
泰迪学院-Hadoop连载
公众号ID:taidixueyuan
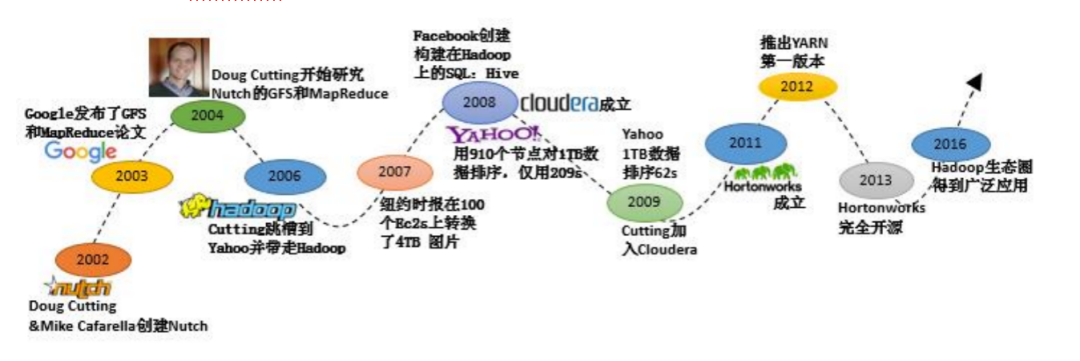
这是一个全新的栏目,专门为Hadoop小白开放,今天我们先来聊聊Hadoop是什么,以及Hadoop发展史。


文章转载自泰迪教育,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。





泰迪学院-Hadoop连载
公众号ID:taidixueyuan
这是一个全新的栏目,专门为Hadoop小白开放,今天我们先来聊聊Hadoop是什么,以及Hadoop发展史。
