




背景概述
说实话,诸如SparkStreaming、Flink此类型的分布式计算引擎,在本人的日常开发过程中,都是本地(windows)写代码直接打包,提交到Yarn集群,有问题再改,通常1到5把就ok。使用DataStreamAPI从来没有在本地idea中debug。究其原因:一来构建本地环境些许麻烦;二来本地调试通过与能够提交运行在Yarn属于两回事。不过,有很多客户同学都喜欢本地idea调试,客户需求必须满足啊。
客户环境说明
Kafka2.3.0(kerberos)
Flink1.6.0
功能说明
Flink读取开启Kerberos的Kafka数据,打印输出
实现说明
Idea调试Flink就是在Idea内启动一个MiniCluster。
访问开启Kerberos的Kafka集群,需要加载krb5.conf(主要描述kerberos kdc信息,如IP地址等),还需要加载kafka_client_jaas.conf(用于提供kerberos认证用到的信息,如keytab文件,principal等)。
pom依赖
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka-0.11_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version><!--<scope>compile</scope>--> <!-- idea --><scope>provided</scope> <!-- yarn cluster--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_${scala.binary.version}</artifactId><version>${flink.version}</version><!--<scope>compile</scope>--> <!-- idea --><scope>provided</scope> <!-- yarn cluster--></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime_${scala.binary.version}</artifactId><version>${flink.version}</version><!--<scope>compile</scope>--> <!-- idea --><scope>provided</scope> <!-- yarn cluster--></dependency><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version></dependency></dependencies>
完整代码github地址
https://github.com/felixzh2020/felixzh-learning-flink/tree/master/KafkaFlinkIdeaDemo
主要代码
public static void main(String[] args) throws Exception {final ParameterTool para = ParameterTool.fromArgs(args);if (!para.has("path")) {System.out.println("Error: not exist --path opt/your.properties");System.out.println("Usage: flink run -m yarn-cluster -d opt/your.jar --path opt/your.properties");System.exit(0);}if (OperatingSystem.IS_WINDOWS) {System.setProperty("java.security.auth.login.config", "d:\\KafkaFlinkIdeaDemoConf//kafka_client_jaas.conf");System.setProperty("java.security.krb5.conf", "d:\\KafkaFlinkIdeaDemoConf//krb5.conf");}ParameterTool param = ParameterTool.fromPropertiesFile(para.getRequired("path"));StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();if (param.getRequired("checkpoint.enable").equals("1")) {env.getConfig().setUseSnapshotCompression(true);env.enableCheckpointing(Long.valueOf(param.getRequired("checkpoint.interval"))); // create a checkpoint every 5 seconds}env.getConfig().setGlobalJobParameters(param); // make parameters available in the web interfaceProperties consumerProp = new Properties();consumerProp.setProperty("bootstrap.servers", param.getRequired("consumer.bootstrap.servers"));consumerProp.setProperty("group.id", param.getRequired("consumer.group.id"));consumerProp.setProperty("security.protocol", "SASL_PLAINTEXT");consumerProp.setProperty("sasl.mechanism", "GSSAPI");consumerProp.setProperty("sasl.kerberos.service.name", "kafka");FlinkKafkaConsumer011<String> kafkaConsumer = new FlinkKafkaConsumer011<>(param.getRequired("consumer.kafka.topic"),new SimpleStringSchema(), consumerProp);DataStream<String> sourceDataStream = env.addSource(kafkaConsumer);sourceDataStream.print();env.execute();}
本地环境准备
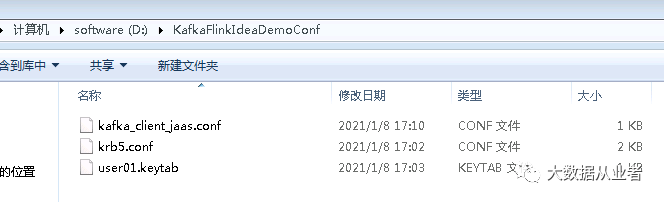
kafka_client_jaas.conf
KafkaClient {com.sun.security.auth.module.Krb5LoginModule requireduseKeyTab=truekeyTab="d:\\KafkaFlinkIdeaDemoConf\\user01.keytab"storeKey=trueuseTicketCache=falseserviceName="kafka"principal="user01";};
krb5.conf和用户keytab文件通过kdc节点获取
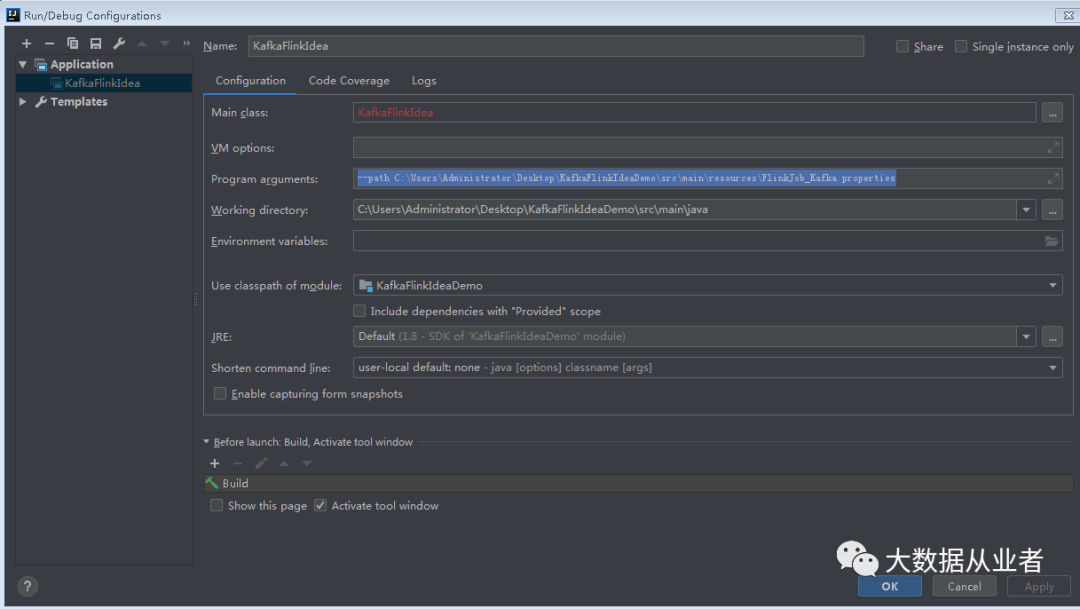
运行方式
注意添加输入参数
文章转载自大数据从业者,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
