




[TOC]
在MySQL中对SQL进行性能分析,通常的流程是从慢查询中发现存在性能问题的SQL,再分析这些SQL的资源使用情况以及执行计划。如果执行计划和预期不一致,可以尝试用optimizer trace分析。最后有针对性的进行优化。下边分别对这几个方面做一个简单的介绍。
1、慢查询日志
MySQL提供Slow query log 记录执行时间超过long_query_time,并且至少需要检查min_examined_row_limit行的SQL。利用慢日志可以发现系统之前执行的慢查询,慢查询日志包括SQL执行时间、获取锁的时间、检查的行数和返回的行数等信息。在8.0.14及以上版本可以打开log_slow_extra系统参数,收集更多信息。
慢查询日志相关参数如下:
#slow_query_log参数决定慢查询日志是否打开
mysql> select @@slow_query_log;
+------------------+
| @@slow_query_log |
+------------------+
| 1 |
+------------------+
#long_query_time支持微秒级精度
mysql> select @@long_query_time;
+-------------------+
| @@long_query_time |
+-------------------+
| 1.000000 |
+-------------------+
#log_slow_admin_statements参数开启后,执行较慢的管理语句将会被记录在慢查询日志中,包括ALTER TABLE, ANALYZE TABLE, CHECK TABLE, CREATE INDEX, DROP INDEX, OPTIMIZE TABLE, and REPAIR TABLE;
mysql> select @@log_slow_admin_statements;
+-----------------------------+
| @@log_slow_admin_statements |
+-----------------------------+
| 0 |
+-----------------------------+
#log_slow_slave_statements参数开启后,且binlog_format=statement或binlog_format=mixed且语句以statement格式记录时,从服务器会将复制的慢SQL写入慢日志
mysql> select @@log_slow_slave_statements;
+-----------------------------+
| @@log_slow_slave_statements |
+-----------------------------+
| 0 |
+-----------------------------+
#log_queries_not_using_indexes参数开启后,所有(表数据大于2行)不使用索引的查询会被记录。如果这类查询较多,可以使用参数log_throttle_queries_not_using_indexes限制;
mysql> select @@log_queries_not_using_indexes;
+---------------------------------+
| @@log_queries_not_using_indexes |
+---------------------------------+
| 0 |
+---------------------------------+
#log_throttle_queries_not_using_indexes每分钟有多少不使用索引的查询可被记录在慢查询日志中;
mysql> select @@log_throttle_queries_not_using_indexes;
+------------------------------------------+
| @@log_throttle_queries_not_using_indexes |
+------------------------------------------+
| 0 |
+------------------------------------------+
在8.0.14及以上版本可以打开log_slow_extra系统参数,收集更多信息
#set log_slow_extra=off
# Time: 2021-01-06T09:57:47.473598+08:00
# User@Host: root[root] @ localhost [] Id: 23
# Query_time: 10.360508 Lock_time: 0.000145 Rows_sent: 1 Rows_examined: 2
SET timestamp=1609898257;
select *,sleep(300) from test.t1;
#set log_slow_extra=on
# Time: 2021-01-21T15:50:31.859840+08:00
# User@Host: root[root] @ localhost [] Id: 8
# Query_time: 206.028533 Lock_time: 0.000118 Rows_sent: 206 Rows_examined: 206 Thread_id: 8 Errno: 0 Killed: 0 Bytes_received: 0 Bytes_sent: 8238 Read_first: 1 Read_last: 0 Read_key: 1 Read_next: 0 Read_pre
v: 0 Read_rnd: 0 Read_rnd_next: 207 Sort_merge_passes: 0 Sort_range_count: 0 Sort_rows: 0 Sort_scan_count: 0 Created_tmp_disk_tables: 0 Created_tmp_tables: 0 Start: 2021-01-21T15:47:05.831307+08:00 End: 2021-
01-21T15:50:31.859840+08:00
SET timestamp=1611215225;
select *,sleep(1) from test.t1;
Time:log记录的时间;
User@Host:SQL执行的用户以及主机;
id:连接的标识;
Query_time:SQL执行的时间;
Lock_time:获取锁的时间;
Rows_sent:返回客户端的结果行数;
Rows_examined:server层检查的行数;
Thread_id:连接的标识;
Errno:SQL错误号,0表示没有错误;
Killed:语句终止的错误号,0表示正常终止;
Bytes_received/sent:收到和发送的字节数;
Read_first:Handler_read_first的值,代表读取索引中第一个条目的次数。反映查询全索引扫描的次数。
Read_last:读取索引最后一个key的次数;
Read_key:基于key读取行的请求数,较大说明使用正确的索引
Read_next:按顺序取下一行数据的次数,索引范围查找和索引扫描时该值会增大;
Read_prev:按顺序读取上一行的请求数,order by desc查询较优时该值较大;
Read_rnd:按固定位置读取行的请求数,大量的回表、没有索引的连接和对结果集排序时会增加;
Read_rnd_next:读取数据文件下一行的次数,大量表扫描、未创建或合理使用索引时会增加;
Sort_range_count:使用范围完成的排序次数;
Sort_rows:排序的行数;
Sort_scan_count:通过扫描表完成的排序次数;
Sort_merge_passes:排序算法合并的次数,如该值较大考虑增加sort_buffer_size的值
Created_tmp_disk_tables:创建内部磁盘临时表的数量;
Created_tmp_tables:创建内部临时表的数量;
Start/End:语句开始和结束时间

慢查询日志中包含大量慢查询信息,绝大多数时候没办法通过查看一两条慢查询日志定位问题,通常需要分析慢日志找到一段时间执行次数最多或总执行时间最长的那几类SQL。MySQL和percona_toolkit都提供了慢查询分析工具,方便我们根据需求对慢查询进行分析并返回结果。
- mysqldumpslow,mysql自带慢查询日志分析工具
[root@node1 ~]# mysqldumpslow --help
Usage: mysqldumpslow [ OPTS... ] [ LOGS... ]
Parse and summarize the MySQL slow query log. Options are
--verbose verbose
--debug debug
--help write this text to standard output
-v verbose
-d debug
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
常用参数:
-r 倒序排列
-n 只显示前n个记录
-a 不对数字和字符串进行抽象
-g 字符串过滤
-t NUM 返回top n 查询
-s
al平均锁等待时间排序
at平均查询时间排序
ar平均返回行数排序
c 出现总次数排序
l等待锁的时间排序
r 返回总行数排序
t 累计查询耗时排序
返回平均查询时间前5的SQL: mysqldumpslow -s at -t 5 /data/mysql/data/node1-slow.log
返回累计查询时间前5的SQL:mysqldumpslow -s t -t 5 /data/mysql/data/node1-slow.log
返回总次数前5的SQL:mysqldumpslow -s c -t 5 /data/mysql/data/node1-slow.log
- pt-query-digest,是Percona-toolkit中的工具可以从普通日志、慢查询日志、二进制日志以及show processlist和tcpdump中对SQL进行分析。默认对慢日志进行分析,按总执行时间对SQL排序。如下所示输出主要分三部分。
[root@node1 ~]# pt-query-digest /data/mysql/data/node1-slow.log
# 990ms user time, 60ms system time, 36.81M rss, 250.61M vsz
# Current date: Sat Feb 20 10:51:22 2021
# Hostname: node1
# Files: /data/mysql/data/node1-slow.log
第一部分整体概要,对当前实例各项指标进行统计和初步的分析;包括总的查询次数、SQL数量、QPS以及并发;对执行时间、锁、检查返回行数等指标进行统计;
# Overall: 319 total, 38 unique, 0.00 QPS, 0.00x concurrency _____________
# Time range: 2021-01-04T15:58:47 to 2021-02-19T17:50:12
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 1656s 15us 206s 5s 10s 18s 1s
# Lock time 3s 0 58ms 11ms 34ms 11ms 8ms
# Rows sent 196.55k 0 97.66k 630.93 1.96 7.66k 0
# Rows examine 17.41M 0 8.45M 55.90k 202.40 637.31k 0
# Bytes sent 23.55k 11 8.04k 3.93k 7.68k 3.67k 7.31k
# Query size 99.50M 6 511.97k 319.39k 509.78k 246.93k 509.78k
# Bytes receiv 0 0 0 0 0 0 0
# Created tmp 0 0 0 0 0 0 0
# Created tmp 1 0 1 0.17 0.99 0.37 0
# Errno 0 0 0 0 0 0 0
# Read first 3 0 1 0.50 0.99 0.50 0.99
# Read key 9 0 7 1.50 6.98 2.49 0.99
# Read last 0 0 0 0 0 0 0
# Read next 0 0 0 0 0 0 0
# Read prev 0 0 0 0 0 0 0
# Read rnd 0 0 0 0 0 0 0
# Read rnd nex 1.75k 0 1.14k 298.17 1.09k 381.70 202.40
# Sort merge p 0 0 0 0 0 0 0
# Sort range c 0 0 0 0 0 0 0
# Sort rows 0 0 0 0 0 0 0
# Sort scan co 0 0 0 0 0 0 0
第二部分Profile:对重要或较慢查询进一步分析
Rank:排名
Response time “语句”的响应时间以及整体占比情况。
Calls 该“语句”的执行次数。
R/Call 每次执行的平均响应时间。
V/M 响应时间的方差均值比(VMR) (值越大这类SQL响应时间越趋于不同)。
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== =================================== ============== ===== ======== =
# 1 0x2A60E950668C2A9E6E3FE8E7DE07DC85 466.6741 28.2% 8 58.3343 91.30 SELECT test.t?
# 2 0x3CD51FB9DF3783D29620DE55B1685F80 400.0233 24.1% 40 10.0006 0.00 SELECT
# 3 0x678A524E5A67CA481507CC73DE6D9841 301.7842 18.2% 199 1.5165 0.03 INSERT sbtest?
# 4 0x80401632431285CE1994A5AC4FDFBA94 120.3506 7.3% 1 120.3506 0.00 UPDATE sbtest?
# 5 0xC54312D080D0904F754521EF548E3A43 91.6045 5.5% 3 30.5348 55.75 SELECT t?
# 6 0xBB3D32983879EC6569C7AC70B48B0F41 91.1383 5.5% 1 91.1383 0.00 UPDATE sbtest?
# 7 0xB6BECB44E26A3852A094278172FC39B7 60.2594 3.6% 1 60.2594 0.00 SELECT information_schema.INNODB_BUFFER_PAGE
# 8 0x7B9244C7142565E8D2A0F466599F3F19 47.5887 2.9% 4 11.8972 0.28 UPDATE sbtest?
# MISC 0xMISC 77.0490 4.7% 62 1.2427 0.0 <30 ITEMS>
第三部分详细信息。Profile中各SQL的详细信息,默认按总的Exec Time降序输出
# Query 1: 0.00 QPS, 0.00x concurrency, ID 0x2A60E950668C2A9E6E3FE8E7DE07DC85 at byte 16890
# Scores: V/M = 91.30
# Time range: 2021-01-06T09:56:31 to 2021-01-21T15:50:31
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 2 8
# Exec time 28 467s 6s 206s 58s 202s 73s 32s
# Lock time 0 5ms 118us 2ms 675us 2ms 670us 570us
# Rows sent 0 213 1 206 26.62 202.40 66.61 0.99
# Rows examine 0 220 2 206 27.50 202.40 66.29 1.96
# Bytes sent 34 8.04k 8.04k 8.04k 8.04k 8.04k 0 8.04k
# Query size 0 394 31 60 49.25 59.77 13.60 59.77
# Bytes receiv 0 0 0 0 0 0 0 0
# Created tmp 0 0 0 0 0 0 0 0
# Created tmp 0 0 0 0 0 0 0 0
# Errno 0 0 0 0 0 0 0 0
# Read first 33 1 1 1 1 1 0 1
# Read key 11 1 1 1 1 1 0 1
# Read last 0 0 0 0 0 0 0 0
# Read next 0 0 0 0 0 0 0 0
# Read prev 0 0 0 0 0 0 0 0
# Read rnd 0 0 0 0 0 0 0 0
# Read rnd nex 11 207 207 207 207 207 0 207
# Sort merge p 0 0 0 0 0 0 0 0
# Sort range c 0 0 0 0 0 0 0 0
# Sort rows 0 0 0 0 0 0 0 0
# Sort scan co 0 0 0 0 0 0 0 0
# String:
# Databases test
# End 2021-01-21T15:50:31.859840+08:00
# Hosts localhost
# Start 2021-01-21T15:47:05.831307+08:00
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ######################################
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS FROM `test` LIKE 't1'\G
# SHOW CREATE TABLE `test`.`t1`\G
# EXPLAIN /*!50100 PARTITIONS*/
select *,sleep(1) from test.t1\G
# Query 2: 0.00 QPS, 0.00x concurrency, ID 0x3CD51FB9DF3783D29620DE55B1685F80 at byte 31747
# Scores: V/M = 0.00
# Time range: 2021-02-03T12:01:08 to 2021-02-04T14:14:25
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 12 40
# Exec time 24 400s 10s 10s 10s 10s 0 10s
# Lock time 0 0 0 0 0 0 0 0
# Rows sent 0 40 1 1 1 1 0 1
# Rows examine 0 40 1 1 1 1 0 1
# Query size 0 680 17 17 17 17 0 17
# String:
# Databases sysbench_1
# Hosts 127.0.0.1
# Users test
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s
# 10s+ ################################################################
# EXPLAIN /*!50100 PARTITIONS*/
select sleep (10)\G
# Query 4: 0 QPS, 0x concurrency, ID 0x80401632431285CE1994A5AC4FDFBA94 at byte 104399244
# Scores: V/M = 0.00
# Time range: all events occurred at 2021-02-04T16:48:22
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 0 1
# Exec time 7 120s 120s 120s 120s 120s 0 120s
# Lock time 0 228us 228us 228us 228us 228us 0 228us
# Rows sent 0 0 0 0 0 0 0 0
# Rows examine 48 8.45M 8.45M 8.45M 8.45M 8.45M 0 8.45M
# Query size 0 56 56 56 56 56 0 56
# String:
# Databases sysbench_1
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS FROM `sysbench_1` LIKE 'sbtest2'\G
# SHOW CREATE TABLE `sysbench_1`.`sbtest2`\G
# SHOW TABLE STATUS FROM `sysbench_1` LIKE 'sbtest1'\G
# SHOW CREATE TABLE `sysbench_1`.`sbtest1`\G
update sbtest2 b,sbtest1 a set b.pad=a.pad where b.c=a.c\G
# Converted for EXPLAIN
# EXPLAIN /*!50100 PARTITIONS*/
select b.pad=a.pad from sbtest2 b,sbtest1 a where b.c=a.c\G
# Query 5: 0.00 QPS, 0.00x concurrency, ID 0xC54312D080D0904F754521EF548E3A43 at byte 0
# Scores: V/M = 55.75
# Time range: 2021-01-04T15:58:47 to 2021-01-05T13:44:50
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 0 3
# Exec time 5 92s 601ms 90s 31s 88s 41s 992ms
# Lock time 0 485us 120us 222us 161us 214us 41us 138us
# Rows sent 0 19 3 10 6.33 9.83 2.84 5.75
# Rows examine 0 19 3 10 6.33 9.83 2.84 5.75
# Query size 0 80 26 27 26.67 26.08 0.50 26.08
# String:
# Databases test
# Hosts localhost (2/66%), 127.0.0.1 (1/33%)
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms ################################################################
# 1s ################################################################
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS FROM `test` LIKE 't1'\G
# SHOW CREATE TABLE `test`.`t1`\G
# EXPLAIN /*!50100 PARTITIONS*/
select *,sleep(30) from t1\G
# Query 6: 0 QPS, 0x concurrency, ID 0xBB3D32983879EC6569C7AC70B48B0F41 at byte 104399244
# Scores: V/M = 0.00
# Time range: all events occurred at 2021-02-04T16:50:17
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 0 1
# Exec time 5 91s 91s 91s 91s 91s 0 91s
# Lock time 0 197us 197us 197us 197us 197us 0 197us
# Rows sent 0 0 0 0 0 0 0 0
# Rows examine 42 7.44M 7.44M 7.44M 7.44M 7.44M 0 7.44M
# Query size 0 56 56 56 56 56 0 56
# String:
# Databases sysbench_1
# Hosts localhost
# Users root
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s
# 10s+ ################################################################
# Tables
# SHOW TABLE STATUS FROM `sysbench_1` LIKE 'sbtest2'\G
# SHOW CREATE TABLE `sysbench_1`.`sbtest2`\G
# SHOW TABLE STATUS FROM `sysbench_1` LIKE 'sbtest1'\G
# SHOW CREATE TABLE `sysbench_1`.`sbtest1`\G
update sbtest2 b,sbtest1 a set b.pad=a.pad where b.k=a.k\G
# Converted for EXPLAIN
# EXPLAIN /*!50100 PARTITIONS*/
select b.pad=a.pad from sbtest2 b,sbtest1 a where b.k=a.k\G
除默认参数外pt-query-digest还提供较丰富的参数
type:指定输入文件的类型,默认是slowlog
slowlog输入是MySQL慢查询日志
binlog 输入是mysqlbinlog转换后的二进制日志
genlog 输入是MySQL general log
tcpdump 分析tcpdump抓包内容,建议以-x -n -q -tttt格式化抓包输出
rawlog 输入不是MySQL日志,而是换行分隔的SQL语句;
Group-by:指定分类的属性,默认是fingerprint
order-by:指定排序方式,默认是Query_time:sum。聚合方式包括sum、min、max、cnt
2、Performance Schema
MySQL在之前的版本中可以使用show profile查看当前会话中执行的SQL使用资源的情况。后续版本建议使用Performance Schema来做相关的分析。
- 使用Performance Schema收集监控信息对性能有影响(极端条件下会有数倍的耗时增加),我们需要配置performance_schema.setup_actors表来限制主机、用户或帐户对历史事件的收集,以减少运行时开销和历史表中收集的数据量。默认setup_actors 被配置为允许对所有前台线程进行监控和历史事件收集。

修改默认配置为NO,添加规则只放开当前用户的监控和历史事件收集
UPDATE performance_schema.setup_actors SET ENABLED = 'NO', HISTORY = 'NO' WHERE HOST = '%' AND USER = '%';
insert into performance_schema.setup_actors values (substring_index(current_user(),'@',-1),substring_index(current_user(),'@',1),'%','YES','YES');

- 开启statement和stage探测
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES' WHERE NAME LIKE '%statement/%';
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES' WHERE NAME LIKE '%stage/%';

- 开启events_statements_ 和 events_stages_ 的 consumers
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE '%events_statements_%';
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE '%events_stages_%';

- 查询event_id。做好以上配置后,前面 在performance_schema.setup_actors表中配置的用户的SQL就可以通过查询performance_schema.events_statements_history_long表获取event_id(类似于通过SHOW PROFILES 获取 query_id)
select EVENT_ID,format(TIMER_WAIT/1000000000000,2),truncate(LOCK_TIME/1000000000000,2),SQL_TEXT from performance_schema.events_statements_history_long where SQL_TEXT like '%sbtest%';


- 查询performance_schema.events_stages_history_long表,获取对应SQL的资源使用情况。
SELECT event_name AS Stage, source,TRUNCATE(TIMER_WAIT/1000000000000,6) AS Duration FROM performance_schema.events_stages_history_long WHERE NESTING_EVENT_ID=31;

- 查询performance_schema.events_statements_summary_by_digest表获取类似SQL的摘要信息
select * from performance_schema.events_statements_summary_by_digest where DIGEST_TEXT like '%sbtest%'\G

3、explain
MySQL提供Explain工具查看某个SQL的执行计划,默认使用时SQL并不会真正执行。注意,在只读实例上无法查看写入SQL的执行计划;explain的用法如下:
Explain [format=(triditional|tree|json)] SQL
- format=triditional(默认值)以表格格式输出,各字段的含义如下

| 字段名 | 含义 |
|---|---|
| id | 操作表顺序。执行顺序id从大到小,id相同从上到下 |
| select_type | 查询类型。(smiple/primary/union/subquery/dependent subquery/materialized) |
| Type | 查询数据的具体访问方式(system/const/eq_ref/ref/range/index/all) |
| possible_key&key | 可能用到的和实际选择的索引 |
| key_len | 使用索引的长度(组合索引的一部分) |
| Ref | 使用索引列做等值匹配时,匹配的列 |
| Row | 预计扫描的行数或索引记录数 |
| Filtered | 扫描的行数中符合其他条件的比例。 |
| Extra | 其他关键信息(using where/using filesort/using index/using temporary) |
下面对一些字段的不同取值做一下说明,其中数据扫描方式(TYPE) 的性能从const到all逐渐降低。
| 字段名 | 取值 | 说明 |
|---|---|---|
| 查询类型(select_type) | simple | 不包括union或子查询 |
| 查询类型(select_type) | Primary | 包含union或子查询的最外层查询 |
| 查询类型(select_type) | union | 子查询中除了primary的查询 |
| 查询类型(select_type) | Union result | 使用临时表对union结果去重 |
| 查询类型(select_type) | subquery | 不能转换成semi-join的不相关子查询 |
| 查询类型(select_type) | dependent subquery | 不能转换成semi-join的相关子查询 |
| 查询类型(select_type) | Derived | 采用物化的方式执行的查询 |
| 查询类型(select_type) | Materialized | 子查询物化后与外层进行连接查询 |
| 数据扫描方式(TYPE) | Const | 使用主键或唯一索引等值查询 |
| 数据扫描方式(TYPE) | eq_ref | 连接查询被驱动表通过主键或唯一索引等值匹配 |
| 数据扫描方式(TYPE) | Ref | 非唯一索引等值匹配 |
| 数据扫描方式(TYPE) | range | 范围查询 |
| 数据扫描方式(TYPE) | Index | 覆盖索引扫描 |
| 数据扫描方式(TYPE) | ALL | 全表扫描 |
| 其他关键信息(Extra) | Impossible WHERE | 条件肯定为false时 |
| 其他关键信息(Extra) | using filesort | 使用排序算法排序 |
| 其他关键信息(Extra) | using temptemporary | 使用临时表 |
| 其他关键信息(Extra) | using where | 需要回表 |
| 其他关键信息(Extra) | using index | 覆盖索引扫描 |
-
指定format=json 执行计划以json格式输出,同triditional格式不同的地方除了呈现方式外,还有某些属性的名称也发生了变化,json格式还返回了优化器预估的执行开销;

-
当指定format=tree时执行计划以树状输出,这也是显示hash join用法的唯一方式。返回的执行计划也包括优化器预估的执行开销和符合条件的行数。

-
在执行explain以后还可以执行show warnings命令查看extended信息,在8.0.12以后的版本扩展信息对select、delete、insert、replace和update语句生效,之前的版本只能用于select。extended信息显示优化器如何限定语句中的表名和列名,以及经应用重写和优化规则改写后的SQL,和一些优化过程中的注释。

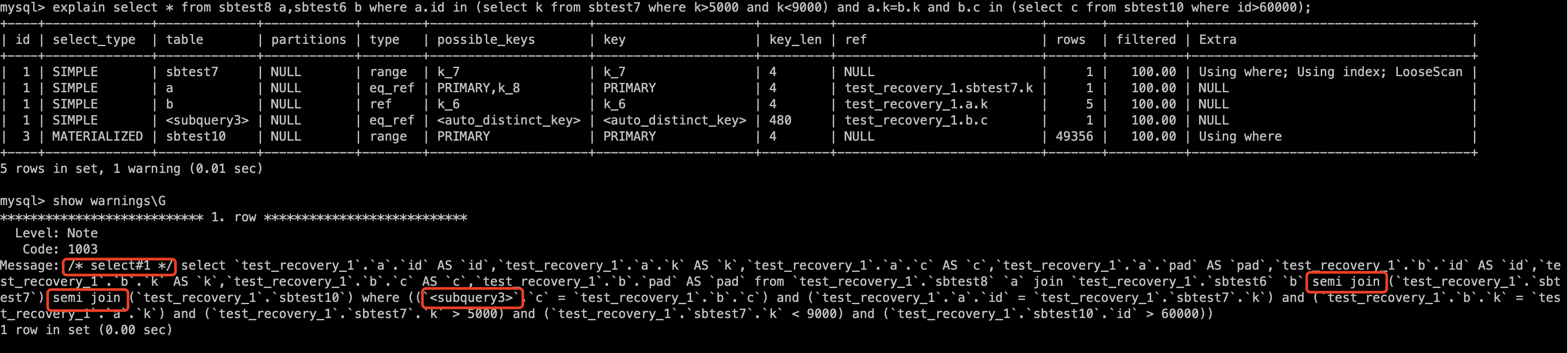
如上图所示,优化改写后将where子句中的1=1做了remove_eq_conds操作,将a.c=b.c and b.c=c.c 做了build_equal_items操作转换成
a.c=b.c and a.c=c.c 。此外在message中可能还会包含一些标记作为优化器操作的解释性说明。如下图,增加了 /* select#1 */,
- MySQL8.0.18开始支持Explain analyze,Explain analyze按format=tree格式输出,除了返回预估的成本和返回行数外,还会真正的执行这个SQL并返回实例的执行时间、返回行数和循环次数;因为会真正执行SQL,在8.0.20以后可以通过kill query或 CTRL-C终止运行。

对于每个iterator 会返回预估的执行成本和返回行数,实际执行返回第一行的时间(毫秒)和返回所有行的时间(毫秒),返回的行数 以及循环次数。
4、optimizer trace
MySQL提供optimizer trace工具剖析SQL执行过程中优化器选择执行计划的过程,如果执行计划和预期不一致,可以尝试用optimizer trace分析;使用方式如下
# 开启tracing (it's off by default):
SET optimizer_trace="enabled=on";
SELECT ...; # 执行SQL
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;#查看上一个SQL的trace
# 可以继续执行SQL并查看trace
# 关闭tracing:
SET optimizer_trace="enabled=off";
#注意:一个会话只能查看他执行的SQL的trace

控制optimizer trace的参数如下
mysql> show global variables like '%optimizer%trace%';
+------------------------------+----------------------------------------------------------------------------+
| Variable_name | Value |
+------------------------------+----------------------------------------------------------------------------+
| optimizer_trace: | enabled=off,one_line=off |
| optimizer_trace_features | greedy_search=on,range_optimizer=on,dynamic_range=on,repeated_subselect=on |
| optimizer_trace_limit | 1 |
| optimizer_trace_max_mem_size | 1048576 |
| optimizer_trace_offset | -1 |
+------------------------------+----------------------------------------------------------------------------+
5 rows in set (0.00 sec)
#optimizer_trace: enabled=on/off(开启或关闭tracing);one_line=on/off(如果on则返回trace结果无空格,只能有JSON解析器读取分析,节省空间)
#optimizer_trace_features:选择要跟踪的优化器功能;某些功能在优化和执行阶段会多次调用,导致trace结果膨胀很大。可以通过该参数控制是否追踪
1、greedy_search(贪婪搜索):当多表join时可能探索阶乘(N)个计划;设置为off则不跟踪greedy_search;
2、range_optimizer(范围优化器):设置为off则不跟踪范围优化;
3、dynamic_range(动态范围优化):每个outer row都会导致重新执行范围优化。在explain的输出中体现为 "range checked for each record" ;设置为off则只跟踪JOIN_TAB::SQL_SELECT的第一次范围优化调用;
4、repeated_subselect(重复子查询):每一行可能导致where子句中的子查询执行一次;设置为off则只跟踪Item_subselect的第一次调用;
#optimizer_trace_limit:正整数,显示trace的最大数量;
#optimizer_trace_offset:有符号整数,显示的第一个trace偏移量;
上两个参数通常配合使用以记录需要的trace,减少内存使用:SET optimizer_trace_offset=<OFFSET>, optimizer_trace_limit=<LIMIT>;
如OFFSET=0 and LIMIT=3 表示记录前三个trace。OFFSET=-5 and LIMIT=5记录最后5个。OFFSET=-2 and LIMIT=1记录倒数第二个。默认的OFFSET=-1 and LIMIT=1 记录最后一个;
#optimizer_trace_max_mem_size:允许存储的trace最大值。达到最大值后不再记录;INFORMATION_SCHEMA.OPTIMIZER_TRACE表中MISSING_BYTES_BEYOND_MAX_MEM_SIZE字段记录丢弃了多少直接的tace信息;
下面做一个简单的测试

查询INFORMATION_SCHEMA.OPTIMIZER_TRACE表,返回最后三个查询的trace。可以看到由于optimizer_trace_max_mem_size参数的限制,后两个SQL的trace都有一部分信息被丢弃(MISSING_BYTES_BEYOND_MAX_MEM_SIZE不等于0)

INFORMATION_SCHEMA.OPTIMIZER_TRACE表中各字段含义如下:
QUERY: SQL文本
TRACE:JSON格式的trace内容
MISSING_BYTES_BEYOND_MAX_MEM_SIZE:丢弃的trace内容字节数
INSUFFICIENT_PRIVILEGES:在查询使用 SQL SECURITY DEFINER 视图或存储例程的复杂场景中,用户可能被拒绝查看其查询的跟踪,因为它缺乏对这些对象的一些额外特权。 在这种情况下,跟踪将显示为空,并且 INSUFFICIENT_PRIVILEGES 列将显示“1”。
trace的结构中执行路径的每一个JOIN包含join_preparation对象,join_optimization对象和join_execution对象。IN->EXISTS, outer join to inner join…等查询转换,消除子句等简化 以及 等值/常量传递等优化存储在子对象中。trace中还显示了range optimizer调用、成本预估、访问路径的选择等信息。
下面以一个具体的例子分析下trace内容
#开启追踪(END_MARKERS_IN_JSON开启后,trace结果中每一步结束后会有类似’/* transformations_to_nested_joins */‘这样的标注,方便阅读。)
mysql> SET OPTIMIZER_TRACE="enabled=on",END_MARKERS_IN_JSON=on;
Query OK, 0 rows affected (0.00 sec)
#调整trace存储限制
mysql> SET OPTIMIZER_TRACE_MAX_MEM_SIZE=1000000;
Query OK, 0 rows affected (0.00 sec)
#执行SQL
mysql> select sum(a.id),b.c from sbtest7 a join sbtest9 b on a.c=b.id where a.id<5000 group by b.id;
Empty set (0.18 sec)
#为方便查看将trace导出到文件
mysql> SELECT TRACE INTO DUMPFILE '/tmp/trace.json' FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
Query OK, 1 row affected (0.02 sec)
#查看trace结果
cat /tmp/trace1.json

-
join_preparation对象。
这里只有一个select(“select#”: 1)。可以看到join_preparation阶段做了字段解析,将join条件加入where子句以及括号去除等操作。
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select sum(`a`.`id`) AS `sum(a.id)`,`b`.`c` AS `c` from (`sbtest7` `a` join `sbtest9` `b` on((`a`.`c` = `b`.`id`))) where (`a`.`id` < 5000) group by `b`.`id`"
},
{
"transformations_to_nested_joins": {
"transformations": [
"JOIN_condition_to_WHERE",
"parenthesis_removal"
] /* transformations */,
"expanded_query": "/* select#1 */ select sum(`a`.`id`) AS `sum(a.id)`,`b`.`c` AS `c` from `sbtest7` `a` join `sbtest9` `b` where ((`a`.`id` < 5000) and (`a`.`c` = `b`.`id`)) group by `b`.`id`"
} /* transformations_to_nested_joins */
}
] /* steps */
} /* join_preparation */
- join_optimization对象

可以看到条件处理部分没有做太多的事情
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "((`a`.`id` < 5000) and (`a`.`c` = `b`.`id`))",#原始条件
"steps": [
{
"transformation": "equality_propagation", #等值传递
"resulting_condition": "((`a`.`id` < 5000) and (`a`.`c` = `b`.`id`))"
},
{
"transformation": "constant_propagation", #常量传递
"resulting_condition": "((`a`.`id` < 5000) and (`a`.`c` = `b`.`id`))"
},
{
"transformation": "trivial_condition_removal", #无用条件去除
"resulting_condition": "((`a`.`id` < 5000) and (`a`.`c` = `b`.`id`))"
}
] /* steps */
} /* condition_processing */
},
虚拟列替换没有操作,确定了表依赖关系
{
"substitute_generated_columns": { #虚拟列替换
} /* substitute_generated_columns */
},
{
"table_dependencies": [ #表依赖关系
{
"table": "`sbtest7` `a`", #表名
"row_may_be_null": false, #是否可以为空,内连接为false
"map_bit": 0, #表映射编号 从0开始
"depends_on_map_bits": [ #依赖的表编号,内连接没有
] /* depends_on_map_bits */
},
{
"table": "`sbtest9` `b`",
"row_may_be_null": false,
"map_bit": 1,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
关联索引优化,列出了所有可用的ref访问。这里null_rejecting=true,说明a.c中任何null值都不能匹配
{
"ref_optimizer_key_uses": [
{
"table": "`sbtest9` `b`",
"field": "id",
"equals": "`a`.`c`",
"null_rejecting": true
}
] /* ref_optimizer_key_uses */
},
rows_estimation部分对SQL中的每张表列出表扫描,索引范围访问的成本和预估返回行数。
{
"rows_estimation": [
{
"table": "`sbtest7` `a`", #sbtest7的单表访问方式选择
"range_analysis": {
"table_scan": { #全表扫描
"rows": 98704, #全表扫描预估行数
"cost": 11251.5 #全表扫描预估成本
} /* table_scan */,
"potential_range_indexes": [ #可能的范围扫描索引评估
{
"index": "PRIMARY",
"usable": true, #主键可用
"key_parts": [
"id"
] /* key_parts */
},
{
"index": "k_7",
"usable": false, #k_7索引不可用
"cause": "not_applicable" #不可用原因不适用
}
] /* potential_range_indexes */,
"setup_range_conditions": [ #索引下推
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_single_table" #非单表查询不能使用索引优化group
} /* group_index_range */,
"skip_scan_range": {
"chosen": false,
"cause": "not_single_table" #非单表查询不能使用skip_scan_range
} /* skip_scan_range */,
"analyzing_range_alternatives": { #分析各索引的使用成本
"range_scan_alternatives": [
{
"index": "PRIMARY",
"ranges": [
"id < 5000"
] /* ranges */,
"index_dives_for_eq_ranges": true, #是否使用index dive
"rowid_ordered": true, #获取记录是否按主键排序
"using_mrr": false, #是否使用mrr
"index_only": false, #是否使用覆盖索引扫描
"rows": 10236, #预估行数
"cost": 1034.3, #预估成本
"chosen": true #是否选择
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": { #是否使用index merge
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */,
"chosen_range_access_summary": { #最终选择的单表访问方法
"range_access_plan": {
"type": "range_scan",
"index": "PRIMARY",
"rows": 10236,
"ranges": [
"id < 5000"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 10236,
"cost_for_plan": 1034.3,
"chosen": true
} /* chosen_range_access_summary */
} /* range_analysis */
},
{
"table": "`sbtest9` `b`", #sbtest9的单表访问方式选择
"const_keys_added": {
"keys": [
"PRIMARY",
"k_9"
] /* keys */,
"cause": "group_by"
} /* const_keys_added */,
"range_analysis": {
"table_scan": {
"rows": 98742,
"cost": 11191.3
} /* table_scan */,
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": true,
"key_parts": [
"id"
] /* key_parts */
},
{
"index": "k_9",
"usable": true,
"key_parts": [
"k",
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_single_table"
} /* group_index_range */,
"skip_scan_range": {
"chosen": false,
"cause": "not_single_table"
} /* skip_scan_range */
} /* range_analysis */
}
] /* rows_estimation */
},
considered_execution_plans对不同执行计划的成本进行评估
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`sbtest7` `a`", #执行计划一,sbtest7作为驱动表
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 10236,
"filtering_effect": [
] /* filtering_effect */,
"final_filtering_effect": 1,
"access_type": "range",
"range_details": {
"used_index": "PRIMARY"
} /* range_details */,
"resulting_rows": 10236,
"cost": 2057.9,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 10236,
"cost_for_plan": 2057.9, #使用主键做范围查询,预估返回10236行数据,成本2057.9
"rest_of_plan": [
{
"plan_prefix": [
"`sbtest7` `a`"
] /* plan_prefix */,
"table": "`sbtest9` `b`", #sbtest9作为被驱动表
"best_access_path": {
"considered_access_paths": [
{
"access_type": "eq_ref",
"index": "PRIMARY",
"rows": 1,
"cost": 11259.6,
"chosen": true, #选择eq_ref通过主键关联
"cause": "clustered_pk_chosen_by_heuristics"
},
{
"rows_to_scan": 98742,
"filtering_effect": [
] /* filtering_effect */,
"final_filtering_effect": 1,
"access_type": "scan",
"using_join_cache": true,
"buffers_needed": 3,
"resulting_rows": 98742,
"cost": 1.01077e+08,
"chosen": false
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 10236,
"cost_for_plan": 13317.5,
"sort_cost": 10236,
"new_cost_for_plan": 23553.5,
"chosen": true #该执行计划被选择
}
] /* rest_of_plan */
},
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`sbtest9` `b`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "PRIMARY",
"usable": false,
"chosen": false
},
{
"rows_to_scan": 98742,
"filtering_effect": [
] /* filtering_effect */,
"final_filtering_effect": 1,
"access_type": "scan",
"resulting_rows": 98742,
"cost": 11189.2,
"chosen": true,
"use_tmp_table": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 98742,
"cost_for_plan": 11189.2,
"pruned_by_heuristic": true
}
] /* considered_execution_plans */
},
连接顺序确定后attaching_conditions_to_tables尝试将where子句条件下推到连接树
{
"attaching_conditions_to_tables": {
"original_condition": "((`a`.`id` < 5000) and (`a`.`c` = `b`.`id`))",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`sbtest7` `a`",
"attached": "(`a`.`id` < 5000)"
},
{
"table": "`sbtest9` `b`",
"attached": "(`a`.`c` = `b`.`id`)"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
group by做没有太多优化工作
{
"optimizing_distinct_group_by_order_by": {
"simplifying_group_by": {
"original_clause": "`b`.`id`",
"items": [
{
"item": "`b`.`id`"
}
] /* items */,
"resulting_clause_is_simple": false,
"resulting_clause": "`b`.`id`"
} /* simplifying_group_by */
} /* optimizing_distinct_group_by_order_by */
},
优化后的条件和计划
{
"finalizing_table_conditions": [
{
"table": "`sbtest7` `a`",
"original_table_condition": "(`a`.`id` < 5000)",
"final_table_condition ": "(`a`.`id` < 5000)"
},
{
"table": "`sbtest9` `b`",
"original_table_condition": "(cast(`a`.`c` as double) = cast(`b`.`id` as double))",
"final_table_condition ": "(cast(`a`.`c` as double) = cast(`b`.`id` as double))"
}
] /* finalizing_table_conditions */
},
{
"refine_plan": [
{
"table": "`sbtest7` `a`"
},
{
"table": "`sbtest9` `b`"
}
] /* refine_plan */
},
{
"considering_tmp_tables": [
{
"adding_tmp_table_in_plan_at_position": 2,
"write_method": "continuously_update_group_row"
}
] /* considering_tmp_tables */
}
- join_execution对象
{
"join_execution": {
"select#": 1,
"steps": [
{
"temp_table_aggregate": {
"select#": 1,
"steps": [
{
"creating_tmp_table": {
"tmp_table_info": {
"in_plan_at_position": 2,
"columns": 3,
"row_length": 501,
"key_length": 4,
"unique_constraint": false,
"makes_grouped_rows": true,
"cannot_insert_duplicates": false,
"location": "TempTable"
} /* tmp_table_info */
} /* creating_tmp_table */
}
] /* steps */
} /* temp_table_aggregate */
}
] /* steps */
如果希望限制所有用户使用optimizer trace可以用以下参数启动MySQL,将所有trace截断成0字节
--maximum-optimizer-trace-max-mem-size=0 --optimizer-trace-max-mem-size=0
