





泰迪学院
公众号ID:taidixueyuan
还未阅读前三篇的小可爱,在这里可以直接跳转
构建智能推荐模型
推荐系统(Recommender System)是解决信息过载的有效手段,也是电子商务服务提供商提供个性化服务重要的信息工具。在实际构造推荐系统时,并不是采用单一的某种推荐方法进行推荐。大部分推荐系统都结合多种推荐方法将推荐结果进行组合,最后得出最优的推荐结果。在组合推荐结果时,可以采用串行或者并行的方法。
1. 基于物品的协同过滤算法的基本概念
本案例基于物品的协同过滤系统的一般处理过程,分析用户与物品的数据集,通过用户对物品的浏览与否(喜好)找到相似的物品,然后根据用户的历史喜好,推荐相似的物品给目标用户。图1是基于物品的协同过滤推荐系统图,从图中可知用户1喜欢物品A和物品C,用户2喜欢物品A、物品B和物品C,用户3喜欢物品A。从这些用户的历史喜好可以分析出物品A和物品C是比较类似的,喜欢物品A的人都喜欢物品C,基于这个数据可以推断用户3很有可能也喜欢物品C,所以系统会将物品C推荐给用户3。
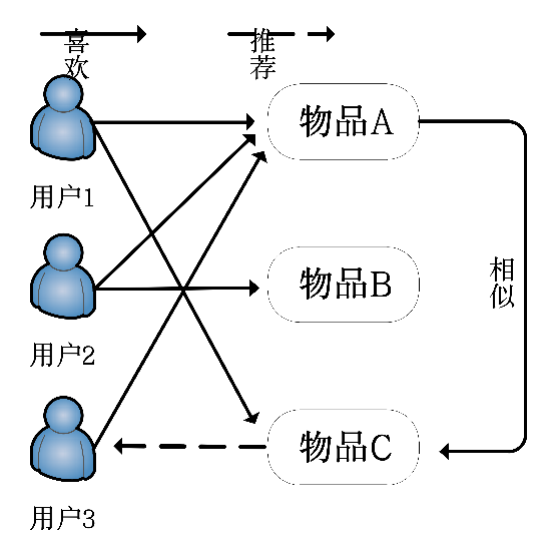
图1 基于物品的推荐系统原理图
根据协同过滤的处理过程可知,基于物品的协同过滤算法(简称ItemCF算法)主要分为2个步骤。
(1)计算物品之间的相似度。
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
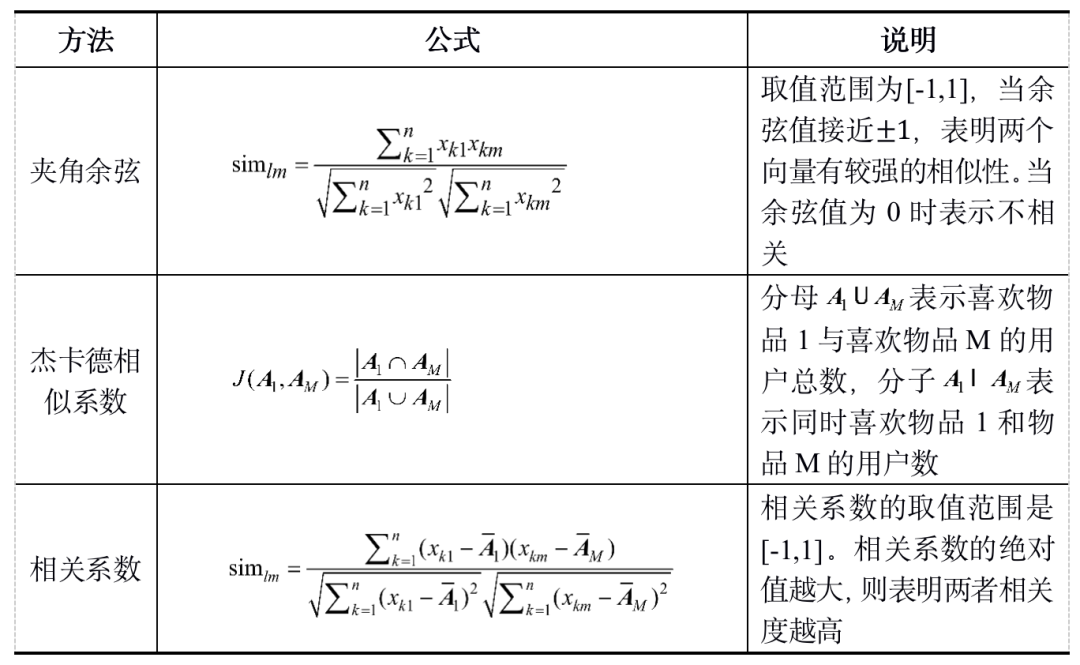
其中关于物品相似度计算的方法有夹角余弦、杰卡德(Jaccard)相似系数和相关系数等。
将用户对某一个物品的喜好或者评分作为一个向量,例如所有用户对物品1的评分或者喜好程度表示为,所有用户对物品M的评分或者喜好程度表示为,其中m为物品,n为用户数。采用上述几种方法计算两个物品之间的相似度,其计算公式如表 119所示。由于用户的行为是二元选择(0-1型),因此本案例在计算物品的相似度过程中采用杰卡德相似系数的方法。
表1 相似度计算公式
在协同过滤系统中发现用户存在多种行为方式,如是否浏览网页、是否购买、评论、评分、点赞等行为,若采用统一的方式表示所有行为是困难的,因此只对具体的分析目标进行具体的表示。本案例原始数据只记录了用户访问网站浏览行为,所以用户的行为是浏览网页与否,不存在购买、评分和评论等用户行为。
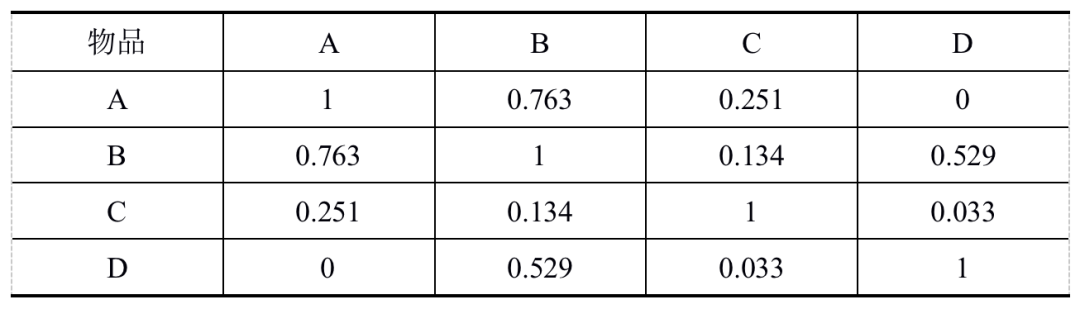
计算各个物品之间的相似度之后,即可构成一个物品之间的相似度矩阵,如表1所示。通过相似度矩阵,推荐算法会给用户推荐与其物品最相似的K个的物品。
表2 相似度矩阵
式(1)度量了推荐算法中用户对所有物品的感兴趣程度。其中R代表了用户对物品的兴趣,SIM代表了所有物品之间的相似度,P为用户对物品感兴趣的程度。由于本案例中用户的浏览行为是二元选择(是与否),所以用户对物品的兴趣R矩阵中只存在0和1。
P=sim×R (1)
推荐系统是根据物品的相似度以及用户的历史行为对用户的兴趣度进行预测并推荐,在评价模型的时候一般是将数据集划分成训练集和测试集两部分。模型通过在训练集的数据上进行训练学习得到推荐模型,然后在测试集数据上进行模型预测,最终统计出相应的评测指标评价模型预测效果的好与坏。
模型的评测采用的方法是交叉验证法。交叉验证法即将用户行为数据集按照均匀分布随机分成M份(本案例M取10),挑选一份作为测试集,将剩下的M-1份作为训练集。然后在训练集上建立模型,并在测试集上对用户行为进行预测,统计出相应的评测指标。为了保证评测指标并不是过拟合的结果,需要进行M次实验,并且每次都使用不同的测试集。最后将M次实验测出的评测指标的平均值作为最终的评测指标。
基于协同过滤推荐算法主要包括两个部分:基于用户的协同过滤推荐和基于物品的协同过滤推荐。结合实际的情况分析判断,选择基于用户的协同过滤推荐算法进行推荐,构建模型的流程如图2所示。
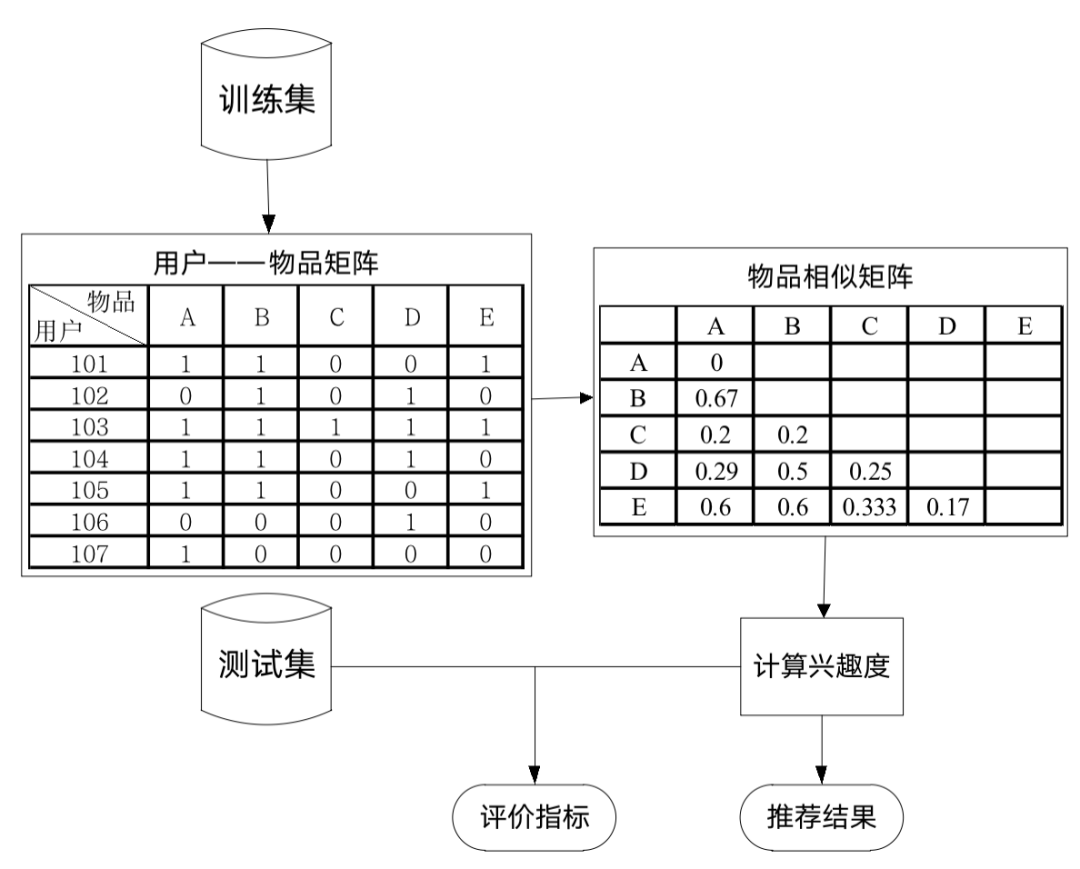
图2 基于物品协同过滤建模流程图
其中训练集与测试集是通过交叉验证的方法划分后的数据集。通过协同过滤算法的原理可知,在建立推荐系统时,建模的数据量越大,越能消除数据中的随机性,得到的推荐结果越好。弊端在于数据量越大,模型建立以及模型计算耗时越久。
2. 优缺点
优点:可以离线完成相似性步骤,降低了在线计算量,提高了推荐效率;并利用用户的历史行为给用户做推荐解释,结果容易让客户信服。
缺点:现有的协同过滤算法没有充分利用到用户间的差别,使计算得到的相似度不够准确,导致影响了推荐精度;此外,用户的兴趣是随着时间不断变化的,算法可能对用户新点击兴趣的敏感性较低,缺少一定的实时推荐,从而影响了推荐质量。
基于物品的协同过滤适用于物品数明显小于用户数的情形,如果物品数很多,会导致计算物品相似度矩阵代价很大。
3. 模型构建
将训练集中的数据转换成0-1二元型数据,使用ItemCF算法对数据进行建模,并对预测推荐结果,如代码清单1所示。
代码清单1 构建模型
# 利用训练集数据构建模型UI_matrix_tr = pd.DataFrame(0,index=IP_tr,columns=url_tr)# 求用户-物品矩阵for i in data_tr.index:UI_matrix_tr.loc[data_tr.loc[i,'realIP'],data_tr.loc[i,'fullURL']]=1sum(UI_matrix_tr.sum(axis=1))# 求物品相似度矩阵(因计算量较大,需要耗费的时间较久)Item_matrix_tr = pd.DataFrame(0,index=url_tr,columns=url_tr)for i in Item_matrix_tr.index:for j in Item_matrix_tr.index:a = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)==2)b = sum(UI_matrix_tr.loc[:,[i,j]].sum(axis=1)!=0)Item_matrix_tr.loc[i,j] = a/b# 将物品相似度矩阵对角线处理为零for i in Item_matrix_tr.index:Item_matrix_tr.loc[i,i]=0# 利用测试集数据对模型评价IP_te = data_te.iloc[:,0]url_te = data_te.iloc[:,1]IP_te = list(set(IP_te))url_te = list(set(url_te))# 测试集数据用户物品矩阵UI_matrix_te = pd.DataFrame(0,index=IP_te,columns=url_te)for i in data_te.index:UI_matrix_te.loc[data_te.loc[i,'realIP'],data_te.loc[i,'fullURL']] = 1# 对测试集IP进行推荐Res = pd.DataFrame('NaN',index=data_te.index,columns=['IP','已浏览网址','推荐网址','T/F'])Res.loc[:,'IP']=list(data_te.iloc[:,0])Res.loc[:,'已浏览网址']=list(data_te.iloc[:,1])# 开始推荐for i in Res.index:if Res.loc[i,'已浏览网址'] in list(Item_matrix_tr.index):Res.loc[i,'推荐网址'] = Item_matrix_tr.loc[Res.loc[i,'已浏览网址'],:].argmax()if Res.loc[i,'推荐网址'] in url_te:Res.loc[i,'T/F']=UI_matrix_te.loc[Res.loc[i,'IP'],Res.loc[i,'推荐网址']]==1else:Res.loc[i,'T/F'] = False# 保存推荐结果Res.to_csv('./tmp/Res.csv',index=False,encoding='utf8')
*代码请联系客服领取,联系方式见文末
通过基于协同过滤算法构建的推荐系统,婚姻知识类得到了针对每个用户的推荐,部分结果如表3所示。
表3 推荐结果
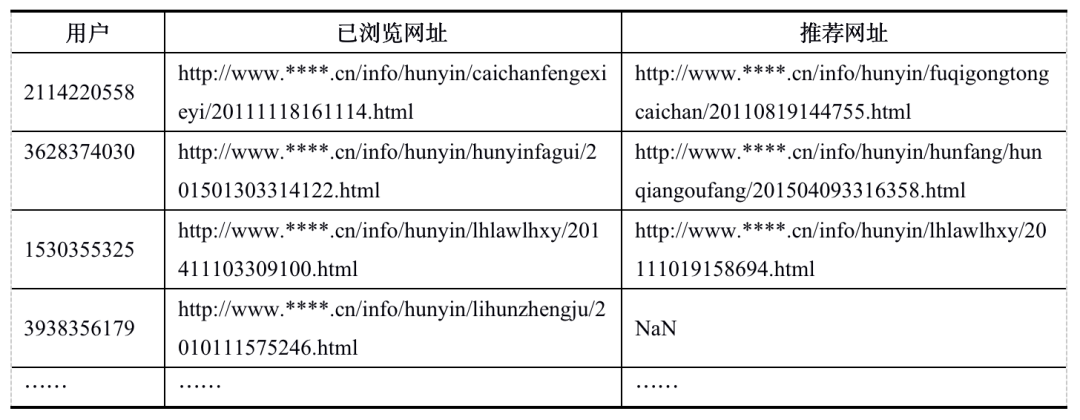
从表3中可知,根据用户访问的相关网址,对用户进行推荐。但是其推荐结果存在NaN的情况。这种情况是由于在目前的数据集中,访问该网址的只有单独一个用户,因此在协同过滤算法中计算它与其他物品的相似度为0,所以就出现无法推荐的情况。一般出现这样的情况,在实际中可以考虑其他的非个性化的推荐方法进行推荐,例如基于关键字、基于相似行为的用户进行推荐等。
4. 模型评价
推荐系统的评价一般可以从如下几个方面整体进行考虑:用户、物品提供者、提供推荐系统网站⑰。好的推荐系统能够满足用户的需求,推荐其感兴趣的物品。同时推荐的物品中,不能全部是热门的物品,同时也需要用户反馈意见帮助完善其推荐系统。因此,好的推荐系统不仅能预测用户的行为,而且能帮助用户发现可能会感兴趣,但却不易被发现的物品。同时,推荐系统还应该帮助商家将长尾中的好商品发掘出来,推荐给可能会对它们感兴趣的用户。在实际应用中,评测推荐系统对三方的影响是必不可少的。评测指标主要来源于如下3种评测推荐效果的实验方法,即离线测试、用户调查和在线实验。
离线测试是通过从实际系统中提取数据集,然后采用各种推荐算法对其进行测试,获各个算法的评测指标。这种实验方法的好处是不需要真实用户参与。
注意:离线测试的指标和实际商业指标存在差距,比如预测准确率和用户满意度之间就存在很大差别,高预测准确率不等于高用户满意度。所以当推荐系统投入实际应用之前,需要利用测试的推荐系统进行用户调查。
用户调查利用测试的推荐系统调查真实用户,观察并记录他们的行为,并让他们回答一些相关的问题。通过分析用户的行为和他们反馈的已经,判断测试推荐系统的好坏。
在线测试顾名思义就是直接将系统投入实际应用中,通过不同的评测指标比较与不同的推荐算法的结果,比如点击率,跳出率等。
由于本例中的模型是采用离线的数据集构建的,因此在模型评价阶段采用离线测试的方法获取评价指标。在电子商务网站中,用户只有二元选择,比如:喜欢与不喜欢,浏览与否等。针对这类型的数据预测,就要用分类准确度,其中的评测指标有准确率(P、precesion),它表示用户对一个被推荐产品感兴趣的可能性。召回率(R、recall)表示一个用户喜欢的产品被推荐的概率。F1指标表示综合考虑准确率与召回率因素,更好的评价算法的优劣。准确率、召回率和F1指标的计算公式如表4所示。
表4 分类准确度评测指标

其中相关的指标说明如表5所示。
表5 分类准确度指标说明表
计算推荐结果的准确率、召回率和F1指标,如代码清单2所示。
代码清单2 计算推荐结果的准确率和F1指标
# 读取保存的推荐结果Res = pd.read_csv('./tmp/Res.csv',keep_default_na=False, encoding='utf8')# 计算推荐准确率Pre = round(sum(Res.loc[:,'T/F']=='True') (len(Res.index)-sum(Res.loc[:,'T/F']=='NaN')), 3)print(Pre)# 计算推荐召回率Rec = round(sum(Res.loc[:,'T/F']=='True') (sum(Res.loc[:,'T/F']=='True')+sum(Res.loc[:,'T/F']=='NaN')), 3)print(Rec)# 计算F1指标F1 = round(2*Pre*Rec/(Pre+Rec),3)print(F1)
*代码请联系客服领取,联系方式见文末
得到的准确率、召回率和F1指标如表6所示。
表6 分类评测指标结果

由于本例是采用的是最基本的协同过滤算法进行建模,因此得出的模型结果也是一个初步的效果,实际应用的过程中要结合业务进行分析,对模型进一步改造。首先需要改造的是一般情况下,最热门物品往往具有较高的“相似性”。比如热门的网址,访问各类网页的大部分人都会进行访问,在计算物品相似度的过程中,就可以知道各类的网页都和某些热门的网址有关。因此处理热门网址的方法如下:
(1)在计算相似度的过程中,可以加强对热门网址的惩罚,降低其权重,比如对相似度平均化,或者对数化等方法。
(2)将推荐结果中的热门网址进行过滤掉,推荐其他的网址,将热门网址以热门排行榜的形式进行推荐,如表7所示。
表7 婚姻知识类热门排行榜
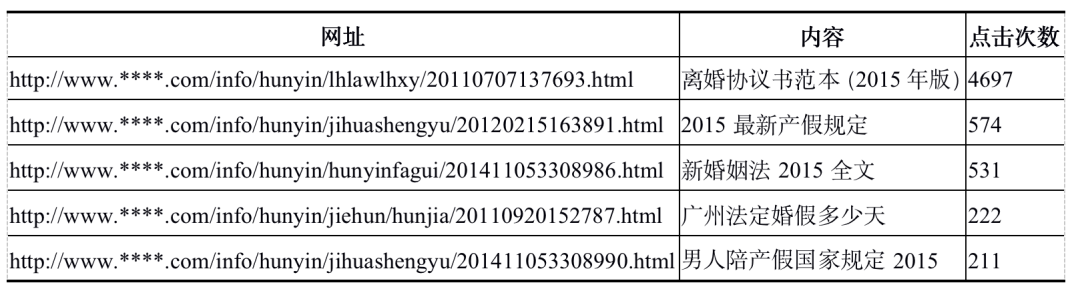
在协同过滤推荐过程中,两个物品相似是因为它们共同出现在很多用户的兴趣列表中,也可以说是每个用户的兴趣列表都对物品的相似度产生贡献。但是并不是每个用的贡献度都相同。通常不活跃的用户要么是新用户,要么是只来过网站一两次的老用户。在实际分析中,一般认为新用户倾向于浏览热门物品,首先他们对网站还不熟悉,只能点击首页的热门物品,而老用户会逐渐开始浏览冷门的物品。因此可以说,活跃用户对物品相似度的贡献应该小于不活跃的用户。所以在改进相似度的过程中,取用户活跃度对数的倒数作为分子,即本例中相似度的公式如下。
然而在实际应用中,为了尽量的提高推荐的准确率,还会将基于物品的相似度矩阵按最大值归一化,其好处不仅仅在于增加推荐的准确度,它还可以提高推荐的覆盖率和多样性。由于本例的推荐是针对某一类数据进行推荐,因此不存在类间的多样性,所以本节就不进行讨论。
当然,除了个性化推荐列表,还有另一个重要的推荐应用就是相关推荐列表。有过网购的经历的用户都知道,当你在电子商务平台上购买一个商品时,它会在商品信息下面展示相关的商品。一种是包含购买了这个商品的用户也经常购买的其他商品,另一种是包含浏览过这个商品的用户经常购买的其他商品。这两种相关推荐列表的区别:使用了不同用户行为计算物品的相似性。
本篇连载已结束
整理不易,求三连(分享、点赞、在看)
