




“ 文本介绍了Spark sql的常用参数,以及如何通过这些参数来控制作业的并行度、资源调度、shuffle、执行计划等来提升任务的运行效率,优化存储空间和资源利用率,其中重点关注了资源、数据倾斜、join优化方案。并介绍了Spark 3.0的新特性Adaptive Query Execution。最后通过4个实际的优化案例来进一步介绍常用的优化方法。”
01
—
常用参数和优化方法
1. 资源调优
spark 的资源分配粒度最小是container,即一个executor带的cpu和内存资源。资源的申请和移除都是通过executor 进程的增加和减少达成
1.1 Executor
参数 | 描述 |
spark.executor.cores | 每个executor的CPU核数 |
spark.vcore.boost.ratio | vcore,虚拟核数。提高cpu利用率 |
1.1.1 静态分配
参数 | 描述 |
spark.executor.instances | 静态资源下executor数 |
1.1.2 动态分配
参数 | 描述 |
spark.dynamicAllocation.enabled | 动态资源开关 |
spark.dynamicAllocation.initialExecutor | 初始化时启用的executor的个数 |
spark.dynamicAllocation.minExecutors | 最少分配的executor的个数 |
spark.dynamicAllocation.maxExecutors | 最大可分配的executor的个数 |
spark.dynamicAllocation.executorIdleTimeout | executor的空闲回收时间 |
spark.dynamicAllocation.schedulerBacklogTimeout | 启动新executor,未分配的task等待分配的时间 |
1.1.3 Task 数量
参数 | 描述 |
spark.sql.files.maxPartitionBytes | 读取可切分文件时,每个Partition Split的最大值 |
spark.sql.shuffle.partitions | Reduce 后partition 数量 |
区分:application, job,stage, task
a. Application:初始化一个 SparkContext 即生成一个 Application
b. Job:一个 Action 算子就会生成一个 Job
c. Stage: 遇到一个宽依赖划分一个 Stage。
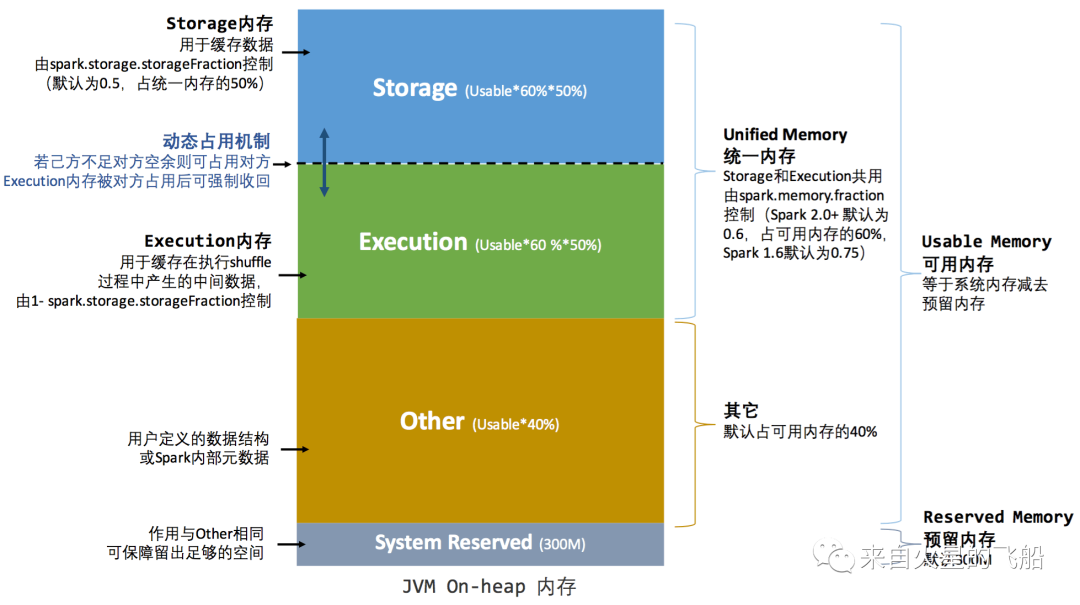
1.2 统一内存管理
参数 | 描述 |
spark.executor.memory | Executor 堆内内存 |
spark.storage.storageFraction | Storage内存在堆内内存占比 |
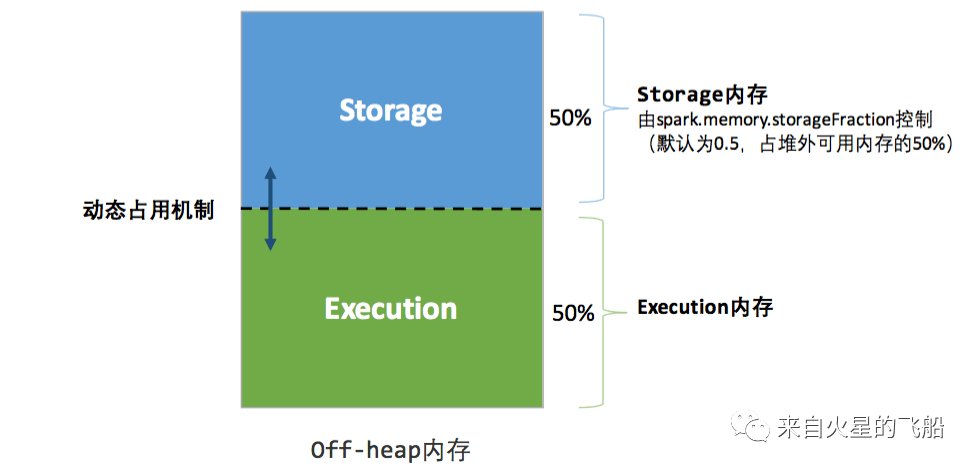
spark.memory.offHeap.enabled | 是否开启堆外内存 |
spark.memory.offHeap.size | 堆外内存大小 |
1.2.1 堆内内存
a. 存储内存:缓存 RDD 和 Broadcast变量
b. 执行内存:Shuffle 数据
c. Other:用户定义的数据结构
d. System Reserved: 保留内存防止OOM,(非序列化对象周期采样估算,JVM回收延迟)
动态内存管理

1.2.2 堆外内存
2. Adaptive Query Execution
a. 执行计划可动态调整
b. 调整的依据是中间结果的精确统计信息
参数 | 描述 |
spark.sql.adaptive.enabled | Adaptive execution开关 |
2.1 Reduce task 数量控制
参数 | 描述 |
spark.sql.adaptive.minNumPostShufflePartitions | reduce个数区间最小值,为了防止分区数过小 |
spark.sql.adaptive.maxNumPostShufflePartitions | reduce个数区间最大值,同时也是shuffle分区数的初始值 |
spark.sql.adaptive.shuffle.targetPostShuffleInputSize | 动态合并reducer的partition。map端多个partition 合并后数据阈值,小于阈值会合并 |
2.2 Map join 触发限制
参数 | 描述 |
spark.sql.adaptive.join.enabled | 自动转换sortMergeJoin到broadcast join 开关 |
spark.sql.adaptiveBroadcastJoinThreshold | 将sortMergeJoin转换成broadcast join 阈值 |
2.3 数据倾斜优化
参数 | 描述 |
spark.sql.adaptive.skewedJoin.enabled | 倾斜处理开关 |
spark.sql.adaptive.skewedPartitionFactor | 倾斜的partition/同一stage的中位数 不能小于该值 |
spark.sql.adaptive.skewedPartitionSizeThreshold | 倾斜的partition大小不能小于该值 |
spark.sql.adaptive.skewedPartitionRowCountThreshold | 倾斜的partition条数不能小于该值 |
spark.sql.adaptive.skewedPartitionMaxSplits | 被判定为数据倾斜后最多会被拆分成的份数 |
3. Join调优
3.1 多种join的差别
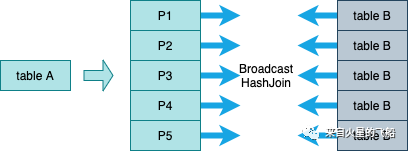
3.1.1 Broadcast Join
对广播的表大小有比较大的限制。见 Map join 触发限制 对driver和executor的内存、带宽等资源增加压力
3.1.2 Shuffle Hash Join
spark.sql.join.preferSortMergeJoin = false(默认是true)
每个分区的平均大小不超过BroadcastJoinThreshold限制
大表大小 > 3*小表大小

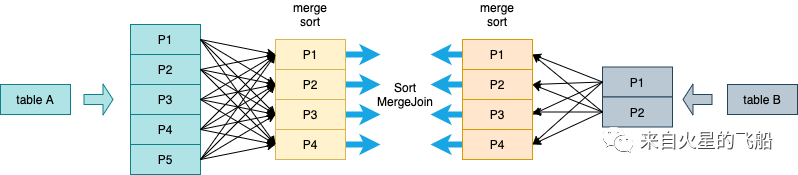
3.1.3 Sort Merge Join
3.1.4 Bucket join

a. 根据bucket key(或超集)进行 join、group by, 不会进行shuffle操作
b. 可兼容历史数据,根据修改时间的后一天作为bucket起始分区,之前的分区还是被视为非bucket
c. 可修改分桶数量
d. 提升压缩比
e. 提升过滤速度
a. 两张表必须分bucket
b. 两张表的bucket是倍数关系
c. Bucket key要与join\group key相等或者是子集
d. 不支持full join
e. 在写入bucket表的执行计划的最后一个节点按照分桶key join/group by 才能消除shuffle操作
3.2 优化场景
3.2.1 大表join小表
3.2.2 大表join大表
a. 提前过滤:
i. 过滤掉不需要参与join的数据。
ii. 如果A表left join B表。主表A只有少量的key在B表中,可以提前把A表的key聚合,广播到B表。预先过滤B表无用数据。
b. 采用Bucket join
4. 数据倾斜调优
表现
解决方案
a. spark 3.0 可以开启AE的数据倾斜优化
b. 判断这些key是不是可以提前过滤掉
c. 小表改成map join去除shuffle
d. 增加reduce并行度,减少shuffle后每个task的数据量,适用于有较多 key 对应的数据量都比较大
的情况,一定情况下可以缓解数据倾斜,但是浪费资源
e. 将聚合分为两步。(1) 将key加前缀打散后分散到多个task上做聚合 (2) 去除随机值聚合
f. 将数据拆成两份,找到倾斜的key,对这些key单独加盐按照4处理之后,在union其他非倾斜数据的聚合结果
5. 其他调优
5.1 本地化调优
5.1.1 本地化级别
名称 | 解析 |
PROCESS_LOCAL | 进程本地化,task 和数据在同一个Executor 中 |
NODE_LOCAL | 节点本地化,task 和数据在同一个节点中,但是 task 和数据不在同一个 Executor中,数据需要在进程间进行传输。 |
RACK_LOCAL | 机架本地化,task 和数据在同一个机架的两个节点上,数据需要通过网络在节点之间进行传输。 |
NO_PREF | 对于 task 来说,从哪里获取都一样,没有好坏之分。 |
ANY | task 和数据可以在集群的任何地方,而且不在一个机架中,性能最差。 |
参数 | 描述 |
spark.locality.wait | 本地化等待时长 |
5.2 Shuffle调优
参数 | 描述 |
spark.shuffle.io.maxRetries | reduce 端拉取数据重试次数 |
spark.shuffle.io.retryWait | reduce 端拉取数据时间间隔 |
spark.shuffle.hdfs.enabled | map 端开启双写 |
spark.shuffle.hdfs.replication | 写hdfs的副本数 |
spark.shuffle.file.buffer | map 端拉取数据缓冲区大小 |
spark.reducer.maxSizeInFlight | reduce 端拉取数据缓冲区大小 |
a. GC导致shuffle 文件拉取失败
b. 长任务,shuffle量大的任务,FetchFailedException 报错
c. Map 端处理大量数据
d. Reduce 端处理大量数据
02
—
实际优化案例
1. 大文件优化案例
实验结果:
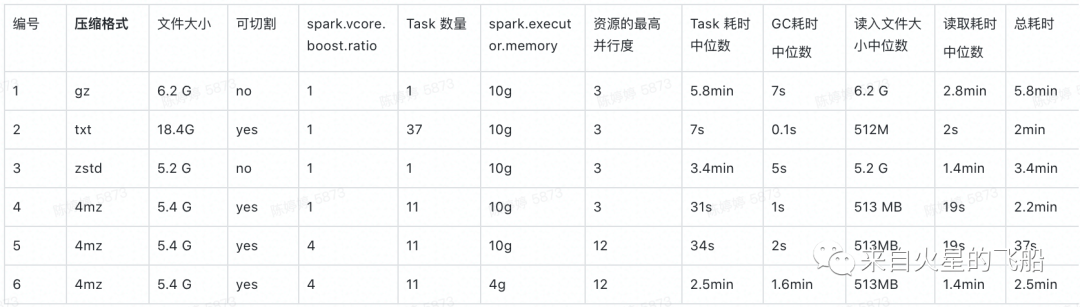
总结:
a. 采取合适的文件压缩格式,可提高任务执行效率同时减少存储压力。
b. 在内存充足的情况下可以适当调节vcore
c. 调节vcore如果内存资源不够,会导致GC压力过大,反而执行效率会退化
2. Bucket join 优化案例
限定条件:
实验结果:
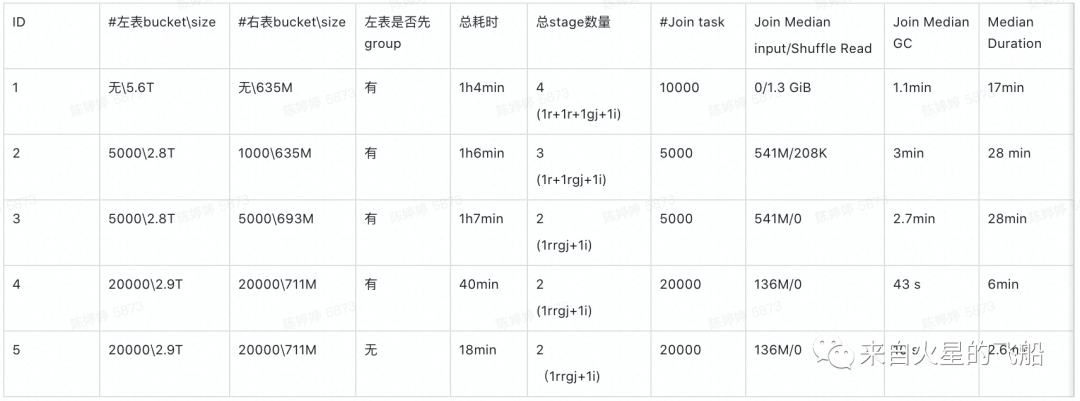
总结:
a. 对大表分bucket可以进一步提高压缩率,但是对小表分bucket由于会增加大量小文件,未最大化压缩收益,反而可能会减低压缩率
b. 要设置合理的bucket数量,提高任务运行的并行度
c. 在开始调优之前,先分析sql是否可以优化。优化sql带来的性能提升效率可能大于调参优化
3 通过增加资源提高运行效率案例

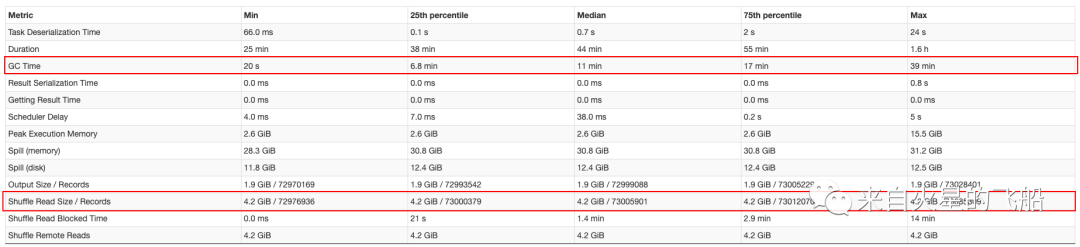
优化结果:运行耗时减少了近65%


总结:
a. 合理的调节Reduce 的partition数量可以提升运行效率
b. 在资源满足要求以及任务数多的情况下可以增加cpu资源来提升运行并行度
4 减少资源浪费率案例
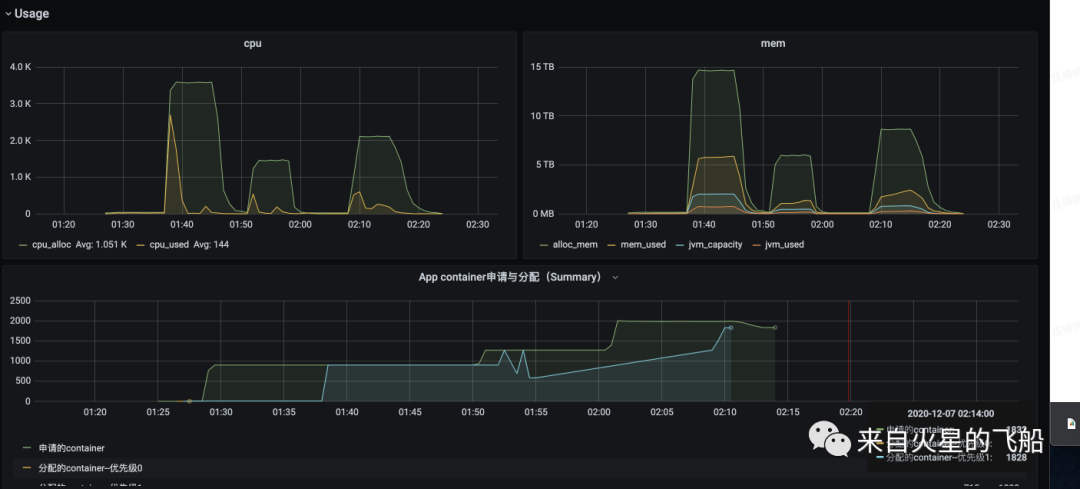
优化结果:总cpu浪费下降3倍
优化后参数和运行状态
spark.shuffle.hdfs.enabled=true;
spark.executor.memory=8g;
spark.dynamicAllocation.executorIdleTimeout=30;
spark.dynamicAllocation.maxExecutors=250;
spark.sql.adaptive.maxNumPostShufflePartitions=500;
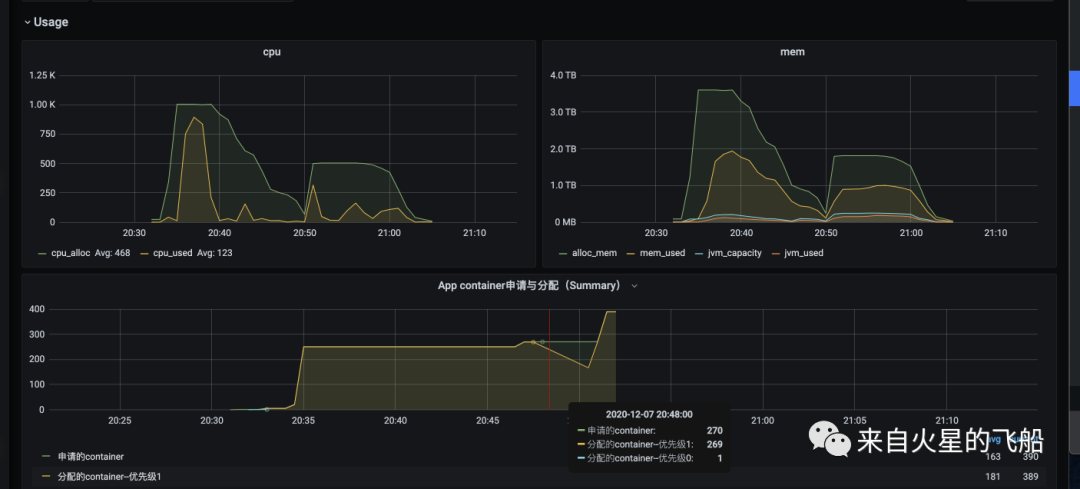
总结:
a. Partition 的数据不是越多越好,太多的小文件也会影响运行效率并且浪费资源
b. 可以适当减少executor空闲回收时间,加快资源释放
c. 可以通过限制maxExecutors数量来控制最高并行度,减少无效的executor申请,提高资源使用率
