647744
2010-10-02 15:59:35 20019189
2010-10-02 16:59:45 18086904
2010-10-02 17:58:53 11423746
2010-10-02 18:59:09 8666700
2010-10-02 19:59:29 8110422
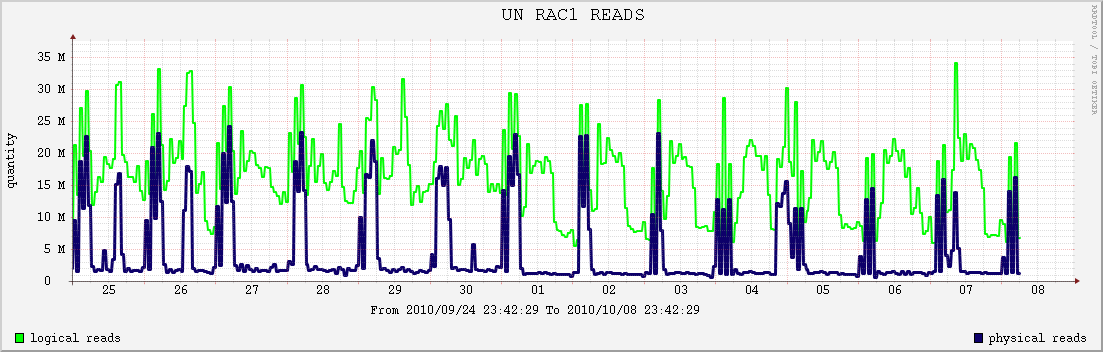
将这些数据绘制在Excel中,就可以获得数据库逻辑读趋势曲线,从图中,可以清楚地看到有一个点的逻辑读明显高于其他时段,这个点是10月7日9点:
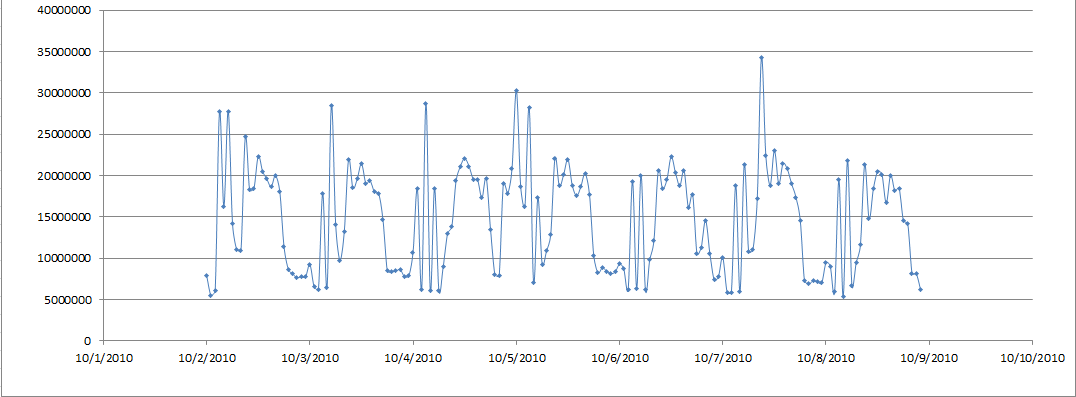
可以生成该点的AWR报告,查看逻辑读升高的具体原因:
SQL> @?/rdbms/admin/awrrpt
Current Instance
~~~~~~~~~~~~~~~~
DB Id DB Name Inst Num Instance
----------- ------------ -------- ------------
2475839388 ORADB 1 oradb1
Enter value for report_type:
Type Specified: html
Instances in this Workload Repository schema
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
DB Id Inst Num DB Name Instance Host
------------ -------- ------------ ------------ ------------
* 2475839388 1 ORADB oradb1 oracledb3
2475839388 2 ORADB oradb2 oracledb4
Using 2475839388 for database Id
Using 1 for instance number
Specify the number of days of snapshots to choose from
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Enter value for num_days: 2
Listing the last 2 days of Completed Snapshots
Snap
Instance DB Name Snap Id Snap Started Level
------------ ------------ --------- ------------------ -----
oradb1 ORADB 2493 07 Oct 2010 00:59 1
。。。。。。。
2501 07 Oct 2010 08:58 1
2502 07 Oct 2010 09:59 1
2503 07 Oct 2010 10:59 1
2504 07 Oct 2010 11:59 1
2505 07 Oct 2010 12:59 1
2506 07 Oct 2010 13:58 1
Specify the Begin and End Snapshot Ids
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Enter value for begin_snap: 2501
Begin Snapshot Id specified: 2501
Enter value for end_snap: 2502
End Snapshot Id specified: 2502
Specify the Report Name
~~~~~~~~~~~~~~~~~~~~~~~
The default report file name is awrrpt_1_2501_2502.html. To use this name,
press <return> to continue, otherwise enter an alternative.
Enter value for report_name:
Using the report name awrrpt_1_2501_2502.html
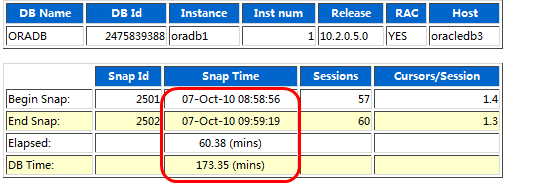
由于处于国庆假期,数据库负荷不高,但是在一个小时内,DB Time仍然有近3倍的Elapsed比率:
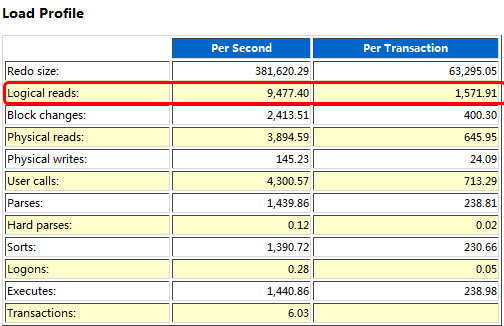
在负载概要信息部分,可以看到逻辑读的相关信息,每秒逻辑读为9477.40,这个数字并不算高,但是在趋势曲线中已经明显高于其他时段:
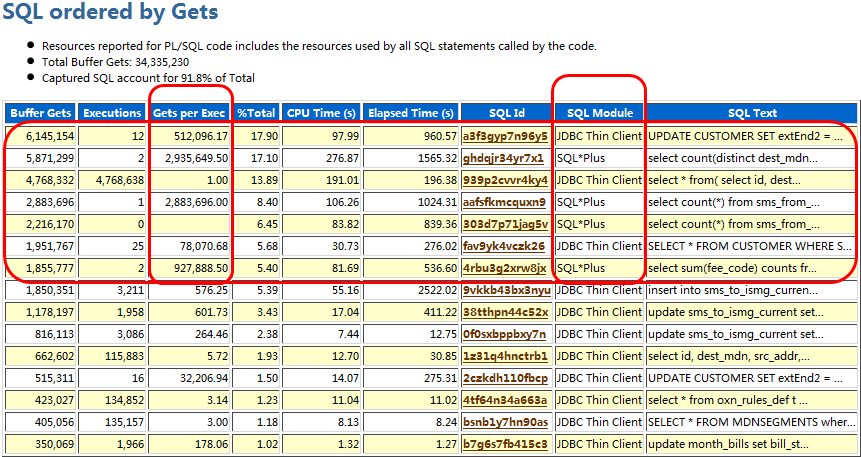
再考察SQL逻辑读部分,可以看到有多个SQL*Plus调度的运算任务,单次SQL执行的逻辑读都很高,如果要进行SQL优化,进一步的就应该查看这些SQL的执行计划,看看是否有优化的余地,是否可以通过调整降低SQL的逻辑读等:
通过类似的查询,可以对任意感兴趣的维度进行趋势分析,将这些数据导入到一些工具中,如Cacti,就可以自动生成数据库系统的性能趋势曲线,定时浏览这些图表可以帮助我们更加有效地监控数据库的性能状况:
合理的利用Statspack和AWR性能数据,是科学管理数据库的良好开端。
在Oracle Database 11g中,一个新引入的函数PIVOT可以用于进行方便的行列转换,通过这个功能,可以将如下查询以横向的方式展开,获得良好的格式化输出:
SQL> WITH
2 timed_events AS
3 (SELECT snap_id,wait_class#,
4 time_waited_micro / 100 AS time_spent
5 FROM sys.wrh$_system_event se, v$event_name en
6 WHERE se.instance_number = 1
7 AND se.event_id = en.event_id),
8
9 pivoted_data AS
10 (SELECT *
11 FROM (SELECT * from timed_events)
12 PIVOT (SUM(time_spent)
13 FOR wait_class# IN ( 1 AS Application,2 AS Configuration,4 AS Concurrency,
14 5 AS Commit,8 AS User_io,9 AS System_io))),
15
16 deltas AS
17 (SELECT snap_id,
18 CAST(BEGIN_INTERVAL_TIME AS DATE) BEGIN_INTERVAL_TIME,
19 (CAST(BEGIN_INTERVAL_TIME AS DATE) - LAG(CAST(BEGIN_INTERVAL_TIME AS DATE))
20 OVER (PARTITION BY startup_time ORDER BY snap_id)) * 86400
21 AS snap_time_d,
22 Configuration - LAG (Configuration)
23 OVER (PARTITION BY startup_time ORDER BY snap_id)
24 AS Configuration_d,
25 application - LAG (application)
26 OVER (PARTITION BY startup_time ORDER BY snap_id)
27 AS application_d,
28 concurrency - LAG (concurrency)
29 OVER (PARTITION BY startup_time ORDER BY snap_id)
30 AS concurrency_d,
31 commit - LAG (commit)
32 OVER (PARTITION BY startup_time ORDER BY snap_id)
33 AS commit_d,
34 user_io - LAG (user_io)
35 OVER (PARTITION BY startup_time ORDER BY snap_id)
36 AS user_io_d,
37 system_io - LAG (system_io)
38 OVER (PARTITION BY startup_time ORDER BY snap_id)
39 AS system_io_d
40 FROM pivoted_data NATURAL JOIN sys.wrm$_snapshot)
41
42 SELECT snap_id,
43 BEGIN_INTERVAL_TIME,
44 application_d / snap_time_d AS application,
45 concurrency_d / snap_time_d AS concurrency,
46 commit_d / snap_time_d AS commit,
47 Configuration_d / snap_time_d AS Configuration,
48 user_io_d / snap_time_d AS user_io,
49 system_io_d / snap_time_d AS system_io
50 FROM deltas
51 ORDER BY snap_id;
SNAP_ID BEGIN_INTERVAL_TIME APPLICATION CONCURRENCY COMMIT CONFIGURATION USER_IO SYSTEM_IO
---------- ------------------- ----------- ----------- ------- ------------- ------- ---------
25890 2010/10/01 00:00
25891 2010/10/01 01:00 .00 44.34 2.10 .01 .41 176.71
25892 2010/10/01 02:00 .00 46.73 1.55 .00 .25 176.25
25893 2010/10/01 03:00 .00 17.44 .44 .00 .00 166.21
25894 2010/10/01 04:00 .00 1.65 .12 .00 .68 163.58
25895 2010/10/01 05:00 .00 1.49 .21 .00 .26 161.18
25896 2010/10/01 06:00 .04 1.46 .52 .00 1.71 185.54
25897 2010/10/01 07:00 .06 22.82 .32 .00 9.92 3151.52
25898 2010/10/01 08:00 .55 1.21 5.79 .00 3.10 170.38
25899 2010/10/01 09:00 .00 1.72 .42 .00 .75 162.10
25900 2010/10/01 10:00 .00 25.77 .24 .00 .13 161.52
25901 2010/10/01 11:00 .00 72.96 .79 .00 .46 177.99
25902 2010/10/01 12:00 .00 52.18 .87 .00 .11 176.37
25903 2010/10/01 13:00 .00 10.20 .13 .00 .45 165.37
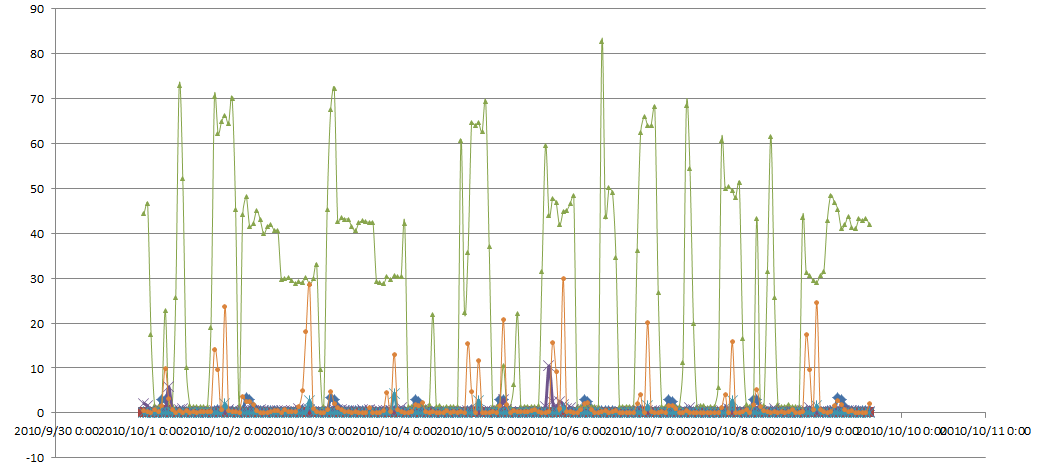
将这些数据整合一下,输入Excel,就可以看到数据库不同种类等待事件的等待情况:
合理的利用采样数据,进行数据库性能分析,是Oracle数据库性能优化的重要方法之一。
