概述
Debezium属于CDC(Changelog Data Capture)工具,可以实时跟踪MySQL, PostgreSQL, Oracle, Microsoft SQL Server和很多其他数据库changes信息,写入到Kafka。
Debezium为数据库changes信息提供统一的schema,支持JSON和Avro。详见其官网https://debezium.io/
Flink支持将Debezium的JSON格式消息解释为INSERT/UPDATE/DELETE消息输入到Flink SQL。注意:解释Debezium的protobuf格式消息和发送Debezium消息仍在开发中。
案例说明
为了设置Debezium format,需要添加如下依赖到你的项目:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency>
如何设置Debezium Kafka Connect同步changelog到kafka topics,
不在本文内容内,详见官方描述:
https://debezium.io/documentation/reference/1.1/connectors/index.html
Debezium格式分为两种:
1).不带schema
{"before": {"id": 111,"name": "scooter","description": "Big 2-wheel scooter","weight": 5.18},"after": {"id": 111,"name": "scooter","description": "Big 2-wheel scooter","weight": 5.15},"source": {...},"op": "u","ts_ms": 1589362330904,"transaction": null}
2). 带schema
{"schema": {...},"payload": {"before": {"id": 111,"name": "scooter","description": "Big 2-wheel scooter","weight": 5.18},"after": {"id": 111,"name": "scooter","description": "Big 2-wheel scooter","weight": 5.15},"source": {...},"op": "u","ts_ms": 1589362330904,"transaction": null}}
Flink对两种格式均支持,使用时候的区别只是一个参数的值不同:
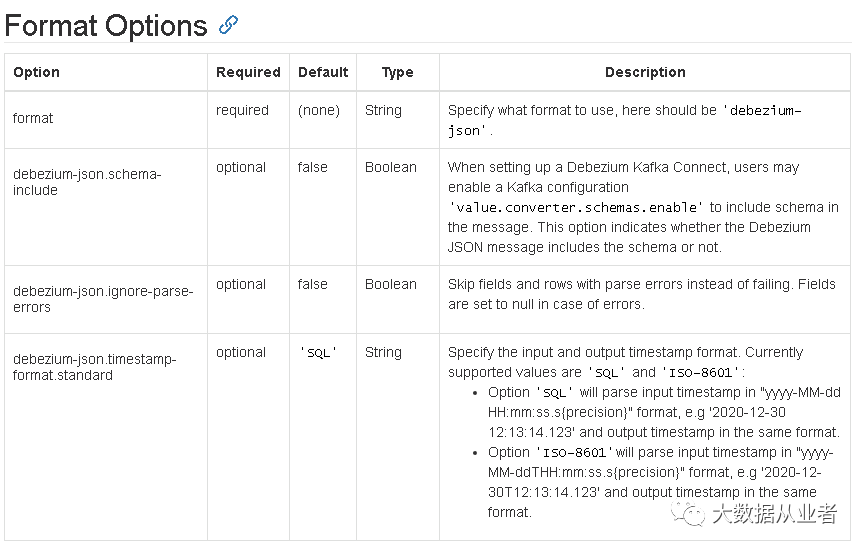
debezium-json.schema-include optional false BooleanWhen setting up a Debezium Kafka Connect, users may enable a Kafkaconfiguration 'value.converter.schemas.enable' to include schemain the message. This option indicates whether the Debezium JSONmessage includes the schema or not.
案例实战
1). 使用kafka producer发送Debezium格式数据(不带schema)
github地址:
https://github.com/felixzh2020/felixzh-learning-kafka/tree/master/src/main/java/org/felixzh/kafka/string
main代码:
public static void main(String[] args) {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, Constant.PRODUCER_BROKER);props.put(ProducerConfig.ACKS_CONFIG, "1");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);producer.send(new ProducerRecord<String, String>(Constant.PRODUCER_DEBAZIUM_TOPIC, debezium_msg.replace("\r\n", "")));producer.close();}
2). 使用Flink SQL解析Debezium数据
github地址:
https://github.com/felixzh2020/felixzh-learning-flink/tree/master/format/src/main/java/com/felixzh/learning/flink/format/debezium_json
项目代码如下:
package com.felixzh.learning.flink.format.debezium_json;import org.apache.flink.api.common.restartstrategy.RestartStrategies;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;import org.slf4j.Logger;import org.slf4j.LoggerFactory;/*** @author felixzh* 微信公众号:大数据从业者* 博客地址:https://www.cnblogs.com/felixzh/*/public class Kafka2Print {Logger logger = LoggerFactory.getLogger(Kafka2Print.class);public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.setRestartStrategy(RestartStrategies.noRestart());StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);String sourceDDL ="CREATE TABLE topic_products (\n" +" id BIGINT,\n" +" name STRING,\n" +" description STRING,\n" +" weight DECIMAL(10, 2)\n" +") WITH (\n" +" 'connector' = 'kafka',\n" +" 'scan.startup.mode' = 'earliest-offset',\n" +" 'topic' = 'debezium_products_binlog',\n" +" 'properties.bootstrap.servers' = 'felixzh:9092',\n" +" 'properties.group.id' = 'testGroup',\n" +" 'debezium-json.ignore-parse-errors' = 'true',\n" +" 'format' = 'debezium-json'\n" +")";String sinkDDL ="CREATE TABLE tb_sink (\n" +" id BIGINT,\n" +" name STRING,\n" +" description STRING,\n" +" weight DECIMAL(10, 2)\n" +") WITH (\n" +" 'connector' = 'print'\n" +")";String transformSQL ="INSERT INTO tb_sink " +"SELECT * " +"FROM topic_products ";tableEnv.executeSql(sourceDDL).print();tableEnv.executeSql(sinkDDL).print();tableEnv.executeSql(transformSQL).print();}}
IDE(idea)运行结果:
+--------+| result |+--------+| OK |+--------+1 row in set+--------+| result |+--------+0 row in set13:54:42,016 WARN org.apache.flink.runtime.webmonitor.WebMonitorUtils - Log file environment variable 'log.file' is not set.13:54:42,029 WARN org.apache.flink.runtime.webmonitor.WebMonitorUtils - JobManager log files are unavailable in the web dashboard. Log file location not found in environment variable 'log.file' or configuration key 'web.log.path'.+------------------------------------------+| default_catalog.default_database.tb_sink |+------------------------------------------+| -1 |+------------------------------------------+1 row in set13:54:44,803 WARN org.apache.flink.runtime.taskmanager.TaskManagerLocation - No hostname could be resolved for the IP address 127.0.0.1, using IP address as host name. Local input split assignment (such as for HDFS files) may be impacted.13:54:45,190 WARN org.apache.flink.metrics.MetricGroup - The operator name Sink: Sink(table=[default_catalog.default_database.tb_sink], fields=[id, name, description, weight]) exceeded the 80 characters length limit and was truncated.13:54:45,219 WARN org.apache.flink.metrics.MetricGroup - The operator name Source: TableSourceScan(table=[[default_catalog, default_database, topic_products]], fields=[id, name, description, weight]) exceeded the 80 characters length limit and was truncated.-U(111,scooter,Big 2-wheel scooter,5.18)+U(111,scooter,Big 2-wheel scooter,5.15)
可配置参数