





泰迪学院-Hadoop连载
公众号ID:taidixueyuan
MapReduce简介
MapReduce是Hadoop的核心计算框架,是用于大规模数据集(大于1TB)并行运算的编程模型,主要包括Map(映射)和Reduce(规约)两部分。当启动一个MapReduce任务时,Map端会读取HDFS上的数据,将数据映射成所需要的键值对类型传到Reduce端。Reduce端接收Map端传过来的键值对类型的数据,根据不同键进行分组,对每一组键相同的数据进行处理,得到新的键值对输出到HDFS,这就是MapReduce的核心思想。
MapReduce工作原理
MapReduce作业执行流程如图1所示。
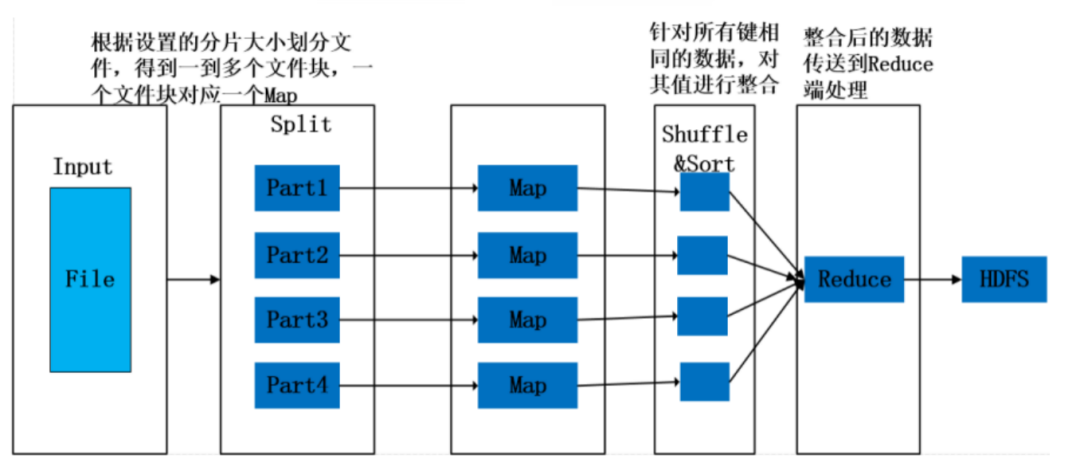
图1 MapReduce执行流程图
一个完整的MapReduce过程包含数据的输入与分片、Map阶段数据处理、Reduce阶段数据处理、数据输出等阶段。
(1)读取输入数据:MapReduce过程中,数据是从HDFS分布式文件系统中读取的。文件在上传到HDFS时,一般按照128MB分成了几个数据块,所以在运行MapReduce程序时,每个数据块都会生成一个Map,但是也可以通过重新设置文件分片大小调整Map的个数,在运行MapReduce时会根据所设置的分片大小对文件重新Split(分割),一个分片大小的数据块就会对应一个Map。
(2)Map阶段:程序有一个或多个Map,由默认存储或分片个数决定。针对Map阶段,数据以键值对的形式读入,键的值一般为每行首字符与文件最初始位置的偏移量,即中间所隔字符个数,值为这一行的数据记录。根据需求对键值对进行处理,映射成新的键值对,将新的键值对传到Reduce端。
(3)Shuffle/Sort阶段:此阶段是指从Map输出开始,传送Map输出到Reduce作为输入的过程。该过程会将同一个Map中输出的键相同的数据先进行一步整合,减少传输的数据量,并且在整合后将数据按照键排序。
(4)Reduce阶段:Reduce任务也可以有多个,按照Map阶段设置的数据分区确定,一个分区数据被一个Reduce处理。针对每一个Reduce任务,Reduce会接收到不同Map任务传来的数据,并且每个Map传来的数据都是有序的,一个Reduce任务中的每一次处理都是针对所有键相同的数据,对数据进行规约,以新的键值对输出到HDFS。
根据上述内容分析,其实MapReduce的本质用一张图可以完整地表现出来,如图2所示。
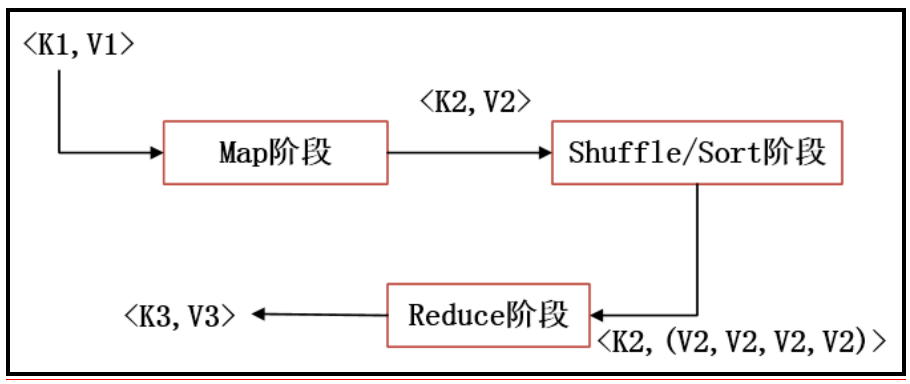
图2 MapReduce本质
MapReduce的本质就是把一组键值对<K1,V1>经过Map阶段映射成新的键值对<K2,V2>,接着经过Shuffle/Sort阶段进行排序和“洗牌”,把键值对排序,同时把相同的键的值整合,最后经过Reduce阶段,把整合后的键值对组进行逻辑处理,输出新的键值对<K3,V3>,这样的一个过程,其实就是MapReduce的本质。
通过图3的小例子简单理解MapReduce本质,理解MapReduce的Map端和Reduce端的基本运行原理。
例子中有键值对(1,3)、(2,7)、(1,4)、(2,8)分别在两个Map中,Map阶段的处理是对键值对的值进行平方,则两个Map输出分别为(1,9)、(2,49)和(1,16)、(2,64)。Reduce阶段是对一个或多个Map输出按键进行处理,这里是对同一个键的值相加,Reduce把两个Map的输出整合到一起,对键都为1的值相加,键都为2的值相加,得到新的键值对(1,25)、(2,113)。
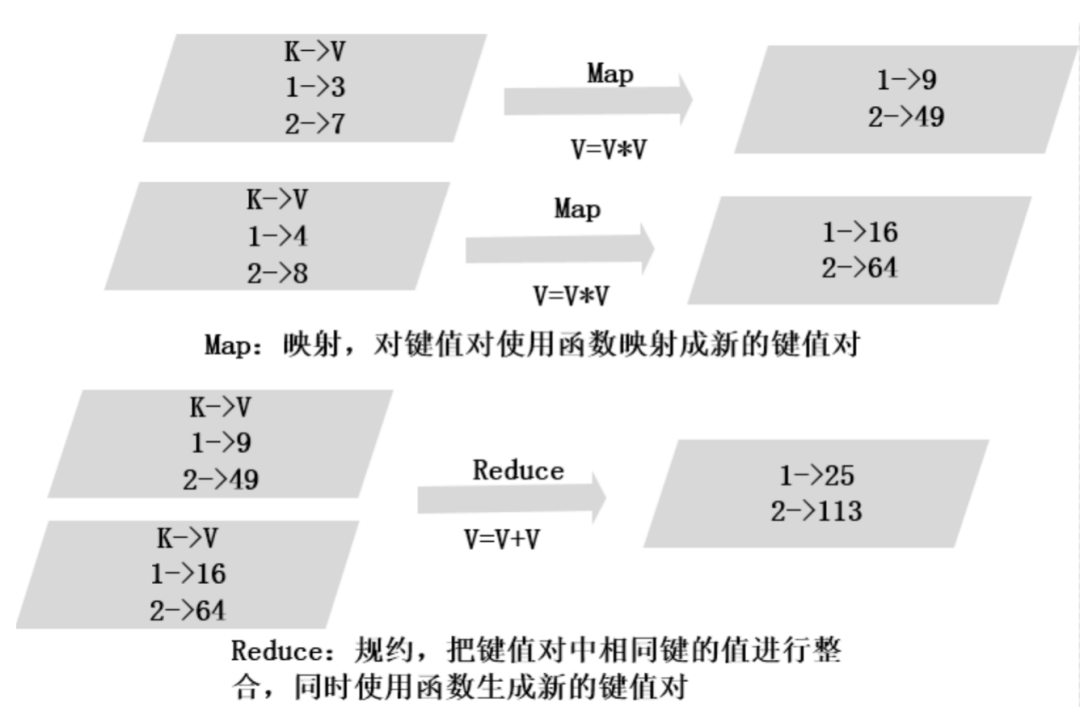
图3 MapReduce映射实例

