Batch是Streaming的一种特殊形式。FLIP-134: Batch execution for the DataStream API将DataStream API称为Batch和Streaming执行模式的统一抽象,而不是维护各自单独的API:
Reusability(可重用性)
统一的API无需重写代码,轻松切换批模式或者流模式。作业可以很容易重用以处理实时数据或历史数据。
Operational simplicity(操作简单性)
统一的API意味着使用一组相同的连接器,维护一个代码库,能够轻松实现混合连接器管道。
批处理和流式处理与有界和无界处理之间的区别是微妙的,这些术语似乎可以互换,但实际上用途不同:
有界和无界指数据流的特征:是否已知终点。处理有界流的应用程序会退出(所有数据一起处理),处理无界流的应用程序不退出(数据逐条分阶段处理)。
批处理和流处理指执行模式。批处理仅适用于有界流,流处理适用于有界流和无界流。
基于上述描述,通常使用两种主要场景:有界流应用程序以批模式运行、无界流应用程序以流模式运行,以流模式运行有界流应用程序则显示没有意义(仅用于测试的场景除外)。
如何抉择使用哪种API?哪种execution mode?
Table API/SQL适用场景:结构化数据、数据携带schema;事实上,大多数批处理程序都应该采用Table API/SQL。
DataStream API适用场景:显示控制execution graph、手动控制operation state、支持无限流应用程序升级。
如果需要处理有界流或者历史数据,首选batch mode,几点好处:
1. 有界数据不存在late data,无需考虑timestamp、watermark。2. 流式处理的调度方式和失败恢复可能影响性能。而处理有限数据可以对其优化。3. 简化设置和维护管道的操作开销。例如,不需要配置检查点,不需要选择状态后端或为检查点设置分布式存储。
如何指定execution mode?BATCH、STREAMING(默认)、AUTOMATIC
配置文件(flink-conf.yaml)中指定execution.runtime-mode,属于所有作业公用参数
命令行中指定execution.runtime-mode,属于作业级别定制参数
$ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar
代码逻辑中指定RuntimeExecutionMode,属于作业级别定制参数
java StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.BATCH);
注意:AUTOMATIC指根据有界流/无界流自动决定采用BATCH/STREAMING模式!!
批模式、流模式区别
采用DataStream API实现代码逻辑,见
https://github.com/felixzh2020/felixzh-learning-flink/tree/master/ExecutionModes
输入:1 2 3 4 1 2 3
批模式仅输出最终计算结果(4行):
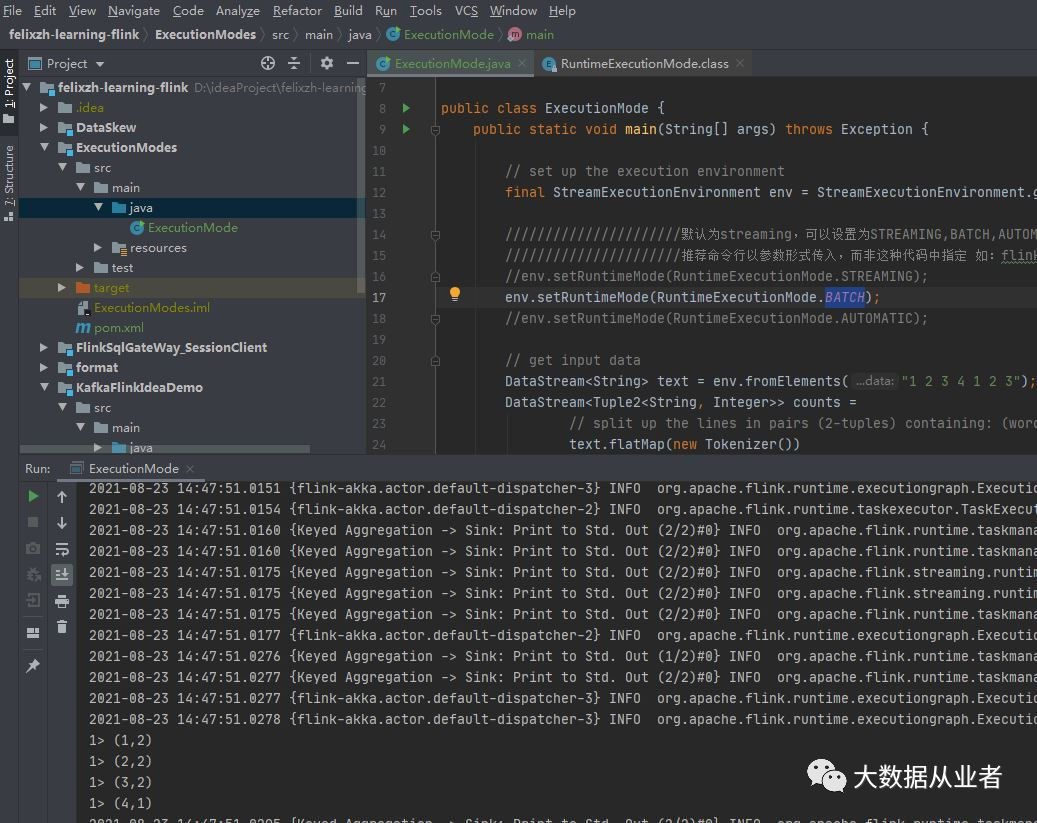
流模式输出计算过程所有结果(6行):