





·下面那个是软件队列,上面那个是硬件队列
·当我们入的数据比较多,出的数据比较少,随着数据的堆积,导致我们路由器的硬件队列已经满了的情况下,那么我们的软件队列就能够派上用场了。

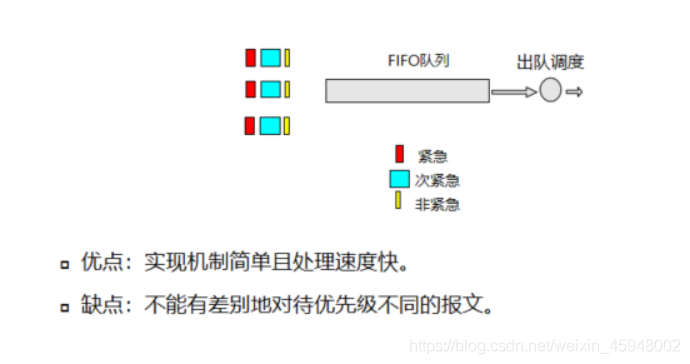
软件队列在没有设置,也就是FIFO的情况下,实际上不管是紧急、次紧急数据还是非紧急数据,采用的都是先进先出的模型,调度器采用先进来的先走的顺序,从队首开始依次向硬件队列发送报文,在报文发送的时候数据不会有任何区别,因此等待数据到达硬件队列时,由于硬件队列使用的是FIFO,因此软件队列采用FIFO不会对报文传送的质量提供任何保证。


·FIFO实际上所有数据报文是一个队列
·加队就是按照先后顺序加队的,按尾丢弃原则丢弃
·华为设备上在防火墙上的出接口上看得到FIFO
·对于FIFO实际上只能修改FIFO的长度
PQ
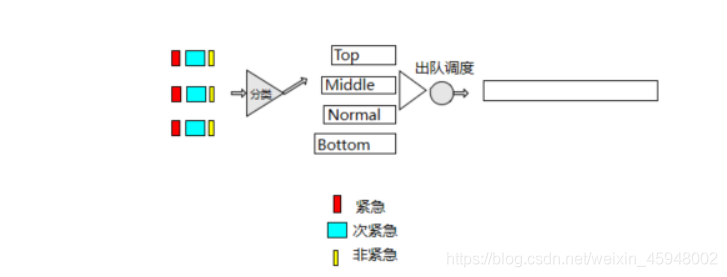
·PQ是一种优先级队列:按照严格优先级进行调度的队列,PQ对队列划分等级,只有高优先级的队列排空以后才会对低一级的队列调度报文,这样重要的业务比其他业务提前获得服务。

·PQ调度机制:分为4个队列,分别为高优先队列(Top)、中优先队列(Middle)、正常优先队列(Normal)和
低优先队列(bottom)



·每个队列中都存在长度,如果队列里面数据满了,那么也会丢弃。
·PQ的特征:

PQ的优缺点:
1、优点:
①高优先级队列的时延控制的非常好
②实现简单,能够区分多种业务
2、缺点:
①无法做到带宽的合理分配,高优先级的流量比较大时,导致低优先级的流量产生“饿死现象”
②高优先级的实验得到保证的代价是牺牲低优先级的时延
③如果高优先级传送TCP流量,低优先级传送UDP流量,那么TCP增加传送速率,导致UDP流量无法得到足够的带宽。
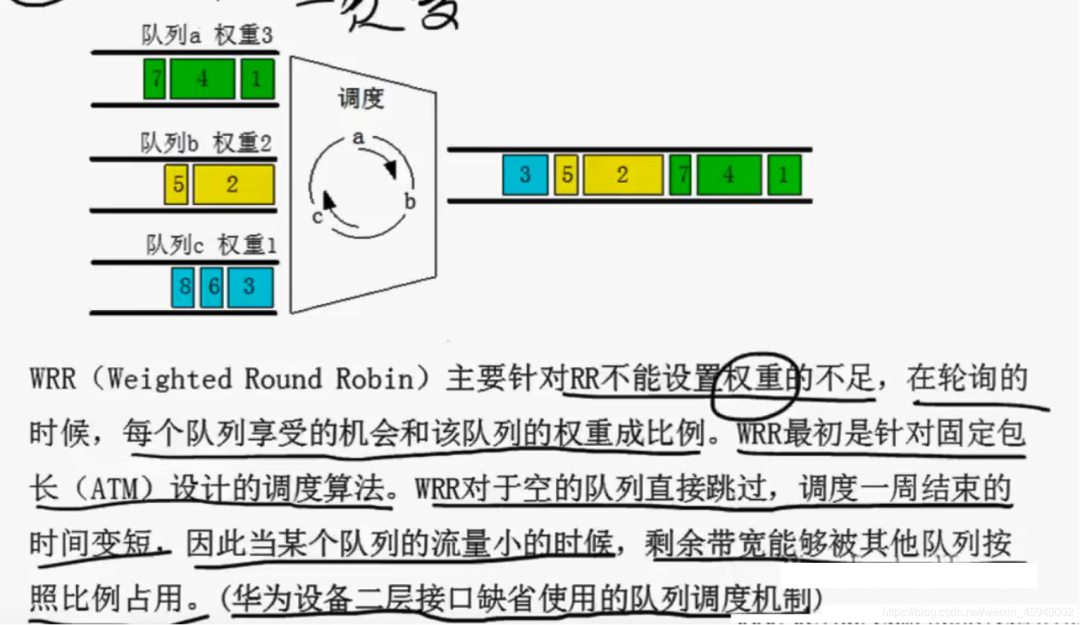
WRR
·要了解WRR的话首先要了解RR

RR(Round Robin,轮询调度算法):实现原理:对多个队列进行调度RR以环形的方式轮询多个队列。如果轮询的队列不为空,那么就从队列中取走一个报文;
如果为空,那么就跳过这个队列,调度器不会进行等待。有点类似于完全公平的政策。
RR的优缺点:
1、优点:
①隔离不同的流,实现队列之间对带宽的平等利用
②剩余带宽能够被其他队列平均分配
2、缺点:
①无法设置队列带宽的权重,也就是完全公平
②当不同队列中的报文长度不一的时候,调度不准确;
③当调度速率低的时候,时延和抖动的问题比较突出,比如一个包到达一个空队列,而这个队列刚刚被调度完毕
,则这个包要等其他全部的队列调度完才能取得出接口的机会,这样会导致抖动比较大,但是如果调度速度非常高,
则这种时延可以忽略,RR在高速路由器内部有很多应用。
·WRR
WRR优缺点:
1、优点
①能够按照权重分配带宽,并且队列中剩余带宽能够为其他队列公平占用
②实现比较简单、复杂度低
③实现diffserv聚合后的端口
2、缺点
①与RR调度算法一致,在报文长度不一致的时候,调度不准确
②在调度速率低的时候报文的时延控制的不好,时延抖动无法预期。
·对于WRR来说,实际上也是按照字节去调度的
·针对这种按照字节去调度不准确的问题,实际上还存在一个调度算法为DRR
(赤字轮询):类似于蚂蚁花呗,比如队列A中来了2000个字节的数据,但是现在我们只能调度1500个字节
针对这种情况,我们可以再借500个字节,先将2000的发送出去,发送出去之后,刚好在下次内容发送的时候
来了个1000个字节,那么在这种情况下,还掉原先借的500,刚好发了个1000的出去。
WFQ
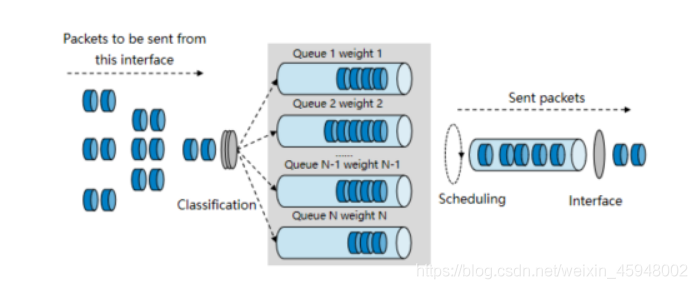

·WFQ采用的是五元组的方式去进行分类,如果存在优先级,那么就是六元组。这个优先级就是DSCP或者IPP的体现
因此WFQ肯定是六元组。
·每一个流被分配到一个队列,该过程称为散列,采用HASH算法来自动完成,这种方式会尽量将不同特征的流分入不同的队列中。WFQ允许的队列数目是有限的,用户可以根据需要配置该值。
·在出队的时候,WFQ按流的优先级来分配每个流应占有的出口带宽。优先级的数值越小,所得的带宽越少。优先级的数值越大,所得的带宽越多。这样就保证了相同优先级业务之间的公平,体现了不同优先级业务之间的权值。
WFQ优点在于配置简单,但由于流是自动分类,无法手工干预,故缺乏一定的灵活性;且受资源限制,当多个流进入同一个队列时无法提供精确服务,无法保证每个流获得的实际资源量。WFQ均衡各个流的延迟与抖动,同样也不适合延迟敏感的业务应用。
通过以上分析,会发现如果所有队列都应用一种调度算法都存在各自的优缺点,且不能很好地满足业务需求,但通过分析会发现有些调度算法之间的优缺点正好是互补的,试想:是否可以设置不同的队列应用不同的调度算法,这样是否就能很大程度满足业务需求呢?
CBQ
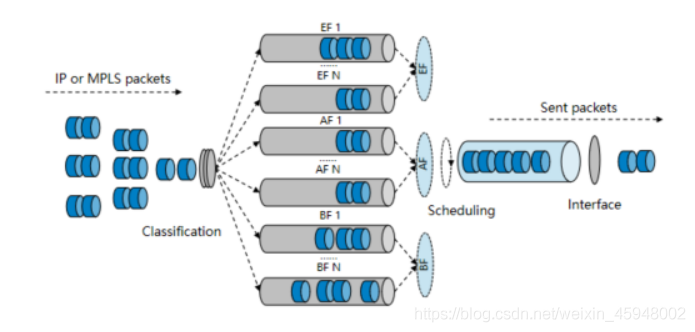
CBQ(Class-based Queueing)基于类的加权公平队列—是对WFQ功能的扩展,为用户提供了自定义类的支持。CBQ首先根据IP优先级或者DSCP优先级、入接口、IP报文的五元组等规则来对报文进行分类,然后让不同类别的报文进入不同的队列。对于不匹配任何类别的报文,会送入系统定义的缺省类。
CBQ提供三类队列:
EF队列:满足低时延业务。
EF队列拥有绝对优先级,仅当EF队列中的报文调度完毕后,才会调度其他队列中的报文。
AF队列:满足需要带宽保证的关键数据业务。
每个AF队列分别对应一类报文,用户可以设定每类报文占用的带宽。当系统调度报文出队的时候,会按用户为各类报文设定的带宽将报文进行出队发送,可实现各个类的队列的公平调度。
BE队列:满足不需要严格QoS保证的尽力发送业务。
当报文不匹配用户设定的所有类别时,报文会被送入系统定义的缺省BE(Best Effort,尽力传送)类。BE队列使用接口剩余带宽和WFQ调度方式进行发送。
优点:提供了自定义类的支持;可为不同的业务定义不同的调度策略。
缺点:由于涉及到复杂的流分类,故启用CBQ会耗费一定的系统资源。

拥塞避免机制:

尾丢弃缺点:
①TCP全局同步

②TCP饥饿

③高延时以及高抖动

④

针对TCP全局同步的问题解决办法:
RED:
为避免TCP全局同步,可在队列未装满时先随机丢弃一部分报文。通过预先降低一部分TCP连接的传输速率来尽可能延缓TCP全局同步的到来。这种预先随机丢弃报文的行为被称为早期随机检测(RED)。
特点:RED为每个队列的长度都设定了阈值门限,并规定:
当队列的长度小于低门限时,不丢弃报文。
当队列的长度大于高门限时,丢弃所有收到的报文。
当队列的长度在低门限和高门限之间时,开始随机丢弃到来的报文。方法是为每个到来的报文赋予一个随机数,并用该随机数与当前队列的丢弃概率比较,如果大于丢弃概率则报文被丢弃。队列越长,报文被丢弃的概率越高。
问题:但是对于RED而言,会导致无差别丢弃以TCP饿死,因此有以下技术能够解决所有尾丢弃问题:
解决问题:
WRED:
基于RED技术,又实现了WRED(Weighted Random Early Detection)技术,可实现每一种优先级都能独立设置报文的丢包的高门限、低门限及丢包率,报文到达低门限时,开始丢包,到达高门限时丢弃所有的报文,随着门限的增高,丢包率不断增加,最高丢包率不超过设置的最大丢包率,直至到达高门限,报文全部丢弃。这样按照一定的丢弃概率主动丢弃队列中的报文,从一定程度上避免了尾丢弃带来的所有缺点。

所有关于QoS-拥塞管理与拥塞避免(上)的技术分享可点击下方链接回顾学习:技术贴|QoS-拥塞管理与拥塞避免(上)

课程咨询 :400-1024-400
欢迎添加,了解腾科课程体系介绍,可获取学习资源。
官方微博:腾科教育官微
官网:www.tk-edu.com
全国统一热线:400-1024-400

