




背景介绍:
某地区腾讯云平台系统(基于OpenStack开发的TStack平台),其中一台物理服务器(计算节点)下架维护,需要将其承载的云服务器迁移到其他物理服务器,为保证业务正常运行,因此采用热迁移的方式进行操作。按照变更流程,在基础云平台(dashboard)上,可以直接对实例指定目标物理服务器进行热迁移,等待迁移完成即可,本文主要介绍若一直卡在“正在迁移”步骤的处理方法。
正文:
在热迁移前需要确认一下几点
1.源物理服务器与目标物理服务器CPU指令集要完全相同。
2.目标物理服务器需要有足够的内存。
3.目标物理服务器nova-compute service服务是否正常运行。
若不满足以上几点,那么将迁移失败。
首先在基础云平台操作热迁移实例,选择新主机,点击“实例热迁移”(无需选择磁盘超量和块迁移),随后一直卡在“正在迁移”这个状态。
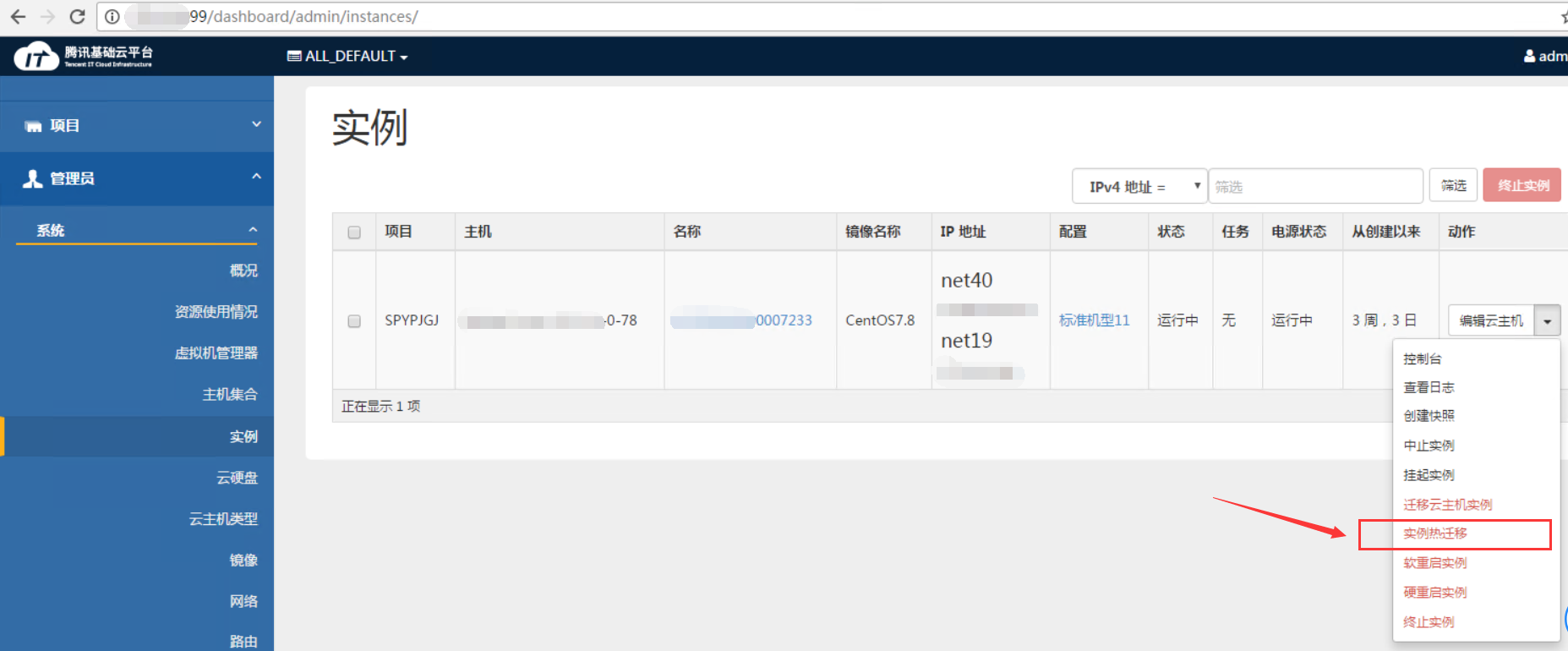
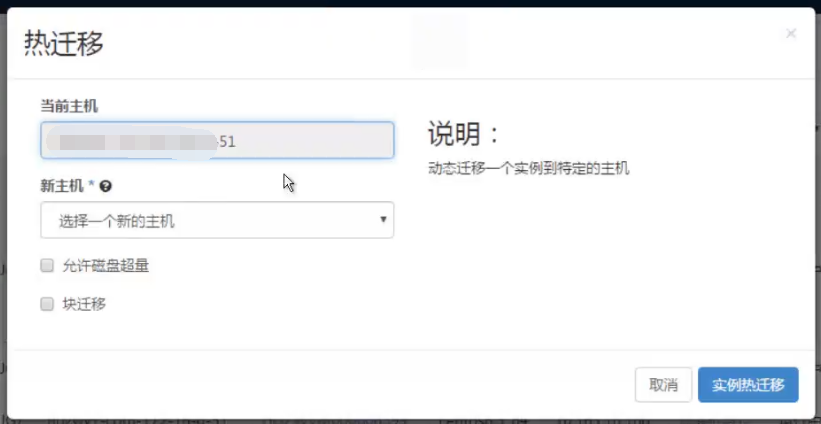

这时需要到原物理服务器查看nova日志,热迁移时日志信息30秒显示一次内存剩余迁移进度
tail -30f /var/log/nova/nova-compute.log
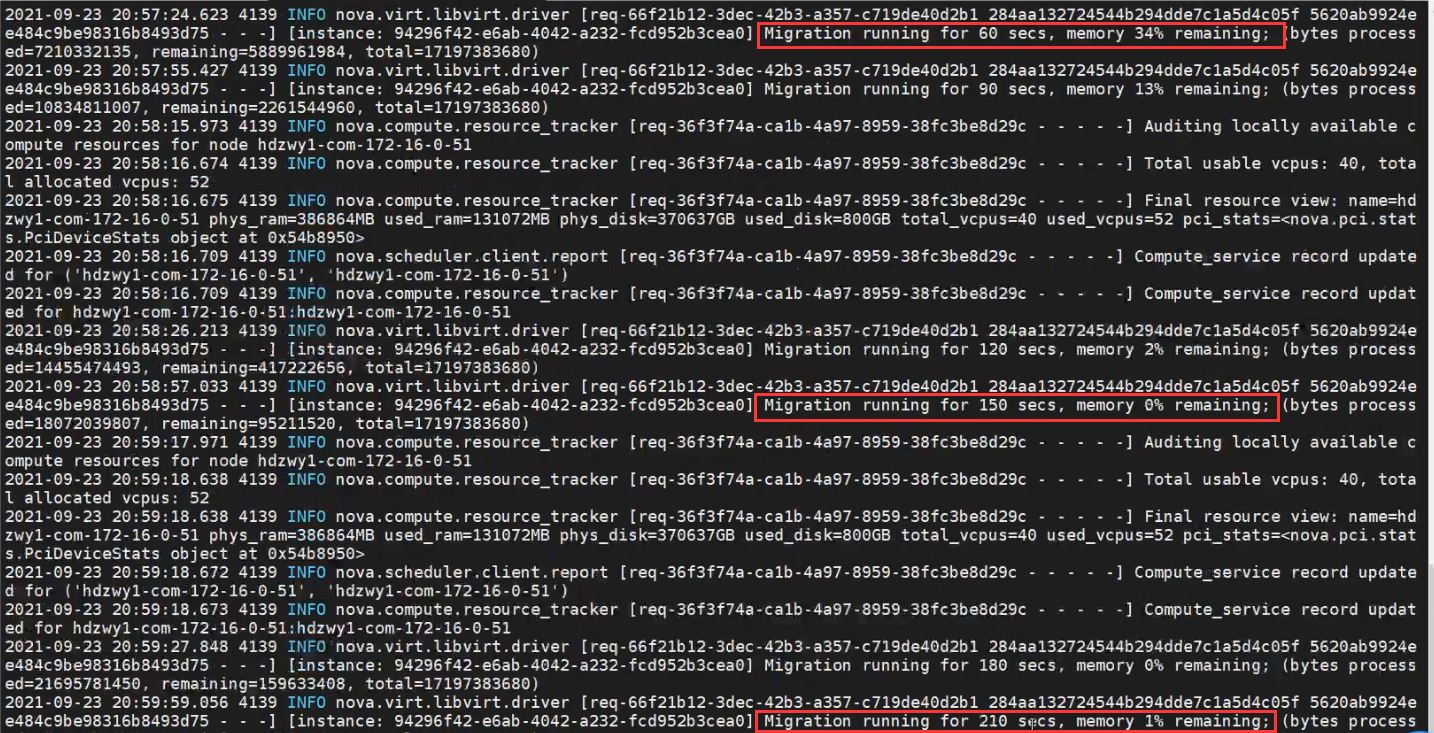
通过日志可以发现,内存剩余迁移进度到0%后又新增到1%。这是因为实例热迁移是在内存中完成的操作,该实例还正在使用(业务运行),迁移的进度跟不上数据写入的速度,最终导致卡在“正在迁移”。
处理方法:
1.确认instance_name
Instance_name获取方式:nova
show

2.确认该实例运行在源节点:
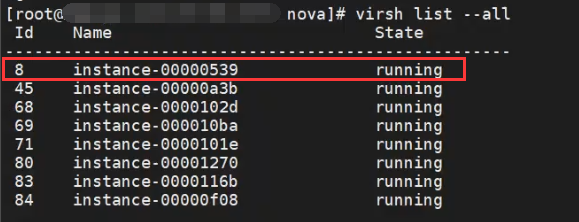
3.在源物理服务器通过instance_name查看迁移进度
watch -n 1 virsh domjobinfo instance-00000539(或者使用id,watch -n 1 virsh domjobinfo 8)
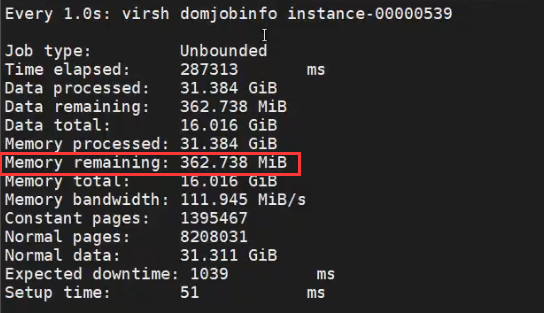
4.另外打开一个终端,在Memory remaining值最小时,暂停虚机。(注意:为避免内存数据丢失,以上操作只能在最后一刻虚机内存 remaining 最小值的时候操作。)

5.确认实例已迁移到目标物理服务器,基础云控制台(dashboard)状态正常
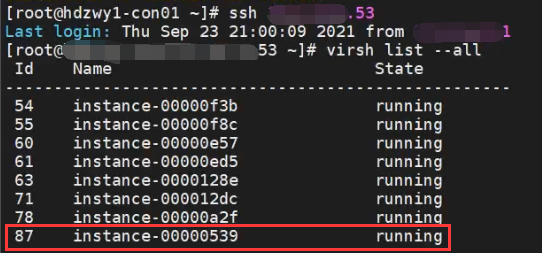
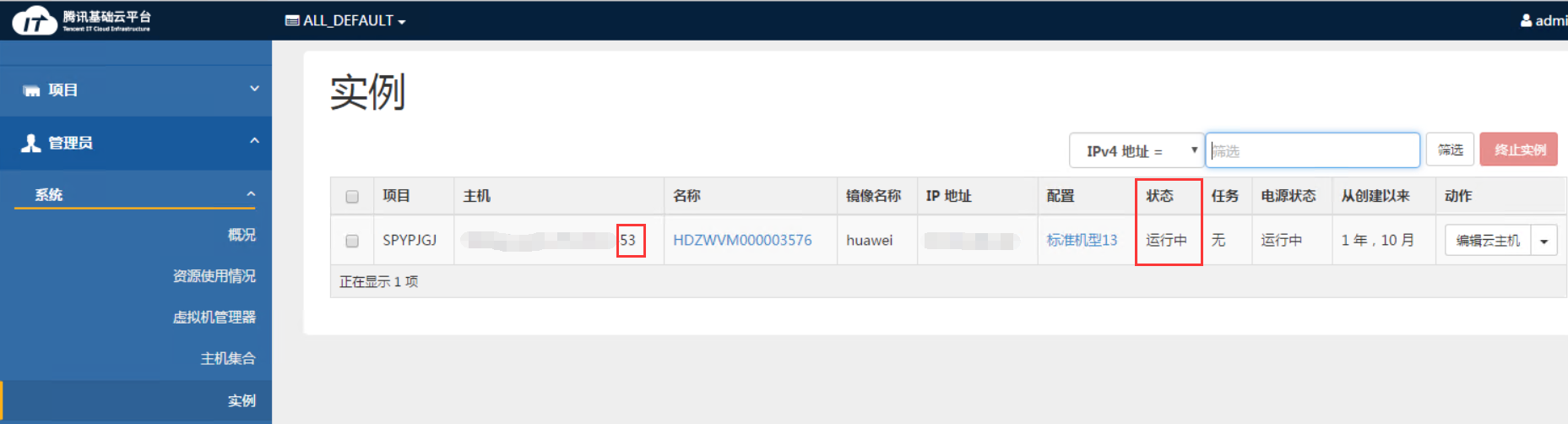
注意:若步骤5的1图确认无误,但是在基础云控制台仍然卡在“正在迁移”,则为请求超时,需要手动更新状态。
1.执行如下指令将虚拟机重置为运行中的状态
nova reset-state
2. 登录基础云任意一台控制节点,访问 mysql 数据,修改 nova.instances 库的 host 和 node 字段值为新宿主机主机名,<new_compute_node>
替换为新宿主机主机名
select * from nova.instances where uuid='<instance_uuid>'\Gupdate nova.instances set node='<new_compute_node>' where uuid='<instance_uuid>';update nova.instances set host='<new_compute_node>' where uuid='<instance_uuid>';
3.通过虚拟机 ip 查看虚拟机 ip 的 port id,以下用 <port_id> 表示
neutron port-list | grep
4. 登录基础云任意一台控制节点,访问 mysql 数据库,修改 neutron.ml2_port_bindings 库的 host字段值为新宿主机主机名,<new_compute_node> 替换为新宿主机主机名
select * from neutron.ml2_port_bindings where port_id='<port_id>'\Gupdate neutron.ml2_port_bindings set host='<new_compute_node>' where port_id='<port_id>';
总结:
热迁移不能完成,一直卡在 migration的根本原因是迁移速度一直追不上写入的速度,需要手动介入处理,但是在操作过程中有可能会造成内存中的数据丢失,因此在实例热迁移时应该尽量选择业务低峰期操作,避免内存数据丢失。
