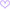撰文/Iris帆
导读
接着上期的数据分析究竟是分析什么?本期将由一个小案例,从代码和分析流程出发,介绍数据分析的思路,其实也是我最近做数据分析的总结。内容依旧不复杂,运用的是基本的数分知识。题外话:上期谈到我面试的一家英国媒体公司市场研究分析职位,写上期的时候还在等结果,刚得到反馈是「未拿到offer」。很可惜,也有些低落,但是学习依旧要坚持,还在等另一份工作的反馈。
Python数据分析三大基本流程:数据概况分析、数据整理&清理、探索性分析&可视化
数据分析思维总结、复盘
拿到数据之后,首要任务是对数据进行整体认知——包括有哪些数据集,各数据集都有什么变量,变量之间都有什么关系等等。具体地,用df.head()
和df.info()
搭配使用,就可以查看数据集头5行的内容和数据集的整体结构(变量类型,样本行列数目等)。
为什么认识数据很重要呢?因为数据分析可以说是挖掘数据内部,变量之间关系的技能。要做到合格的数据分析,得先认清各变量的含义,甚至通过已知变量挖掘出新的变量。
先举几个简单的例子,一个”日期时间“变量,就可以提取出”年、月、周、时、分、秒“6个变量;又比如已知数据集中有”销售额“和”成本“,就可以通过销售额-成本 = 利润
来计算出”利润"这个新变量。前两个例子都是很直白简单的,复杂了说,有些变量可能包含的是字符串文本,如果字符串具有相似的格式,那么我们完全可以将有用信息提取出来,单独形成新的一列,也就是新的变量。
下面通过某网购平台案例来解释基本的数据分析思维流程(只包含重要代码部分),假定该网购平台希望了解用户复购情况。
通过对背景的理解,可以初步知道我们分析的目的是——分析具有哪些特征的用户有更高的复购率?
首先来认识我们的数据。「认识数据」首先是一个观察的过程,这一步,我们需要用直接的描述性的语言,记录下数据集的特点。
比如数据集df_user_info
是用户基本信息,包含user_id
(用户id)、age_range
(用户年龄)、gender
(用户性别)。通过df_user_info.info()
(如图1)我们可以看到该数据集一共有424170行样本,其中3个变量的数据类型都是数值型变量,age_range和gender包含缺失值。
小提醒:性别中女性由数字0表示,男性由数字1表示,2
和NULL
都表示未知;年龄也是由数字表示,用户年龄段 1
为<18,2
为[18,24],3
为[25,29],4
为[30,34],5
为[35,39],6
为[40,49],7
和8
为≥50,0
和NULL
表示未知。
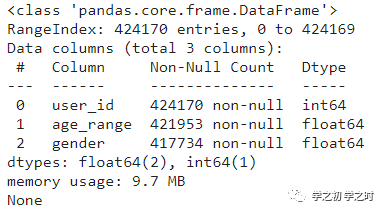
图1
「样本数」、「数据类型」、「缺失值」就是我们使用df.info()
的关注点,也是需要我们记录下的数据集特点。其中,「缺失值」是我们需要重点处理的,通常的方法是直接删除包含缺失值的行,或者加以填充(因情况而定)。
查看了数据结构,可能会产生这样的疑问:“user_id有424170个,是否就是有这么多的用户呢?会不会有重复行?或者会不会相同的用户留了两份信息?”
我们可以通过sum(df_user_info.duplicated())
得到有多少个重复行。也可以用df_user_info['user_id'].nunique()
来确定有多少个唯一用户id,来判断与数据集行数是否一致,以此判断是否有重复值的情况。
另一个数据集是df_train_data
,包含user_id
(用户id)和label
(是否复购,0代表否,1代表是)。
最后一个数据集df_log_data
是用户在平台的交互信息,包含user_id
(用户id)、item_id
(商品id)、cat_id
(品类id)、seller_id
(商家id)、brand_id
(品牌id)、date
(用户与商品交互的日期)、action_type(用户行为类型)。
这里需要知道的就是action_type是类别型变量,于是自然地就会想知道action_type包含哪些类型?各类型的占比又是多少?这个时候我们可以使用df_log_data['action_type'].value_counts()
来看各个类型分别有多少数目,也可以使用df_log_data['action_type'].value_counts(1)
来看各类型的占比。
小提醒:action_type包含0
(单击)、1
(添加购物车)、2
(购买)和3
(添加到收藏夹)4个行为。下一个错别字
认识了数据之后,我们需要针对缺失值进行处理,也就是我们常说的——数据清理。
通常情况,如果缺失值占比小,那么直接删除;如果缺失值占比大,那就要进行多方考虑,比如“缺失的这部分信息可以从哪些地方获取?如果无法获取如何进行填充?等等”。
先来查看缺失值占比。前面有提到age_range
这个变量,7
和8
均为≥50,0
和NULL
都表示未知,也就是缺失值,gender
变量,2
和NULL
都表示未知。所以,我们需要先进行「数据一致化」,具体做法是:
将
age_range
中的8
全部替换为7将
age_range
中的0
全部替换为NULL
值将
gender
中的2全部替换为NULL
值
代码如下:
#将age_range中的0替换为NA值(将0和NULL统一)df_user_info['age_range'] = df_user_info['age_range'].replace(0,np.NaN)#将age_range中的8都统一为7,因为7和8都表示一个年龄段 ">=50"df_user_info['age_range'] = df_user_info['age_range'].replace(8,7)#将gender中的20替换为NA值(将2和NULL统一)df_user_info['gender'] = df_user_info['gender'].replace(2,np.NaN)
一致化处理完后,我们就可以来查看缺失值的占比了,代码如下:
#gender缺失值占比df_user_info['gender'].isna().sum()/df_user_info.shape[0]#age_range缺失值占比df_user_info['age_range'].isna().sum()/df_user_info.shape[0]
结果中如果缺失值占比小,比如少于5%,可以使用df.dropna()
直接删除包含缺失值的行;如果缺失值比例大,且无法获取缺失值这部分的真实数据,可以考虑以“0,平均值,中位数”进行填充。
以本案例为例,代码如下:
#删除gender中包含缺失值的行df_user_info.dropna(subset = [2])#以所有年龄段加起来的平均值填充age_range中的缺失值df_user_info['age_range'].fillna(df_user_info.age_range.mean())
数据清理完之后,我们再次回到本案例的目的——分析具有哪些特征的用户有更高的复购率?回顾刚才的分析,我们只简单分析了用户的年龄和性别,也就是df_user_info
这一个数据集的特征,那么df_log_data
又该如何分析呢?这里就需要我们进一步思考「用户特征」的含义。
年龄和性别很好理解,但要是与用户购买行为挂钩,就不得不与用户action_type联系起来,用户习惯购买的时间,以及用户喜欢的品牌、店铺和商品。综合来看,可以考虑以下几点:
用户的性别:男性和女性,谁具有更高复购率?
用户的年龄:哪个年龄段具有更高复购率?
什么日期用户有更高复购率?
什么样的交互行为体现更高复构率?
为了解答上面几个要点,我们要对原本的3个数据集进行整理,从而生成出一个新的数据集。
首先我们已经知道3个数据集都含有user_id,所以可以通过user_id将3个数据集聚合起来。其次,我们要把每个用户在不同action_type交互类型的次数,以及交互行为总次数分离出单独的列,即一共"购买"(2)了多少次,"加入购物车"(1)多少次等等。
代码如下:
#针对user_log_data统计各交互类型次数#行转列user_log_tmp= user_log_data.groupby(['user_id','seller_id'])['action_type'].value_counts().unstack()#添加求和列user_log_tmp['sum']= user_log_tmp.sum(axis= 1)#在所有列名前加一个“action"#reset_index()重置索引user_log_tmp= user_log_tmp.rename(columns=lambda x:f'action_{x}').reset_index()
如果我们用user_log_tmp.head()来查看新建立的数据集的前5行,可以得到类似以下结果(如图2):
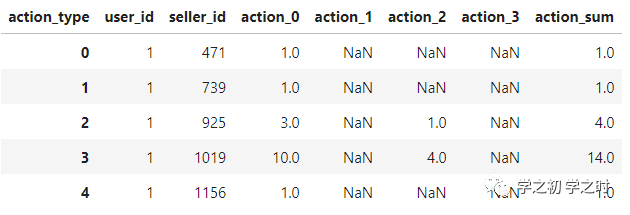
图2
这里的NaN
是指没有进行任何交互行为,所以可以用0
来进行填充user_log_tmp = user_log_tmp.fillna(0)
。
最后,就是将各数据集合并为新的数据集df_final
,代码如下:
#将df_train_data, df_user_info和user_log_tmp合并df_final= df_train_data.merge(df_user_info,on= "user_id", how= "left")df_final = df_final.merge(user_log_tmp, on= "user_id", how = 'left' )
我们将用新数据集df_final
进行可视化探索,可视化部分在数据分析中也是最直观表达结果的部分。
联系刚才探讨的「用户特征」,可视化部分就很清晰了,那么下面就一个例子来解释可视化思维。
首先我们依旧可以用统计的形式发现一些数据上的规律,比如:
age_gender = train_data_with_user.groupby(['age_range','gender'])['label'].mean().reset_index()age_gender
上面这个代码做的事情是:按照年龄段和性别分类,平均复购率分别是多少。得到的结果如下(如图3):
图3
统计表的形式并不能有效地帮助我们理解数据,所以我们采用可视化的直观表达,,代码如下:
sns.barplot(x= 'age_range', y= 'label',hue= 'gender', data= age_gender)plt.axhline(y=df_final['label'].mean(),c='red')#红线为大盘的平均复购率
可视化结果如下(如图4):
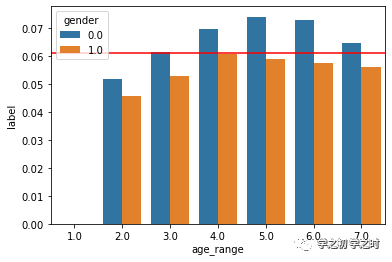
图4
通过图4,我们很容易发现以下特征(注:0为女性,1为男性):
无论什么年龄段,女性的复购率都要比男性高;
年龄段在4~7(≥ 30岁)的女性用户复购率均高于大盘。
这里只是举出针对复购率与性别和年龄的关系可视化图,其实交互类型上,理论也是一样的。首先将df_final
数据集按照不同action_type
分类,平均复购率分别是多少。
最后总结一下上述数据分析思路:
因为关注点是用户复购,朝着这个思路,可以联想到一个问题是:什么样的用户更容易产生“复购”?自然地,就会与用户的性别、年龄段和与商铺等交互信息特征联系起来。上面的分析未包括更细节的与商品和商品类别本身的交互行为联系,但在现实工作中是会深入进行探讨的(也是能力上的区分)。
总而言之,数据概况、数据处理&清理、探索性分析&可视化,这3大块(理解含义即可,可自行分块,更名)的分析步骤是数据数据分析中的基础部分。初级数据分析师往往只要求这些部分,而不对特征工程、建模和模型评估等做出要求。
在进行初级数据分析时,一定要关注核心目的。过程中间可以进行发散,对感兴趣的部分进行分析和可视化,同时要注意分析的内容是否和目的一致。