





概述
Nginx和python都是运维人员的大爱,我们的各个运维后台全部是python写的,里面偶尔会碰到些实现起来比较麻烦的逻辑,但是用nginx的模块却可以轻松解决。
现在运维后台越来越流行,把原先大量的终端操作移到后台来自动化,让我们的工作更加便利化,是DEVOPS的重大枢纽工程,今天来举例介绍下nginx和python后端的一些巧妙结合。
我们使用前后端分离的方式来开发运维平台,约定好通信数据只能是JSON,且HTTP状态为200,前端根据后端返回的JSON数据来进行相应的处理。在后端程序正常的情况下,这个流程很顺利,然而在后端程序出现异常抛出HTTP 50X的时候会导致前端无法识别导致显示异常。
这个要怎么解决呢?我们可以用nginx自带的功能来实现错误兼容:如果是50x错误的话,那么设置一个默认的JSON作为HTTP响应内容,让前端可以正常弹窗提示,这样一方面前端不用做过多的逻辑判断,后端的错误信息也可以相应隐藏起来。参考配置如下:
error_page 500 502 503 504 505 =200 500.html; location = 500.html { types {} default_type ""; add_header 'Content-Type' 'application/json';
return 200 '{"code":1,"error":"服务器异常,请联系管理员处理"}'; }
这样配置之后,当前端访问了一个会出现HTTP 50X 的链接时,nginx会返回正常的json给前端处理:
前端可以直接读出JSON里面的错误信息进行友好提示而不是直接挂掉。{"code":1,"error":"服务器异常,请联系管理员处理"}
类似的,我们也可以对 HTTP 401、404等状态码在nginx进行设置。说到401,我们来讲一下nginx在我们开发过程中的鉴权应用。
我们做权限控制一般都在后端做,但是有个情况是前后端之间的连接不是特别友好,需要在反向代理的时候来进行鉴权,比如我们的运维后台有一个日志查询功能,前端界面如下
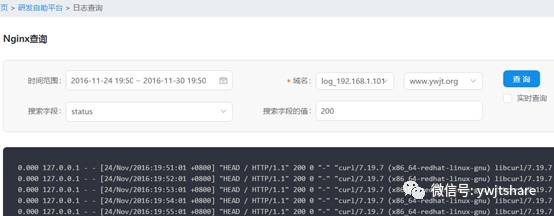
底层采用的是我们之前系列文章提到的ELK系统。使用过ELK的同学应该知道,要做一个类似上图那样精确的查询,ES的原始语句是很复杂的,有多复杂呢?让我们来看看:
像如此繁杂的查询,首先我们担心太多的日志查询导致后端服务不可用,所以不想通过后台程序直接查询ELK后返回给前端,而且在web前端提交会很麻烦,如果让用户直接查ELK的话无法满足我们运维后台做权限控制的需求。因此我们需要一个既能方便前端提交查询条件又能与原有运维后台权限控制相兼容的接口,怎么实现呢?curl -X GET 'http://localhost:9200/nginx-*/_search?size=2&pretty' -d ' { "query": { "bool": { "must": [ {"match": { "status" : "200" }} ], "filter": [ {"range": {"@timestamp": {"gt": "1479988200000","to": "1480506600000"}}}, {"match": { "source" : "www.ywjt.org"}}, {"term": { "beat.name" : "192.168.1.101"}} ] } }, "sort": { "@timestamp": { "order": "asc" } } }'
如果不考虑权限控制的话,我们在ELK服务器上用Python封装一个HTTP接口来接受查询并根据前后端约定的格式返回查询结果,这个很好做,那么权限控制在哪里做呢?我们用nginx的模块来搞定。
Nginx有一个ngx_http_auth_request模块,该模块根据子请求的结果实现客户端授权。如果子请求返回2xx响应代码,则允许访问;如果它返回401或403,则返回相应的错误代码;子请求返回的任何其他响应代码会视为程序错误(HTTP 500)。也就是说我们可以先按照正常后端的模式来鉴权,然后Nginx反向代理的权限控制就直接继承后端的鉴权结果。参考[官方文档](http://nginx.org/en/docs/http/ngx_http_auth_request_module.html)。
经过一系列测试,最后采用下列配置来巧妙实现ELK的鉴权逻辑:
我们面向用户的日志查询接口为/api/elk,当用户点击查询触发请求的时候,nginx会先帮我们请求一次/api/log/auth,后端鉴权之后通过的话则返回一个HTTP 2XX 状态,nginx就会帮我们反向代理到远程ELK查询接口,相当于用户能够直接请求ELK查询接口获取需要的日志;如果权限校验失败可以返回401等HTTP状态,这样nginx就不会进行反向代理请求ELK查询接口。location api/elk { auth_request api/log/auth; #后端程序URI,即反向代理到目标接口前先跳到该URI进行权限校验 proxy_pass http://api.ywjt.org/api/elk; #目标接口 } location = api/log/auth { proxy_set_header Content-Length ""; proxy_set_header X-Original-URI $request_uri; #这里记录用户原始请求的URI,通过此次拿到查询参数先做参数初次校验,记录查询日志 proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Scheme $scheme; proxy_pass http://api; #后端程序 }
基本搞定了,这样初步看起来是没有问题的,不过一开始我们提及,当程序报错的时候,我们的nginx会返回HTTP 200,这样的话就存在一个问题,当程序异常时,用户相当于不需要鉴权就可以直接查询到日志了。解决这个bug的方式比较巧妙,我们在ngx_http_auth_request_module的源码找到判断2XX那部分逻辑,直接修改成一个特定的码即可:
src/http/modules/ngx_http_auth_request_module.c 164行
修改为if (ctx->status >= NGX_HTTP_OK // NGX_HTTP_OK 是 200 && ctx->status < NGX_HTTP_SPECIAL_RESPONSE) // NGX_HTTP_SPECIAL_RESPONSE 是 300 ngx_log_error(NGX_LOG_ERR, r->connection->log, 0, "auth request unexpected status: %d", ctx->status);
return NGX_HTTP_INTERNAL_SERVER_ERROR; //NGX_HTTP_INTERNAL_SERVER_ERROR 是 500
这里202是一个约定的值,具体等于哪个值由使用者自己决定,但是如果像我们在py2.6使用tornado的话,需要考虑一点,就是这个值必须在 usr/lib64/python2.6/httplib.py 的 responses 这个字典的key里,比如写209就不行,除非再进行修改httplib.py代码。if (ctx->status == 202 ) 这里随便改的,虽然我知道硬编码个数字很丑 {
return NGX_OK; } ngx_log_error(NGX_LOG_ERR, r->connection->log, 0, "auth request unexpected status: %d", ctx->status);
return NGX_HTTP_UNAUTHORIZED; 默认返回500会被我们之前配的nginx截获,改成401的话我们也另配一个 权限认证失败的JSON返回即可
在使用这个模块进行权限校验的时候,我们还遇到其他坑:比如 auth_request 它默认是使用HTTP GET 来请求的,当我们使用proxy_method POST;指定请求方式为POST时会发现后端无法识别到POST数据,我们采用的是添加特定的头部这种低成本方式来处理。
后台也会有些下载功能,而且是那种需要根据具体帐号的权限来决定是否可以下载文件。比如
我们的CDN后台就有一个需要做权限控制的日志下载功能,前端界面如下:
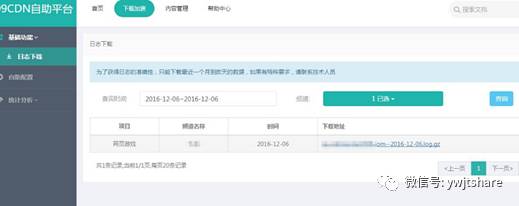
按照以前的老套路,要实现这样的下载控制,最原始的办法就是在程序里判断用户的权限,如果允许下载的话就会用类似python的readfile这类的函数读取文件后输出给浏览器。这样的办法可以实现下载控制,但它的缺点也是非常明显的,就是会占用大量内存和后端程序资源得不到释放,如果是大文件后端基本就瘫了,合理的方案应该是:程序判断权限合法后,将静态文件下载过程交给nginx处理
location log/ { alias var/cache/salt/master/minions/; #静态文件存放路径 internal; }
这里有个厉害的internal关键词,加入internal限定后,/log/地址只能通过内部访问也就是从后端返回收到的 response header 里的 X-Accel-Redirect 重定向才有效。利用这样的特性,我们就可以实现对下载文件的访问权限控制了。
class log(MainHandler): @lib.web.acl def get(self): log = self.get_argument('log', '')
if log: try: filepath = decrypt(log) except Exception, e: filepath = '' if os.path.exists(filepath): filepath = filepath.replace('/var/cache/salt/master/minions/', '') filepath = filepath.split('/') self.set_header('Content-Disposition', "attachment;filename=%s" % filepath[-1]) # 告诉浏览器这是一个文件,点击直接下载 self.set_header('X-Accel-Redirect', '/log/' + '/'.join(filepath)) self.set_header("X-Accel-Buffering", "yes") else: self.write('槽糕,没有找到日志文件') else: self.write('没有找到日志文件') self.finish()
这段主要是获取url中log的参数值,解密成功之后获取到文件名,如果文件存在,后端python将会在header中添加X-Accel-Redirect重定向到nginx,然后让他来轻松地提供下载逻辑。
普通网站在实现文件上传功能的时候,一般是使用Python,Java,PHP等后端程序实现,目前我们的后端场景是Tornado.如果使用Tornado上传文件默认系统是先写到内存,而且限制了上传文件的大小最大为100M,如果需要上传特大文件,强行上传的话会对内存造成很大压力,这里我们又把这个动作交给nginx来做,用nginx的Upload模块解决轻松处理,效果如下:
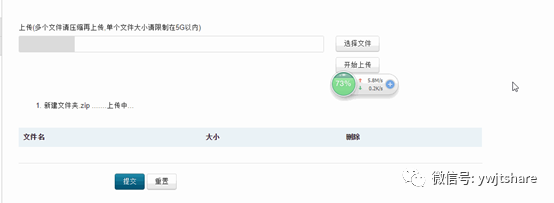
可以看到本地上传带宽已经跑满.只要你的上传带宽和浏览器缓存够,都不是事。
官方文档[源码下载](https://github.com/vkholodkov/nginx-upload-module/tree/2.2)
Nginx参考配置:
location upload/ { keepalive_timeout 300; #前端表单调用接口 upload_pass admin/handle; # 上传文件的临时目录 upload_store /data/web/dts/tmp; upload_store_access user:rw group:rw all:r; # 这里写入http报头,pass到后台页面后能获取这里set的报头字段 upload_set_form_field $upload_field_name.name "$upload_file_name"; upload_set_form_field $upload_field_name.content_type "$upload_content_type"; upload_set_form_field $upload_field_name.path "$upload_tmp_path"; upload_set_form_field $upload_field_name.path "$upload_tmp_path"; #表单自定义的字段(主要记录是谁上传以及一些文件信息) upload_pass_form_field "^listname$|^author$"; # Upload模块自动生成的一些信息,如文件大小与文件md5值 upload_aggregate_form_field "$upload_field_name.md5" "$upload_file_md5"; upload_aggregate_form_field "$upload_field_name.size" "$upload_file_size"; upload_pass_form_field "^type$|^path$"; upload_cleanup 400 404 499 500-505; } #后端真正处理接口 location /admin/handle { proxy_pass http://dts-wan/admin/handle; }
后端处理代码:
def upload(self): data = self.request.arguments form_value = [ ('filename.name', {'next': True, 'desc': '上传文件'}) ] form_reslut = check_form(form_value, data)
if form_reslut is not None: json = { 'error': 1, 'msg': form_reslut['msg'] } self.write(json) return upload_path = '/data/web/dts/upload/' filename = 'num_' + '{0:%Y%m%d%H%M%S%f}'.format(datetime.datetime.now()) filepath = upload_path + filename os.rename(data['filename.path'][0], filepath) self.write(filename) return
curl -F name=test -F passwd=**** filename=@/tmp/data.zip https://test.com/upload
Python是我们运维人员的必备,不过当和前端交互有比较难的逻辑时候我们可以尝试靠我们的利器Nginx模块来实现。
全中国只有不到1% 的人关注了运维军
你是个有眼光的人!
(由于交流群人数已超100人,需要进群的小伙伴可以添加运维小编的微信:Alxy0819)

如果你喜欢我们的文章,请转发到朋友圈





公众号
ywjtshare
运维军团

专注运维技术与传承,分享丰富原创干货


