




前言
大家好,我是林哥!
今天给大家带来 2 个简单的 Spark 实战案例,分别是网站的 PV&UV 值计算、Spark 二次排序 。
大家可以通过这 2 个案例,不仅可以锻炼对 Spark 常见的 RDD 算子使用,也可以较为深入的了解大数据这两种典型场景的编程思路!
一.网站 PV&UV 值计算
1.什么是 PV 值
PV(page view)即页面浏览量或点击量,是衡量一个网站或网页用户访问量。具体 的说,PV 值就是所有访问者在 24 小时(0 点到 24 点)内看了某个网站多少个页面或某 个网页多少次。PV 是指页面刷新的次数,每一次页面刷新,就算做一次 PV 流量。
度量方法就是从浏览器发出一个对网络服务器的请求(Request),网络服务器接到这 个请求后,会将该请求对应的一个网页(Page)发送给浏览器,从而产生了一个 PV。那 么在这里只要是这个请求发送给了浏览器,无论这个页面是否完全打开(下载完成),那么 都是应当计为 1 个 PV
2.什么是 UV 值
UV(unique visitor)即独立访客数,指访问某个站点或点击某个网页的不同 IP 地址 的人数。
在同一天内,UV 只记录第一次进入网站的具有独立 IP 的访问者,在同一天内再 次访问该网站则不计数。UV 提供了一定时间内不同观众数量的统计指标,而没有反应出 网站的全面活动。
3.代码实现
考虑到很多同学无法获取到服务器后台真实的日志数据,因此,林哥都给大家准备好啦!通过下面一个程序模拟服务器后台的日志数据。
模拟的数据种主要选取了七个字段,也是公司常用的几个字段,分别是:ip、地区、日期、时间戳、用户id、网址、浏览行为,以 \t
分隔。数据示例如下:
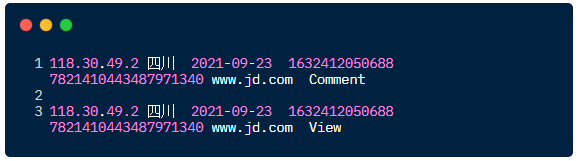
生产数据的程序示例如下,林哥总共造了 5 万条数据:


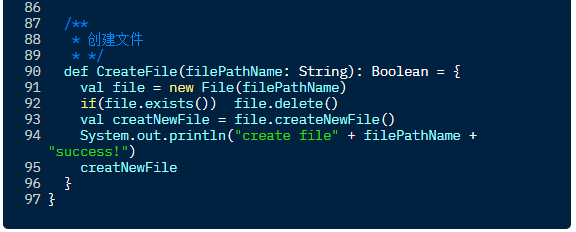
有了数据之后,接下来就是具体的业务逻辑实现了。
很多同学所使用的语言不同,因此本文采取了两种语言的实现方式,分别是 Java 和 Scala。
需求描述:统计网址的 UV 值和 PV 值,并降序排序!
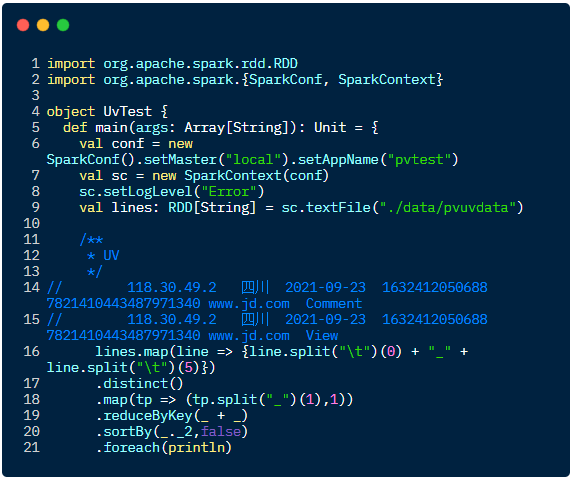
UV 主要实现逻辑:
将每一条数据以 \t
切割,获取到 IP 和 网址,把 IP 和 网址以_
拼接好并返回把 ip 和 网址拼接的数据做个去重,UV 只计算独立访客数 通过 map()
算子,把数据变成(site,1)格式,之后使用reduceByKey()
进行一个累加操作,此时数据格式(www.taobao.com,2000)最后根据统计的数值排序,因为 Java 没有提供直接根据值排序,所以需要把 key
和value
调换,排好序,再调换回来
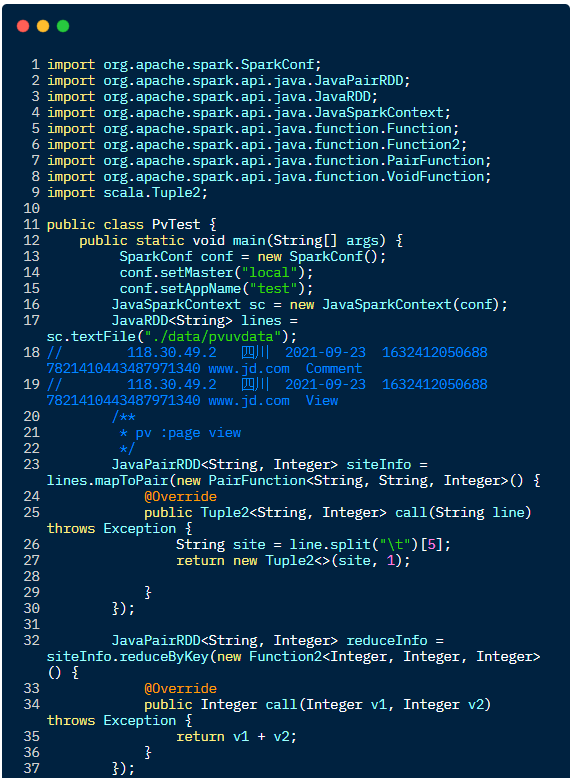
Java 语言实现代码如下:


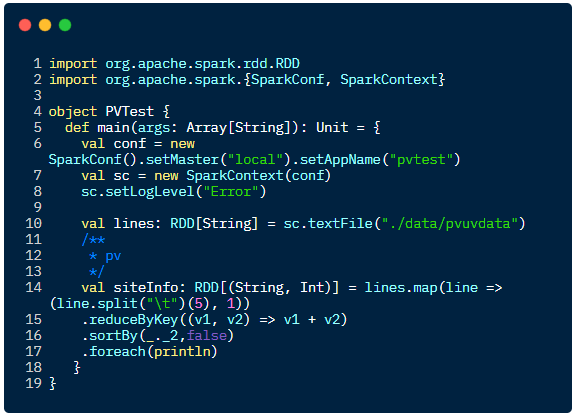
Scala 语言实现代码如下:
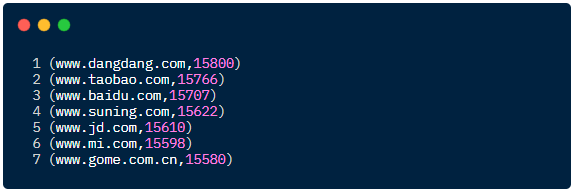
运行结果如下:
PV 的主要实现逻辑其实就是一个 wordcount 的过程:
将每一条数据以 \t
切割,获取到网址,使用map()
算子,把数据形成(site,1)格式,并返回通过 reduceByKey()
把相同的网址做一个累加:(www.taobao.com ,20000)通过 sortBy()
算子,按照 value 进行降序排序 ( 传参false
表示降序 )
Java 语音实现代码如下:

scala 语言代码实现:
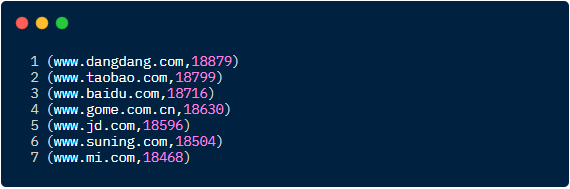
运行结果如下:
二.二次排序
大数据中很多排序场景是需要先根据一列进行排序,如果当前列数据相同,再对其他某列进行排序的场景,这就是二次排序场景。例如:要找出网站活跃的前 10 名用户,活跃用户的评测标准就是用户在当前季度中登录网站的天数最多, 如果某些用户在当前季度登录网站的天数相同,那么再比较这些用户的当前登录 网站的时长进行排序,找出活跃用户。这就是工程当中常见的一个典型的二次排序场景。
本文不考虑这么复杂的场景,仅使用两列 int
类型的数据,来完成二次排序的功能,如果是其它场景,可以按照这个思路进行改写。
需求描述:将两列 int 类型数据,按照第一列数据升序排序,如相等,则按第二列升序排序。
准备两列 int
类型数据如下:

解决二次排序问题可以采用封装对象的方式,对象中实现对应的比较接口以及该接口对应方法。
此处,即将数据封装成一个 SecondSortKey
类,把第一列和第二列数据分别作为该类的两个属性,实现 Ordered
接口,并实现 compare()
方法!
compare()
方法的逻辑:
如果第一列数据相同,则根据第二列数据升序排序 否则按第一列升序排序
代码主要逻辑:
以 \t
分割数据,得到first
和second
,并以这两个变量构造SecondSortkey
对象,返回一个二元组:(SecondSortKey 对象,line)之后根据该对象进行排序
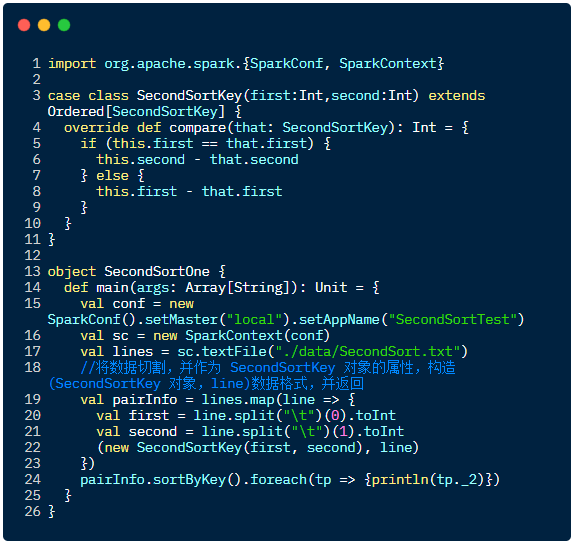
Scala 语言代码实现:
运行结果如下:

从上述代码可以看出,Scala 语言实现同样的功能,代码非常简洁,所以各位小伙伴一定要会 Scala,尽量使用 Scala 开发,提高效率。
最后,给大家留一份小作业,林哥这里没有贴出 Java 语言实现二次排序,大家可以尝试 Java 语言写一下,可以私发给我,我帮大家看看!
好了,如果觉得此文对你有帮助的话,欢迎三连:点赞、分享加在看!
--END--

推荐阅读:
欢迎大家加我个人微信,有关大数据的问题我们在群内一起讨论

长按上方扫码二维码,加我微信,拉你进群
