






本文带大家了解AI-语音处理理论与应用语音处理中的基础知识及应用、掌握语音处理的基本步骤、掌握语音处理的主要技术、了解语音处理的难点与展望等知识点。
首先,先看一个语音小场景~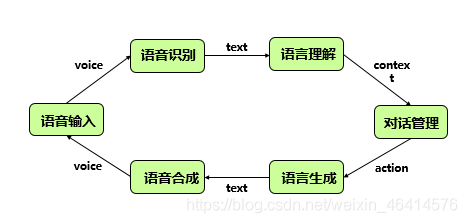
比如,如今在网络上订票可以通过语音进行交互;会分为这么几步:
1.客户说:“我要订一张从北京到杭州的机票。”
2.机器识别到语音输入
3.通过语音识别的模块,将语音转换成语言,即转换成文本“我要订一张从北京到杭州的机票。”
4.对话管理模块对文本进行理解,结合上下文,生成一个动作action,这个动作决定了机器到底是确定还是不确定;比如说你没有说机票的时间,对话管理模块就会根据这个情况生成一个动作比如说“时间不确定”
5.语音合成模块接收到这个动作“时间不确定”,来生成人能理解的语言,比如说“请问您要定哪一天的机票?”这样一个文本。

6.语音合成模块接收到语言生成模块生成的文本,通过语音的方式和人交互,通过语音合成技术将文本转换成语音“请问您要订哪一天的机票的?”返回给客户
语音的小场景是跟传统的GUI进行比对,传统的GUI是通过界面化的方式来跟人进行交互,但是语音是通过VUI方式进行交互。
语音处理介绍

• 语音信号处理(Speech Signal Processing)简称语音处理,是用以研究语音发声过程、语音信号统计特性、语音自动识别、机器合成以及语音感知等各种处理技术的总称。
• 由于现代的语音处理技术都以数字计算为基础,并借助微处理器、信号处理器或通用计算机加以实现,因此也称数字与因信号处理。

• 简单来讲,语音处理技术就是通过语音到它的某些特征之间的转换这个过程中所涉及到的一系列技术,这个特征可以是数字特征(频率、时长)、文本特征(代表的具体文字)
语音处理介绍
• 语音信号处理的研究起源于对对发音器官的模拟。
• 1939年美国H.杜德莱(H.Dudley)展出了一个简单的发音过程模拟系统,以后发展为声道的数字模型。利用该模型可以对语音信号进行各种频谱及参数的分析,进行通信编码或数据压缩的研究,同时也可基于此合成语音信号,实现机器的语音合成。
• 语言信息主要包含在语音信号的参数之中,因此准确而迅速地提取语言信号的参数是进行语音信号处理的关键。
语音识别
• 语音识别技术就是让机器通过识别和理解把语音信号转变为相应的文本或命令的技术。
• 语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
语音识别发展史
• 1952年,贝尔研究所研究成功了世界上第一个能识别10个英文数字发音的试验系统;
• 1970年以后,在小词汇和孤立词的识别方面取得了实质性进展;
• 1980年以后,孤立词转向连接词(识别一句话)识别;
• 1987年12月,李开复开发出世界上第一个“非特定人连续语音识别系统”,用统计方法提升了语音识别率;
• 1990年以后,大词汇量连续语音识别得到优化;
• 1997年,IBM Viavoice首个语音听写产品问世;
• 2010年,Google Voive Action支持语音操作与搜索;
• 2011年初,微软的DNN在语音搜索任务上取得成功,科大讯飞将DNN首次成功应用到中文语音识别领域;
• 2011年10月,苹果iPhone 4S自带的语音助手Siri一炮走红;
• 2013年,Google发布Google Glass,苹果发布iWatch都嵌入语音交互功能;
• 趋势:
• 语音识别任务越来越复杂
• 用到的模型越来越复杂
• 技术从实验室走入生活
语音识别任务处理流程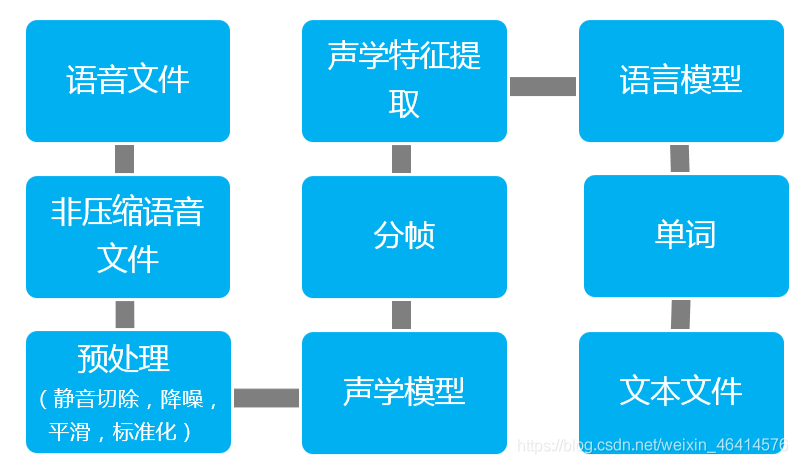
1.得到语音文件(mp3、wav……)
2.将语音文件进行还原
3.还原后进行预处理,满足一定数据要求
4.通过声学模型、分帧、声学特征提取得到语言模型、单词、文本文件
5.对于现代的语音识别的任务来说,有些过程是合并在一起的,成为一个end-to-end的形式
语音识别的应用
• 语音打字机:说一句话快速翻译出来;搜狗听写
• 语音搜索:购物网站购物可以通过语音搜索
• 语音拨号
• 语音助手
语音合成

• 语音合成,又称文语转换(Text-To-Speech TTS)技术,能将任意文字信息转化为相应语音朗读出来。
• 语音合成涉及声学、语言学、数字信号处理、计算机科学等多个学科技术,是中文信息处理领域的一项前沿技术。
• 为了合成出高质量的语言,除了依赖于各种规则,包括语义学规则、词汇规则、语音学规则外,还必须对文字的内容有很好的理解,这也涉及到自然语言理解的问题。
语音合成应用场景
大部分都和语音识别相结合,语音识别通过人向机器传输信息,语音合成通过机器向人传输信息;比如:
• 服务机器人
• 客服系统
• 智慧家具
• 出行导航
• 阅读软件
语音合成系统
• 一个完整的语音合成系统过程是先将文字序列转换成音韵序列,再由系统根据音韵序列生成语音波形。其中:
• 第一步涉及语言学处理,例如分词、字音转换等,以及一整套有效的音律控制规则;
• 第二步需要先进的语音合成技术,能按要求实时合成出高质量的语音流。
• 语音合成技术的研究已有两百多年的历史,但真正具有实用意义的近代语音合成技术是随着计算机技术和数字信号处理技术的发展而发展起来的,主要是让计算机能够产生高清晰度、高自然度的连续语音。
语音合成处理流程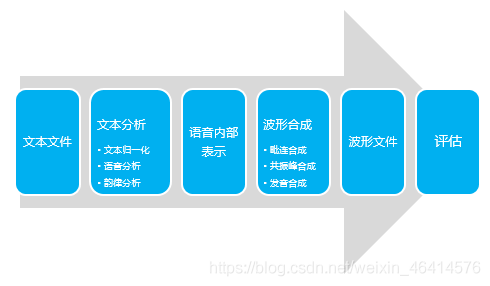
1.拿到文本文件
2.对文本进行分析
文本归一化:把缩写的词完整化
语音分析:分词
韵律分析:这句话代表什么情绪、代表什么角色
3.语音内部表示
4.波形合成
5.形成完整的波形文件
6.对波形文件进行评估看是否满足需求
文本分析
• 语音识别中的文本分析主要的工作是把文本数据转换成语音内部表示(Phonemic Internal Representation)。具体内容包括:
• 文本归一化:对形形色色的自然文本数据进行预处理或者归一化,包括句子的词例还原,非标准词,同形异义词排歧等;
• 语音分析:文本归一化之后的下一步就是语音分析,具体方法包括通过大规模发音词典,字位-音位转换规则;
• 韵律分析:分析文本中的平仄格式和押韵规则,这里主要包含三方面的内容,包括:韵律的机构,韵律的突显度,音调。
语音合成方法
• 在语音合成技术的发展过程中,早期的研究主要是采用参数合成方法,后来随着计算机技术的发展又出现了波形拼接的合成方法。
• 参数合成
• 在语音合成技术的发展中,早期的研究主要是采用参数合成方法。值得提及的是Holmes的并联共振峰合成器(1973)和Klatt的串/并联共振峰合成器(1980),只要精心调整参数,这两个合成器都能合成出非常自然的语音。但准确提取共振峰参数比较困难,合成语音的音质难以达到实用要求。
• 波形拼接
• 自八十年代末期至今,语言合成技术又有了新的进展,特别是基音同步叠加(PSOLA)方法的提出(1990),使基于时域波形拼接方法合成的语音的音色和自然度大大提高,自然度比以前基于LPC方法或共振峰合成器的自然度要高,并且基于PSOLA方法的合成器结构简单,易于实时实现,有很大的商用前景。


课程咨询 :400-1024-400
欢迎添加,了解腾科课程体系介绍,可获取学习资源。
官方微博:腾科教育官微
官网:www.tk-edu.com
全国统一热线:400-1024-400

