




前言
大数据领域实际处理场景中,数据倾斜问题是所有大数据工程师都绕不开的。那么使用Flink实时计算引擎时,如何解决数据倾斜问题呢?本文以一个实战案例演示,如何采用分而治之的思想、处理keyBy数据倾斜问题。
数据倾斜
通常情况下,我们用Flink处理数据时期望的拓扑如图:
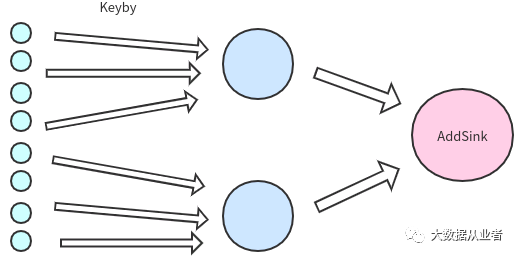
而实际的拓扑可能如图:
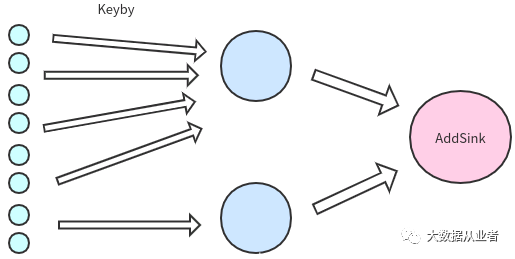
但是呢,我们的业务需求就是要根据key进行聚合统计。
那么怎么才能将相同key放在不同subtask计算呢?
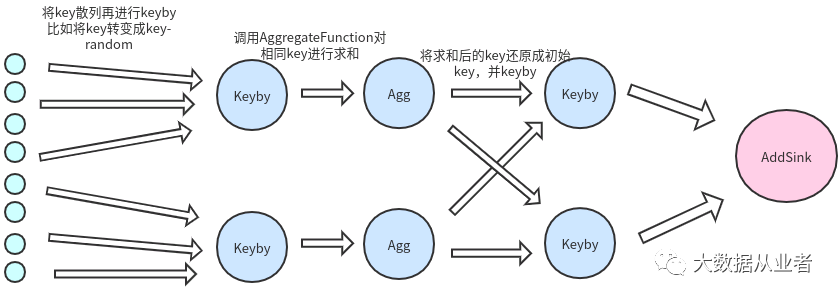
解决方案:
1.打散热点key(增加前缀或后缀随机数标签,确保数据散列)2.进行第一次聚合统计3.还原散列key为原来的key4.进行第二次聚合统计
实战案例剖析
通过DataStream API中socketTextStream读取nc数据(port:4444),进行wordcount计算。
说明:数据倾斜是指大数量下数据不均匀的问题,小数据量可以不考虑。本案例仅以小数据为例,演示具体处理方法而已。
我们首先看不考虑数据倾斜问题的实现代码:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> socketData = env.socketTextStream("10.121.198.220", 4444);DataStream<Tuple2<String, Integer>> tupleData = socketData.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {Tuple2<String, Integer> data = new Tuple2<>();data.setFields(value.split(",")[0], Integer.parseInt(value.split(",")[1]));out.collect(data);}}).setParallelism(4);tupleData.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}}).reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {Tuple2<String, Integer> data = new Tuple2<>();data.setFields(value1.f0, value1.f1 + value2.f1);return data;}}).print();env.execute("SocketApplication");
测试结果:
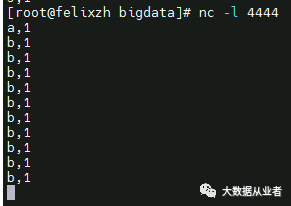
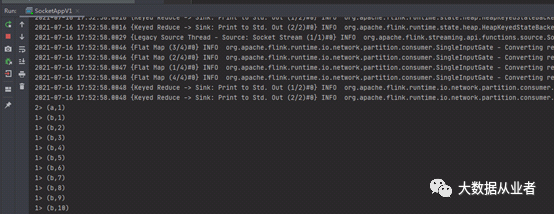
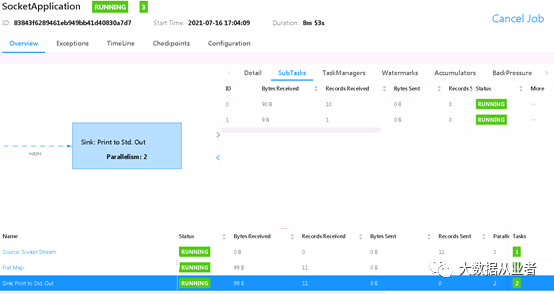
如上图所示,我们可以看到keyBy之后,数据出现不均衡,1:10。
下面,我们使用两阶段keyBy处理这种倾斜问题。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> socketData = env.socketTextStream("10.121.198.220", 4444);Random random = new Random(1);DataStream<Tuple2<String, Integer>> tupleData = socketData.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {Tuple2<String, Integer> data = new Tuple2<>();data.setFields(value.split(",")[0] + "_" + random.nextInt(50), Integer.parseInt(value.split(",")[1]));out.collect(data);}}).setParallelism(4);KeyedStream<Tuple2<String, Integer>, String> keyedStream = tupleData.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});keyedStream.print("增加后缀标签打散key");SingleOutputStreamOperator<HashMap<String, Integer>> dataStream1 = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5))).aggregate(new MyCountAggregate()).setParallelism(4);dataStream1.print("第一次keyBy输出");DataStream<Tuple2<String, Integer>> dataStream2 = dataStream1.flatMap(new FlatMapFunction<HashMap<String, Integer>, Tuple2<String, Integer>>() {@Overridepublic void flatMap(HashMap<String, Integer> value, Collector<Tuple2<String, Integer>> out) throws Exception {value.forEach((k, v) -> {Tuple2<String, Integer> data = new Tuple2<>();data.setFields(k.split("_")[0], v);out.collect(data);});}}).setParallelism(4);dataStream2.keyBy(new KeySelector<Tuple2<String, Integer>, Object>() {@Overridepublic Object getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}}).reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {Tuple2<String, Integer> data = new Tuple2<>();data.setFields(value1.f0, value1.f1 + value2.f1);return data;}}).setParallelism(4).print("第二次keyBy输出");env.execute("SocketApplicationV2");
其中,用到的MyCountAggregate类:
public class MyCountAggregate implements AggregateFunction<Tuple2<String, Integer>, HashMap<String, Integer>, HashMap<String, Integer>> {@Overridepublic HashMap<String, Integer> createAccumulator() {return new HashMap<>();}@Overridepublic HashMap<String, Integer> add(Tuple2<String, Integer> value, HashMap<String, Integer> accumulator) {accumulator.merge(value.f0, value.f1, Integer::sum);return accumulator;}@Overridepublic HashMap<String, Integer> getResult(HashMap<String, Integer> accumulator) {return accumulator;}@Overridepublic HashMap<String, Integer> merge(HashMap<String, Integer> a, HashMap<String, Integer> b) {for (Map.Entry<String, Integer> entry : a.entrySet()) {b.merge(entry.getKey(), entry.getValue(), Integer::sum);}return b;}}
测试结果:
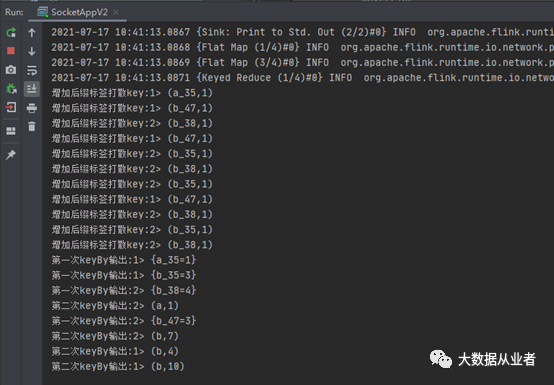
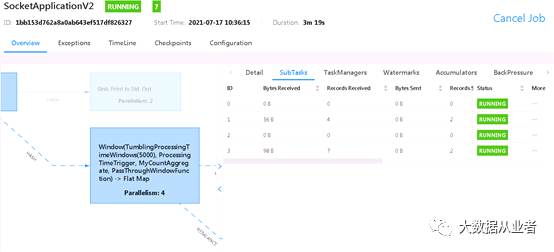
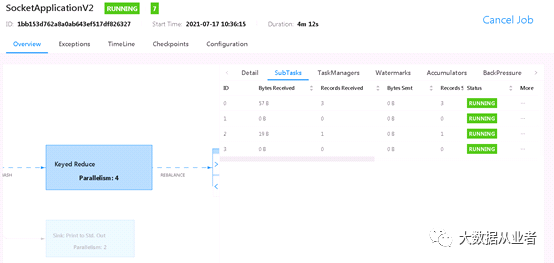
从上述结果可以看到,我们已经将数据倾斜从1:10改为第一阶段4:7,第二阶段1:3。再次强调说明:因为数据量比较小,所以优化效果显示并不那么好,仅以此案例演示原理而已。
至此我们既保证了数据定时聚合统计wordcount,也保证了数据不倾斜问题。
文章转载自大数据从业者,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
