




壹栈是北京流深数据科技有限公司开发的一站式数据治理开发平台,包括数据交换、数据质量、脚本开发、工作流配置、API开发、数据标签和数据可视化等模块,可以帮助企业快速进行数据建设的开发。
ClickHouse简介
ClickHouse是一个开源的,用于联机分析(OLAP)的列式数据库管理系统(DBMS),相比于行式数据库系统(如:MySQL、Postgres和MS SQL Server等)在OLAP场景下有100-1000倍的性能提升。
Clickhouse起源于俄罗斯的搜索巨头Yandex,它的快糙猛还是有点战斗民族的影子。
ClickHouse的优劣势
优势
•高性能:ClickHouse处理单查询每台服务器每秒可达数十亿行,写入速度可达50到200MB/s,快得起飞。•可伸缩性:具有从单服务器部署到拥有数千个节点的集群的线性水平可伸缩性。•可靠性:ClickHouse支持多主复制的体系结构中,不存在单点故障,在多区域配置中有效执行。•安全性:ClickHouse具有企业级安全特性和故障安全机制,保护应用程序错误和人为错误造成的数据损坏。
劣势
•没有完整的事务支持。•缺少高频率,低延迟的修改或删除已存在数据的能力(仅能用于异步的批量删除或修改数据)。•稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。•不能支持高并发的使用场景(ClickHouse采用并行处理机制,即使一个查询,也会用服务器一半的CPU去执行)。备注:这里并没有将大家经常提到的多表join作为它的劣势,首先join本身就是一个复杂度较高的程序,任何技术组件对join的处理相对单表(大宽表)来说都会慢,ClickHouse相对来说性能还是可以接受的。
性能测试
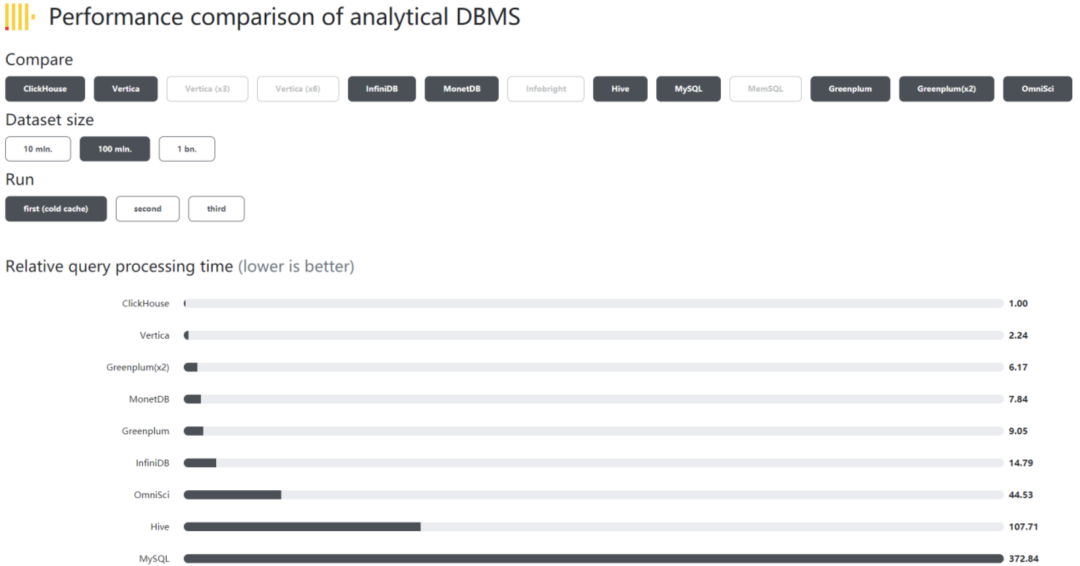
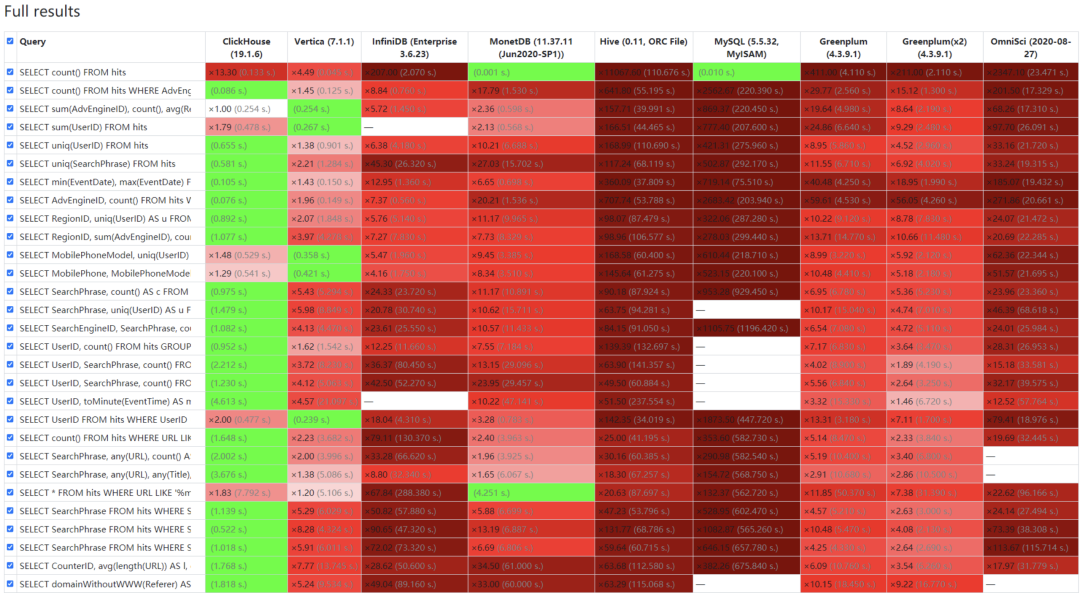
关于join性能,携程有一个测试用例可以借鉴:6000W数据关联1000W数据再关联2000W数据sum一个月间夜量返回结果:190ms;2.4亿数据关联2000W的数据group by一个月的数据大概390ms。
ClickHouse原理介绍
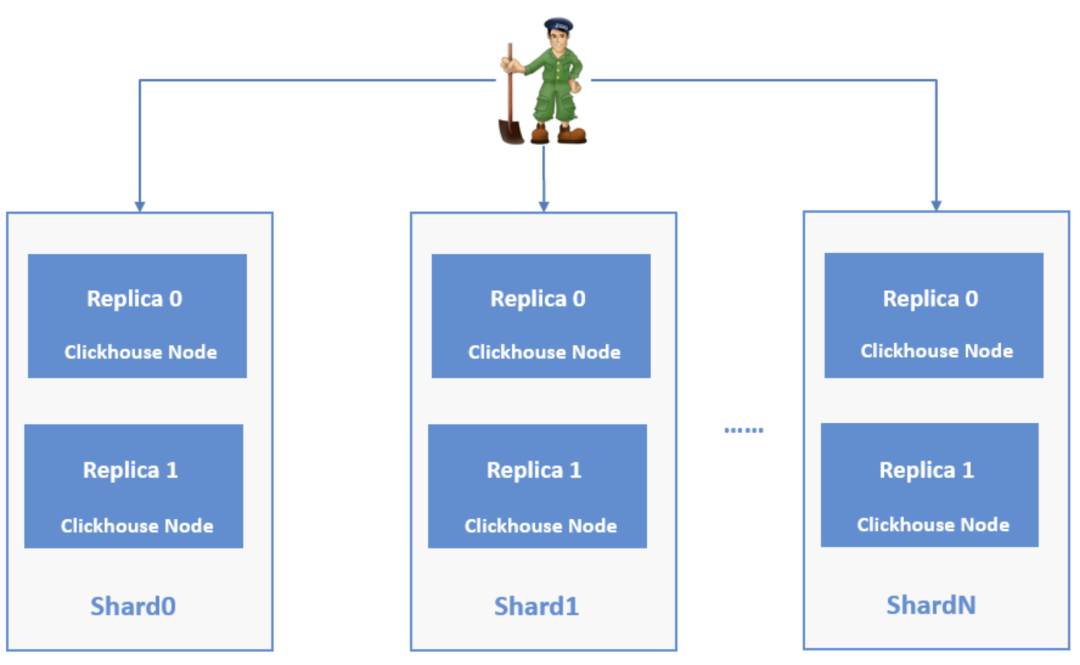
数据体量小时ClickHouse单机可获得最高的性能表现,数据体量大时clickhouse可使用分布式运行方式达到性能的线性增长。为了更好的理解ClickHouse集群的运行原理,首先需要了解一下它的两个重要角色,分片(shard)和副本(replica)。分片是分布式系统水平扩展的重要手段,可以理解为将一张数据量很大的表分割成多个部分,多台服务器分别存储其中一个部分(常用方法有随机和哈希等),从而达到存储海量数据的目的。此外,也可通过对多台服务器并行处理的方式提升整个系统的读写效率。副本是对分片的冗余备份,一个分片可以有任意多个副本,副本主要主要有两个目的:保证数据高可用和提高系统的并发查询能力。ClickHouse集群的组织结构大致如下图所示:
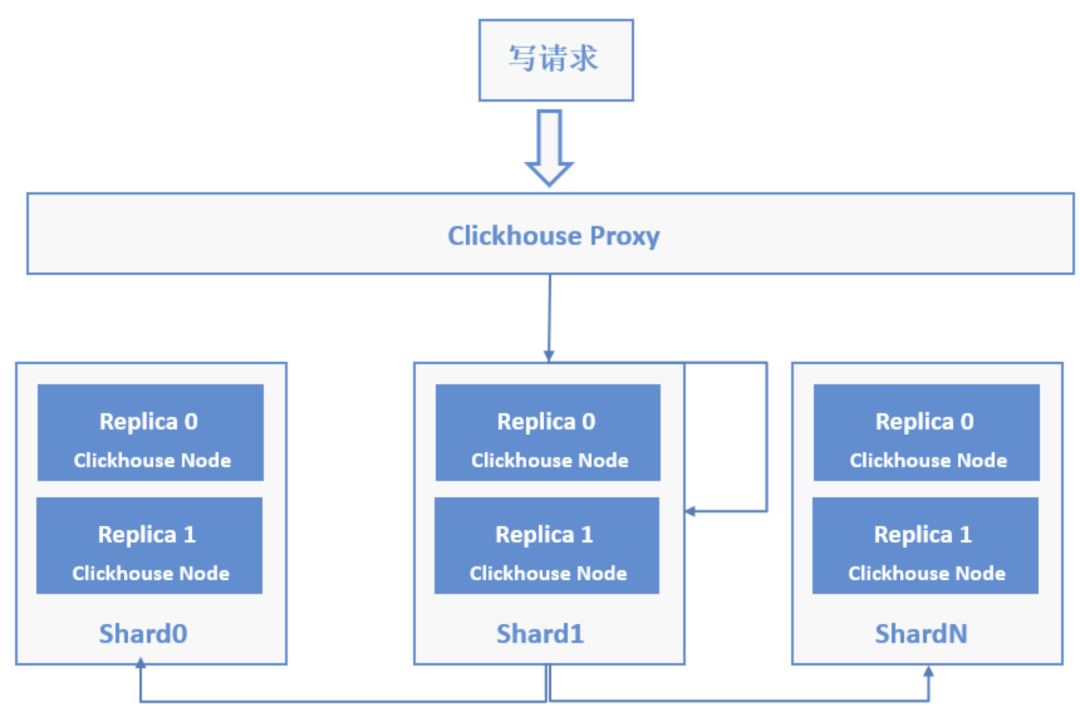
数据写入流程
对于分布式运行的方式,数据写入时ClickHouse proxy会先选择其中一个节点作为为初始节点,由该初始节点根据写入请求拆分为多个子请求转发给对应的节点并进行数据写入,集群的写入流程大概如下图所示:
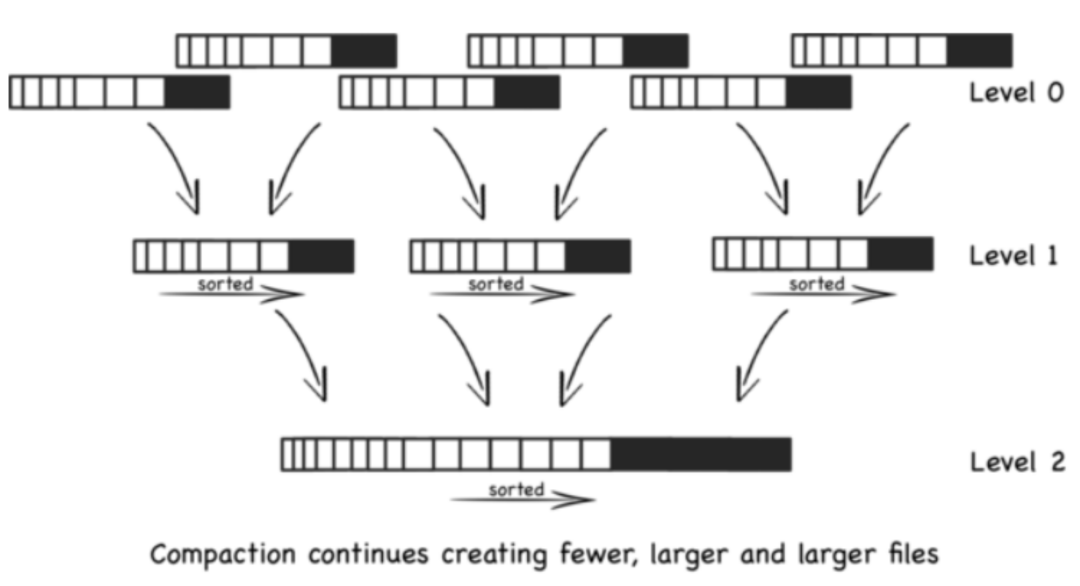
其实不仅是ClickHouse,像ElasticSearch、HBase等其他大数据组件都比较类似。数据写入时会先将数据写入到内存,在内存中对数据进行排序和索引创建,然后批量写入到磁盘文件,后期再通过定时任务将小文件逐步合并成更大的文件,从而减少磁盘IO获取更好的查询性能。整个流程大致如下图所示:
数据查询流程
数据查询和写入流程类似,首先ClickHouse proxy根据负载均衡策略从集群中选取一个初始节点并将查询请求转发到该初始节点上,由该初始节点解析并下发查询语句到所有分片节点,每个分片节点执行完查询语句后将结果返回给初始节点,初始节点进行最终的结果汇总并返回给 ClickHouse proxy,ClickHouse proxy将最终结果返回给客户端使用。
索引介绍
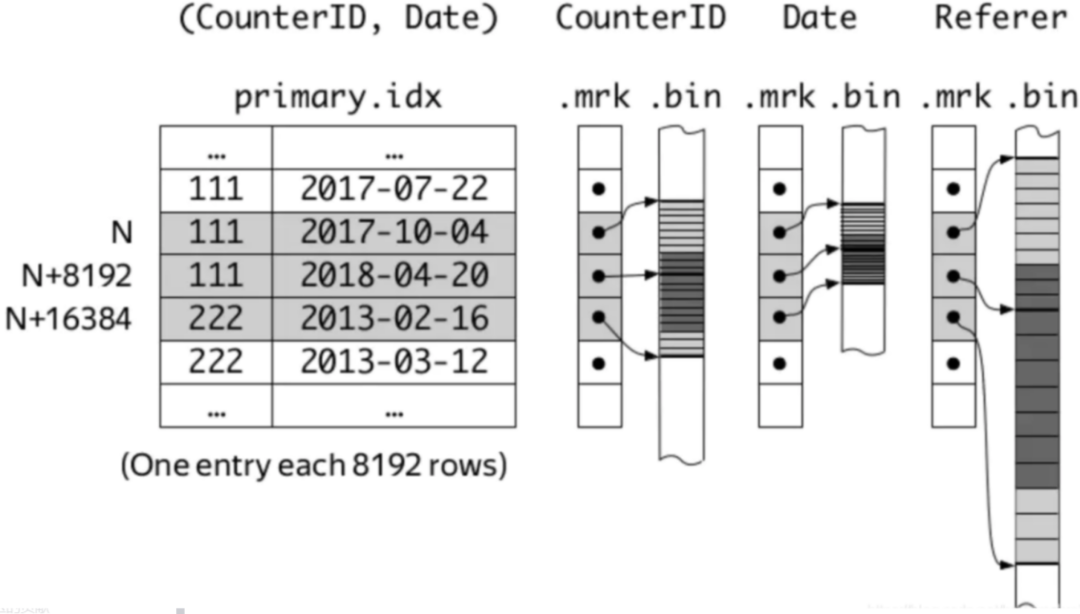
ClickHouse采用的是稀疏索引,将每列数据按照 index granularity(默认8192行)进行划分。稀疏索引的好处是条目相对稠密索引较少,能够将其加载到内存,而且对插入时建立索引的成本相对较小。ClickHouse 数据按列进行存储,每一列都有对应的 mrk 标记文件,bin 文件。mrk 文件与主键索引对齐,主要用于记录数据在 bin 文件中的偏移量信息。查询时通过对主键索引进行二分查找,定位到对应的 mrk 标记文件,进而找到对应的 bin 文件的偏移量,最终扫描得到相应的数据,避免了全表扫描,从而加速查询。索引结构大致如下图所示:
多层存储
ClickHouse支持多层存储,通过为不同类型的存储介质设置不同的优先级(volumne_priority)来实现数据存储的冷热分离,如使用SSD存储热数据、HDD存储冷数据。
多主架构 与Hadoop、Spark等分布式框架不同,ClickHouse采用的是多主架构(Multi-Master),集群中的所有节点功能相同,client端访问任意一个节点都能得到相同的效果。这种多主的架构有许多优势,集群角色相对简单,不用再区分NameNode、DataNode、Master、Worker等节点,。并且它天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。
版本介绍
ClickHouse版本迭代十分迅速,从下载页面[1]可以看到,有时一天就会发布两个stable版本、一个lts版本,让用户不知如何选择。新版本发布主要是为了解决老版本发现的bug和增加新功能。不过目前ClickHouse的stable版本发布的频率太高了,生产环境使用的话增加了不稳定性。LTS,即 Long Term Support ,每半年发布一次 LTS 大版本; 在上一个 LTS 半年后,选择当时至少被一个大客户使用过的 stable 版本作为新的 LTS 版本。所以生产环境使用的话还是建议大家使用LTS版本的包。
使用场景总结
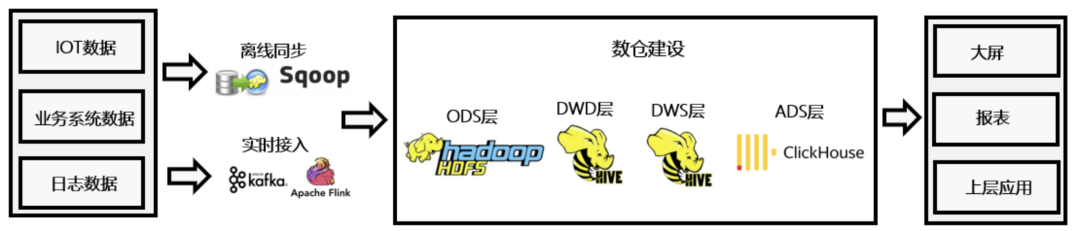
1.作为离线数仓的上层引擎,数据从Hive表中批量写入ClickHouse,由ClickHouse对应用提供OLAP场景服务。
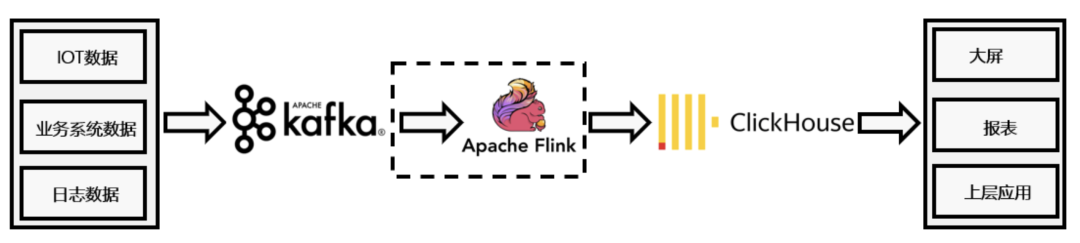
2.配合flink实现实时数仓,提供实时的数据写入和在线交互式查询服务。另外,ClickHouse自身也提供了Kafka表引擎,可直接订阅消费Kafka中数据,对于简单场景甚至可以不再使用flink做流式接入。
目前大数据处理分析仍是一项复杂繁琐的工作,一个完整的技术方案可能需要引入包括离线计算(Hive、Spark、Impala)、流式计算(SparkStreaming/Spark Structured Streaming、Flink)、全文检索(ElasticSearch、Solr)等多种技术组件,与此同时部署运维的难度也会随着增加。针对目前的问题,可参考的主要有两个方向:一是通过中间件技术,屏蔽底层复杂多样的存储计算引擎,使得开发人员通过写SQL就可完成指标的开发等数据分析工作。另一种是类似ClickHouse这样,在一定数量级(PB级)下实现数据处理的批流合一,减少系统的技术组件从而降低系统的复杂度。
References
[1]
Clickhouse 版本: https://github.com/ClickHouse/ClickHouse/releases
[2]
Background music:Endless Summer You By Roa - (No Copyright Music)

