




浅析ceph的FileStore与BlueStore
1.前言
ceph后端支持多种存储引擎,以插件化的形式来进行管理使用,我们常听到的其中两种存储引擎就是FileStore与BlueStore,在L版(包括L版)之前,默认使用的filestore作为默认的存储引擎,但是由于FileStore存在一些缺陷,重新设计开发了BlueStore,L版之后默认使用的存储引擎就是BlueStore了,我们这篇文章就来讨论为什么ceph就采用BlueStore替换了FileStore,BlueStore究竟好在哪里?
我们先来看一下整体的架构图,从架构上来看,ObjectStore对接了底层的各种Store引擎的IO操作,然后对上层屏蔽了具体的实现,并向上层提供对象(Object)、事务(Transaction)语义接口。
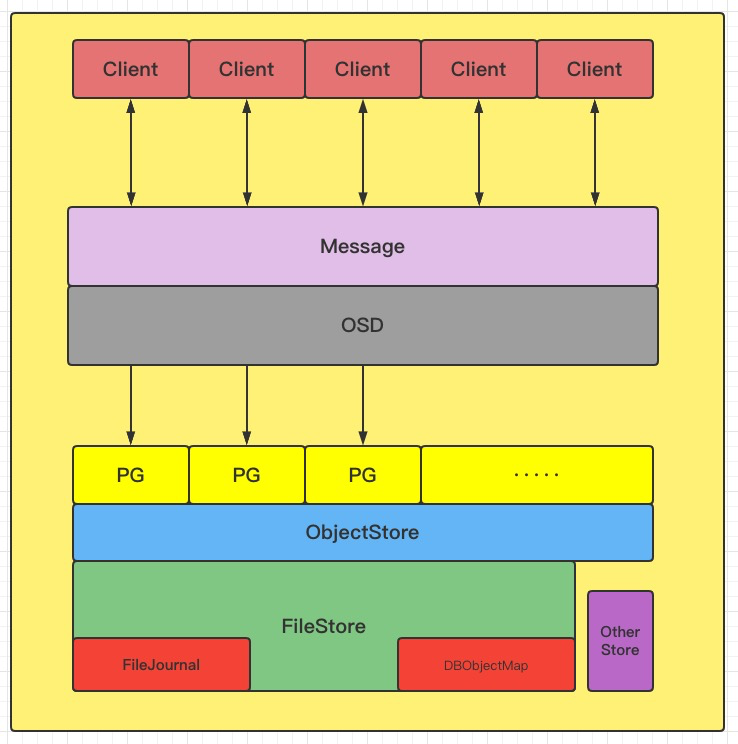
ObjectStore是Ceph OSD中最重要的概念之一,它封装了所有对底层存储的IO操作。从上图中可以看到所有IO请求在Clieng端发出,在Message层统一解析后会被OSD层分发到各个PG,每个PG都拥有一个队列,一个线程池会对每个队列进行处理。
当一个在PG队列里的IO被提出后,该IO请求会被根据类型和相关附带参数进行处理。如果是读请求会通过ObjectStore提供的API获得相应的内容,如果是写请求也会利用ObjectStore提供的事务API将所有写操作组合成一个原子事务提交给ObjectStore。ObjectStore通过接口对上层提供不同的隔离级别,目前PG层只采用了Serializable级别,保证读写的顺序性。
ObjectStore主要接口分为三部分,第一部分是Object的读写操作,类似于POSIX的部分接口,第二部分是Object的属性(xattr)读写操作,这类操作的特征是kv对并且与某一个Object关联。第三部分是关联Object的kv操作(在Ceph中称为omap),这个其实与第二部分非常类似,但是在实现上可能会有所变化。
2.FileStore
先看FileStore的整体架构图
从架构图我们可以看出来几个重要的组件:FileJournal、omap、XFS、DISK。我们来解读一个存储的流程是怎样的。
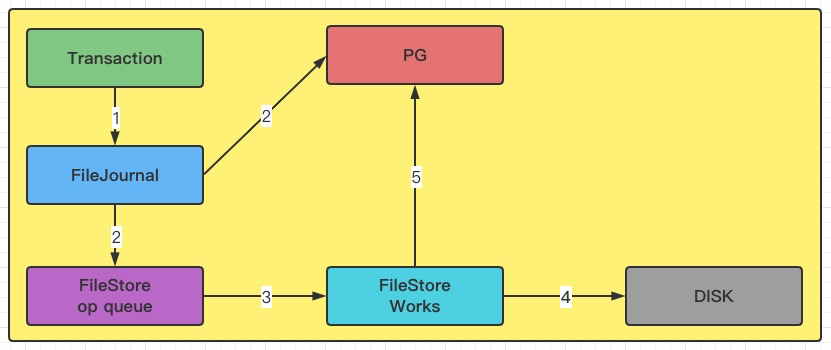
为了提高写事务的性能,提高写事物的处理能力并且实现事务的原子性,FileStore增加了FileJournal功能,所有的写事务在被FileJournal处理以后都会立即callback(上图中的第2步)。FileJournal类似于数据库的writeahead日志,使用O_DIRECT和O_DSYNC每次同步写入到journal文件,完成后该事务会被塞到FileStore的op queue。日志是按append only的方式处理的,每次都是被append到journal文件末尾;
ps:事务通常有若干个写操作组成,当在中间过程进程crash时,journal会OSD recover提供了完备的输入。
接着,FileStore采用多个thread的方式从op queue 这个 thread pool里获取op,然后真正apply事务数据到disk(文件系统pagecache)。当FileStore将事务落到disk上之后,后续的读请求才会继续(上图中的第5步)。
当FileStore完成一个op后,对应的Journal才可以丢弃这部分Journal。对于每一个副本都有这两步操作,先写journal,再写到disk,如果是3副本,就涉及到6次写操作,因此性能上体现不是很好。
实际上并不是所有的文件系统都按照这个顺序,一般来说如Ceph推荐的Ext4和XFS文件系统会先写入Journal,然后再写入Filesystem,而COW(Copy on Write)文件系统如Btrfs和ZFS会同时写入Journal和FileSystem。
3.BlueStore
Ceph原本的FileStore需要兼容Linux下的各种文件系统,如EXT4、BtrFS、XFS。理论上每种文件系统都实现了POSIX协议,但事实上,每个文件系统都有一点“不那么标准”的地方。Ceph的实现非常注重可靠性,因而需要为每种文件系统引入不同的Walkaround或者Hack;例如Rename不幂等性,等等。这些工作为Ceph的不断开发带来了很大负担。
其次,FileStore构建与Linux文件系统之上。POSIX提供了非常强大的功能,但大部分并不是Ceph真正需要的;这些功能成了性能的累赘。另一方面,文件系统的某些功能实现对Ceph并不友好,例如对目录遍历顺序的要求,等等。
另一方面,是Ceph日志的双写问题。为了保证覆写中途断电能够恢复,以及为了实现单OSD内的事物支持,在FileStore的写路径中,Ceph首先把数据和元数据修改写入日志,日志完后后,再把数据写入实际落盘位置。这种日志方法(WAL)是数据库和文件系统标准的保证ACID的方法。但用在Ceph这里,带来了问题:
数据被写入两遍,即日志双写问题,这意味着Ceph牺牲了一半的磁盘吞吐量。
Ceph的FileStore做了一遍日志,而Linux文件系统自身也有日志机制,实际上日志被多做了一遍。 对于新型的LSM-Tree类存储,如RocksDB、LevelDB,由于数据本身就按照日志形式组织,实际上没有再另加一个单独的WAL的必要。 更好地发挥SSD/NVM存储介质的性能。与磁盘不同,基于Flash的存储有更高的并行能力,需要加以利用。CPU处理速度逐渐更不上存储,因而需要更好地利用多核并行。存储中大量使用的队列等,容易引发并发竞争耗时,也需要优化。另一方面,RocksDB对SSD等有良好支持,它为BlueStore所采用。
另外,社区曾经为了FileStore的问题,提出用LevelDB作存储后端;对象存储转换为KeyValue存储,而不是转换问文件。后来,LevelDB存储没有被推广开,主流还是使用FileStore。但KeyValue的思路被沿用下来,BlueStore就是使用RocksDB来存储元数据的。
bluestore 的诞生是为了解决 filestore 自身维护一套journal 并同时还需要基于文件系统的写放大问题,并且 filestore 本身没有对 SSD 进行优化,因此 bluestore 相比于 filestore 主要做了两方面的核心工作:
去掉 journal ,直接管理裸设备 针对 SSD 进行单独优化
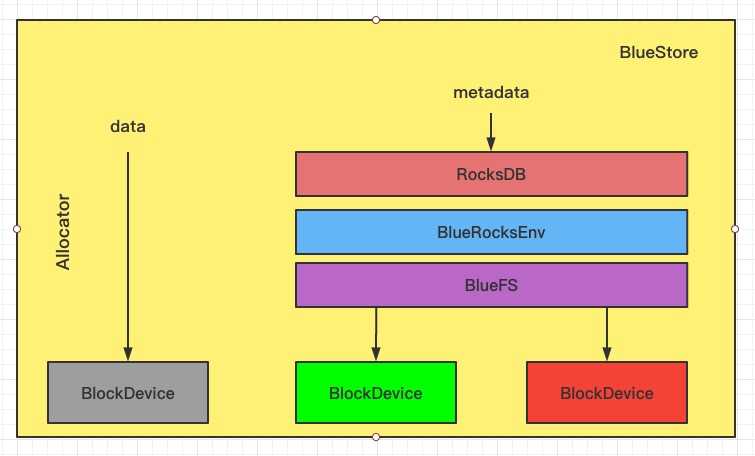
bluestore 整体架构如下图:
Bluestore实现了直接管理裸设备的方式,抛弃了本地文件系统,BlockDevice实现在用户态下使用linux aio直接对裸设备进行I/O操作,去除了本地文件系统的消耗,减少系统复杂度,更有利于Flash介质盘发挥性能优势
为了惯例裸设备就需要一个磁盘的空间管理系统,Bluestore采用Allocator进行裸设备的空间管理,目前支持StupidAllocator和BitmapAllocator两种方式
Bluestore的元数据是以KEY-VALUE的形式保存到RockDB里的,而RockDB又不能直接操作裸盘,为此,bluestore实现了一个BlueRocksEnv,继承自EnvWrapper,来为RocksDB提供底层文件系统的抽象接口支持
为了对接BlueRocksEnv,Bluestore自己实现了一个简洁的文件系统BlueFS,只实现RocksDB Env所需要的接口,在系统启动挂在这个文件系统的时候将所有的元数据都加载到内存中,BluesFS的数据和日志文件都通过BlockDevice保存到底层的裸设备上
BlueFS和BlueStore可以共享裸设备,也可以分别指定不同的设备,比如为了获得更好的性能Bluestore可以采用 SATA SSD 盘,BlueFS采用 NVMe SSD 盘。
「核心模块」
RocksDB:存储预写式日志、数据对象元数据、Ceph的omap数据信息、以及分配器的元数据(分配器负责决定真正的数据应在什么地方存储)
BlueRocksEnv:与RocksDB交互的接口
BlueFS:小的文件系统,解决元数据、文件空间及磁盘空间的分配和管理,并实现了rocksdb::Env 接口(存储RocksDB日志和sst文件)。因为rocksdb常规来说是运行在文件系统的顶层,下面是BlueFS。它是数据存储后端层,RocksDB的数据和BlueStore中的真正数据被存储在同一个块物理设备
BlockDevice(HDD/SSD):物理块设备,存储实际的数据
Allocator: 用来从空闲空间分配block(block是可分配的最小单位)
说明:
1.对象数据存储部分即osd指定的data设备(可以是裸盘分区,或者lvm卷,下同)
2.RocksDB日志即osd指定的wal设备
3.RocksDB数据部分即osd指定的db设备
4.以上设备可以共用同一物理盘设备,也可以分开在不同的物理设备,这充分体现了ceph的灵活性
总结
BlueStore 最大的特点是 OSD 可以直接管理裸磁盘设备,并且将对象数据存储在该设备中。另外对象有很多KV属性信息,这些信息之前是存储在文件的扩展属性或者LevelDB当中的。而在BlueStore中,这些信息存储在RocksDB当中。RocksDB本身是需要运行在文件系统之上的,因此为了使用RocksDB存储这些元数据,需要开发一个简单的文件系统(BlueFS)。
从BlueStore 的设计和实现上看,可以将其理解为用户态下的一个文件系统,同时使用RocksDB来实现BlueStore所有元数据的管理,简化实现。
对于整块数据的写入,数据直接以aio的方式写入磁盘,再更新RocksDB中数据对象的元数据,避免了filestore的先写日志,后apply到实际磁盘的两次写盘。同时避免了日志元数据的冗余存储占用,因为传统文件系统有他们自己内部的日志和元数据管理机制。
BlueStore 其实是实现了用户态的一个文件系统。为了实现简单,又使用了RocksDB来实现了BlueStore的所有元数据的管理,简化了实现。
优点在于:
对于整块数据的写入,数据直接 AIO 的方式写入磁盘,避免了 filestore的先写日志,后 apply到实际磁盘的两次写盘。 对于随机IO,直接 WAL 的形式,直接写入 RocksDB 高性能的 KV 存储中。
