




背景
我们都知道RocksDB属于Flink三种状态后端之一。RocksDB允许作业状态大于taskmanager可用内存大小,因为RocksDB状态后端可能会将状态溢出到本地磁盘。这意味着磁盘性能可能会影响使用RocksDB作为状态后端的Flink作业的性能。通过一个案例研究,本文阐述了使用RocksDB的Flink作业的吞吐量下降问题,并演示了如何将底层磁盘的性能确定为根本原因的过程。
作业和执行环境
我们正在处理一个典型的物联网(IoT)场景,需要处理数百万设备产生的事件流。每个事件都包含设备标识符(ID)、事件类型和事件生成时的时间戳。作业基于设备ID对流进行分区,并在状态中存储从每个事件类型到接收到该类型事件时的最新时间戳的映射。可以有数百种事件类型。对于每个传入事件,作业需要从状态中读取接收到的事件类型的时间戳,并将其与传入事件进行比较。如果传入的时间戳较新,它将更新存储在状态中的时间戳。
该作业Flink TaskManager分配有1.5个CPU内核和4 GB内存。作业使用RocksDB状态后端,该后端配置为使用Flink的托管内存。state.backend.rocksdb.localdir配置选项未明确设置,因此默认情况下,/tmp目录用于保存rocksdb运行中状态(即工作状态)。
作业异常现象
该作业最初运行良好。但是,经过一段时间数小时或数天(取决于传入的事件数量),作业吞吐量突然显著下降。这种下降很容易重现。下面的吞吐量指标图显示,在给定的一天23:50后不久,吞吐量从每秒超过10k个事件下降到每秒几百个事件。

此外,使用保存点停止作业,然后再从中恢复也无济于事:重新启动后,作业吞吐量仍然很低。虽然在作业从空状态重新启动时恢复了高吞吐量,但这显然不是解决问题的办法,因为(1)作业状态将丢失,(2)作业吞吐量将在较短时间后再次下降。
问题分析
检查CPU指标时,我们注意到当吞吐量下降时,TaskManager容器的CPU利用率也会降低。由于TaskManager容器可能会使用更多的CPU资源(与吞吐量下降发生之前相同),因此CPU使用率的降低在这里是一个异常现象。

TaskManager容器的内存使用在吞吐量下降发生之前很长一段时间就达到了分配限制,在23:50左右没有明显变化。

为了进一步调查原因,我们开启了TaskManager JMX,设置如下:
env.java.opts.taskmanager:>--Dcom.sun.management.jmxremote-Dcom.sun.management.jmxremote.authenticate=false-Dcom.sun.management.jmxremote.ssl=false-Dcom.sun.management.jmxremote.local.only=false-Dcom.sun.management.jmxremote.port=1099-Dcom.sun.management.jmxremote.rmi.port=1099-Djava.rmi.server.hostname=127.0.0.1
然后,我们将一个本地运行的VisualVM连接到TaskManager,并进行CPU采样。如下面的CPU采样结果所示,93%的CPU时间被线程UpdateState占用。这是运行操作符UpdateEstate的线程,它读取并更新RocksDB中的状态。
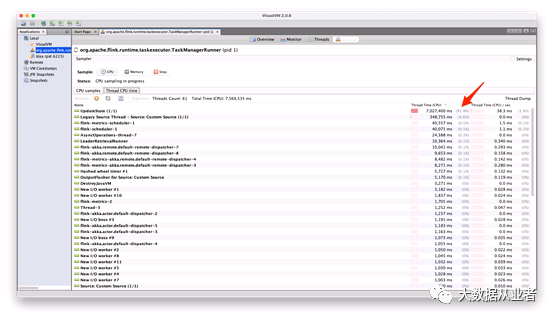
在UpdateState线程内部,如下面的屏幕截图所示,几乎所有的CPU时间都被方法org.rocksdb.rocksdb.get()方法占用。这告诉我们,在RocksDB的reading state上遇到了瓶颈。
为了进一步调查RocksDB耗时所在,我们开启了以下Flink RocksDB指标(注意:默认情况下禁用RocksDB本机指标,因为它们可能会影响作业性能):
state.backend.rocksdb.metrics.block-cache-capacity:truestate.backend.rocksdb.metrics.block-cache-pinned-usage:truestate.backend.rocksdb.metrics.block-cache-usage:truestate.backend.rocksdb.metrics.estimate-table-readers-mem:true
block cache是RocksDB将数据缓存在内存用于读取的地方。如下图所示,在作业启动的最初几分钟内,block cache很快被state entries填满。这仍然不能解释吞吐量在23:50左右突然下降的原因。
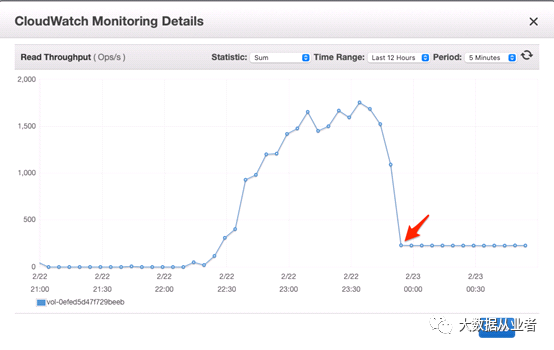
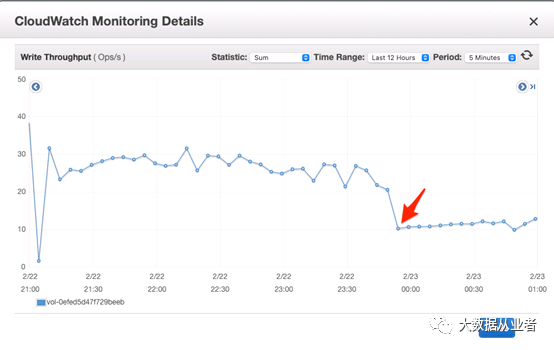
当RocksDB block cache不存在需要读取的state entry时,就会触发磁盘IO操作。我们继续检查磁盘metrics。如下面两个图所示,在Flink作业吞吐量下降时,读取吞吐量下降到每秒230次左右。写入吞吐量也发生了同样的情况,下降到大约10。检查每秒磁盘输入/输出操作(IOPS)容量时,我们发现默认情况下,磁盘大小为80GB,提供240 IOPS的基线速率。这证实了磁盘已饱和,并且Flink作业在磁盘IO上受到限制。
找到根本原因后,该问题的解决方案就是附加一个具有高IOPS速率的专用磁盘,然后将Flink configuration中state.backend.rocksdb.localdir设置为该磁盘上的目录。
结论
本文主要描述了Flink作业吞吐量下降的现场以及排查问题的过程。正如我们所看到的,磁盘性能对Flink中RocksDB状态后端的性能产生了重大影响。当使用状态大的RocksDB 状态后端时,访问状态预计会持续命中磁盘(例如,随机读取RocksDB的状态),您应该将Flink configuration中state.backend.RocksDB.localdir设置为高IOPS磁盘上的目录。
