背景
最近项目需求中,出现Kafka集群双活的应用场景。笔者开始这部分的调研实践工作。MirrorMaker1.0在大规模生产环境中使用多年,暴露如下问题:
1. 主题是使用默认配置创建的。需要后期手动重新分区或者提前创建好合适主题。2. 不能同步集群ACL和主题配,因此难以管理多个群集。3. 生产者使用DefaultPartitioner对数据重新分区。分区语义可能会丢失。4. 修改配置需要重启,包括向白名单中添加新主题(这通常是一个频繁的操作)。5. 没有在镜像集群之间迁移生产者或消费者的机制。6. 不支持有且仅有一次的语义。复制过程中可能会出现重复数据。7. 集群之间不是严格意义的镜像,即不支持双活。8. rebalance会导致延迟,这可能会触发进一步的rebalance,陷入恶性循环。
基于上述问题,MirrorMaker2.0应运而生!本文主要介绍MIrrorMaker2.0的架构与实际应用场景。后续系列文章会深入介绍运行模式、配置文件语法、实际案例实战等内容。
MirrorMaker2.0架构
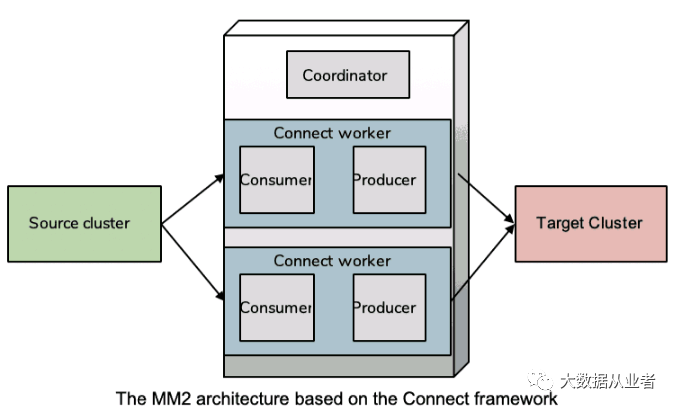
MM2基于kafka connect框架,可将其看做kafka source连接器和kafka sink连接器的结合。在典型的连接配置中,source连接器从外部数据源将数据写入Kafka,而sink连接器从Kafka读取数据写入外部存储系统。与MM1一样,建议使用reomte-consume和local-produce模式,因此在最简单的source-target复制中,MM2 Connect集群与target Kafka集群同侧。
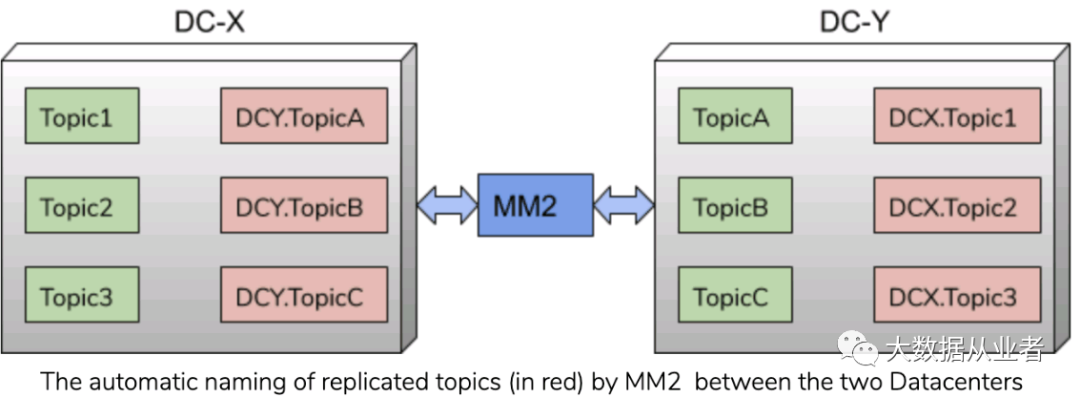
在MM1中,source集群中的主题名称通常与target集群中的主题名称相同。这样会导致做双活集群时候产生无限循环。MM2通过自动向target主题名称添加预配置前缀(源集群别名)来解决此问题。
例如:位于两个数据中心(DC-X、DC-Y)的kafka集群设置双活
DC-X Topics: Topic_1, Topic_2, …DC-Y Topics: Topic_A, Topic_B, …
通过MM2设置双活之后,同步主题时候会自动过滤掉携带target集群前缀的主题。消费者可以订阅一个超级topic,如"*TopicA",正常从source集群消费数据,发生故障时,从target集群继续消费数据。这得益于MM2能够自发现group并同步group offset,有一点需要特别强调一下:只同步idle或dead状态下group offset,详细解释见源码注释如下:
// sync offset to the target cluster only if the state of current consumer group is:// (1) idle: because the consumer at target is not actively consuming the mirrored topic//即 idle:目的集群group当前未运行// (2) dead: the new consumer that is recently created at source and never exist at target//即 dead: group只存在于source集群,不存在target集群
只同步source集群中group offset大于target集群中group offset,详细见源码如下:
// if translated offset from upstream is smaller than the current consumer offset// in the target, skip updating the offset for that partitionlong latestDownstreamOffset = targetConsumerOffset.get(topicPartition).offset();if (latestDownstreamOffset >= convertedOffset.offset()) {log.trace("latestDownstreamOffset {} is larger than or equal to convertedUpstreamOffset {} for "+ "TopicPartition {}", latestDownstreamOffset, convertedOffset.offset(), topicPartition);continue;}
上述同步限制很精妙合理,不然group offset来回同步前后跳跃就乱套了。
MM2消费kafka数据使用kafka connect框架而不是kafka high level API,其原因就在于避免频繁触发rebalance。MM2通过使用low-level API订阅给定的分区列表,可以避免由于主题更改(创建新主题或将新主题添加到白名单)而触发的rebalance。MM2使用内部机制在这些workers/consumers之间划分分区。与直接订阅source集群分区的Connect worker的high-level API不同,MM2在Connector leader或controller中管理分配情况。controller跟踪source集群上的变更,然后将分区分发给workers。workers使用low-level API直接订阅由controller分配的分区,从而消除了大多数rebalance。
因此,对主题和分区数量的任何更改都不会导致完全的rebalance。但是,kafka connect集群自身(更多worker节点等)的更改会触发无法避免的rebalance。在大多数情况下,这些变化比主题变化更为罕见。
MM2使用2个内部主题来跟踪主题offset映射关系、group offset映射关系。

应用场景:跨数据中心部署
建议:
1. 需要跨数据中心部署时,建议在每个数据中心部署一个本地Kafka Cluster。2. 每个数据中心的应用程序只跟所在数据中心的本地Kafka Cluster交互。3. 不同数据中心的Kafka Clusters通过Geo-Replication进行mirror data。
优点:
1. 数据中心之间相互独立、解耦。2. 方便集中管理数据中心之间mirror data。3. 数据中心之间链路异常不影响应用程序,链路恢复,应用程序可以继续追赶数据。
说明:
1. 如果应用程序需要访问所有数据中心的数据,可以将所有数据中心数据mirror汇聚到本地Kafka Clsuter。也可以通过WAN(广域网,又称外网或公网)直接读写其他数据中心数据,显然这样会增加延迟,可以考虑增加TCP socket缓存配置(socket.send.buffer.bytes、socket.receive.buffer.bytes)。2. 通常不建议在高延迟链路上跨多个数据中心部署单个Kafka Cluster。这将导致Kafka和Zookeeper不可用。
应用场景:跨地域部署
基于组织机构、、技术、法律要求,Kafka管理员可以定义跨Kafka集群、跨数据中心、跨地域的数据流。常见场景包括:
1. 跨地域复制(Geo-Replication)2. 灾难恢复(Disaster recovery)3. 多边缘集群汇聚到统一中心集群(Feeding edge clusters into a central,aggregate cluster)4. 集群的物理隔离:生产和测试(Physical isolation of clusters:such as production vs testing)5. 云迁移或混合云部署(Cloud migration or hybrid cloud deployments)6. 法律法规要求(Legal and compliance requirements)
Kafka管理员可以使用MirrorMakerV2设置上述数据流。支持功能包括:
1. 复制主题数据和配置(Replicates topics data plus configurations)2. 复制消费者组及偏移量,方便集群之间迁移应用程序(Replicaiton consumer groups including offsets to migrate applications between clusters)3. 复制ACLs(Replication ACLs)4. 保留分区(Preserves partitioning)5. 自动检测新主题和分区(Automatically detects new topics and partitions)6. 提供metrics指标:如端到端延迟(Provides a wide range of metrics,such as end-to-end replication latency)7. 容错和水平可扩展(Fault-tolerant and horizontally scalable operations)
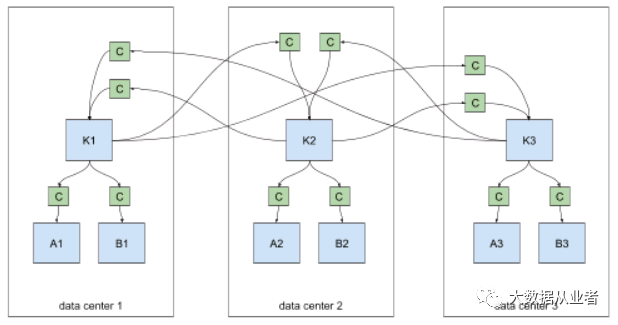
Kafka管理员可以创建各种复杂的数据流拓扑。拓扑案例包括:
1. 双活部署:A->B,B->A(Active/Active high availability deployments)2. 主从部署:A->B(Active/Standby high availability deployments)3. 聚合部署:A->K,B->K,C->K(Aggregation:from many clusters to one)4. 发散部署:K->A,K->B,K->C(Fan-out:from one to many clusters)5. 转发部署:A->B,B->C,C->D(Forwarding)