





大数据的数据采集是一个重要的步骤,那么爬虫是一个工具可以帮助我们爬取网站中的数据,爬虫的主要作用就是可以帮助我们爬取想要获取的历史数据。

什么是爬虫?
爬虫可以帮助我们在互联网上自动的获取我们所需要的数据和信息。爬虫的本质是一段程序。因为需要爬取的网站下有可能会套一层另外的一个网站,他是一层一层的去爬的。所以爬虫又被称为网页蜘蛛,网络机器人。
爬虫可以根据用途两类
聚焦爬虫:针对特定的网站。
通用爬虫:通常指搜索引擎的爬虫。
爬虫可以通过模拟浏览器发送网络请求,接收请求响应。
爬虫可以按照一定的规则,自动地抓取互联网信息。
浏览器访问网站过程如下: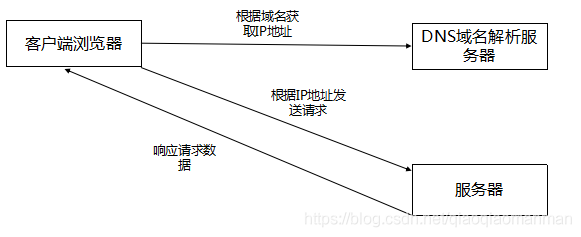
注意:
由于某些需求,我们要获取某个网站的大量数据,但是我们却不想一条条的去获取,所以我们可以使用爬虫帮助我们去批量获取。这个过程我们称为爬取数据。我们所爬取的数据本就是网站展示的免费数据,是合法的。
当爬虫程序绕过网站的一些权限和安全机制去获取一些受保护或者付费数据时,则为偷取数据,是违法的。

爬虫常用术语
可以在网页查看时用f12进行查看,不同的数据会用不同的格式存放显示:一般就是用到下面的几种格式
JSON:(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易地进行阅读和编写,同时也方便了机器进行解析和生成。格式相似于Python中的字典–用键值对的方式,小巧轻便使用广泛。例如:{“json”:“data”}。
XML:传输和存储数据的一种格式,过于笨重,逐渐被json取代。例如:xml。
HTML:超文本标记语言,是常用的网站前端页面编写语言。例如:html。
Ajax:是一种动态的网页加载技术。
JavaScript(JS):是一种脚本语言,常用于网页的动态效果和数据加载。
爬虫的流程:
发送请求–获取响应–提取数据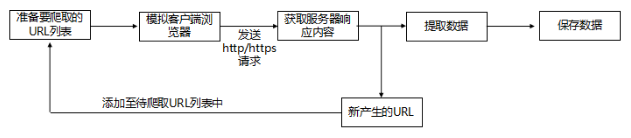
URL:统一资源定位符,俗称网址。
http,https :传输协议。
爬虫工作的流程
准备好要爬取URL,设置好URL的范围,防止URL范围过大或者重复;
增加headers字段等信息,将爬虫伪装成一个浏览器,向目标服务器发送http或者https请求;
接收目标服务器响应的数据;
根据设置的数据提取表达式,对网站数据和新产生的URL进行提取;
将新的URL添加至带爬取的URL队列,进行新一轮的爬取。
将获取到的数据保存至数据库或者本地文件等。
1.请求:
请求行:请求方法字段、URL和HTTP协议版本。
请求头:User-Agent,主机地址Host。
空行:发送换行符,通知服务器以下不再有请求头。
请求体:我们发送的请求数据(这一部分数据并不是每个请求必须的)。
请求方法:
get:参数放置在URL里面。
post:参数放在请求体里面。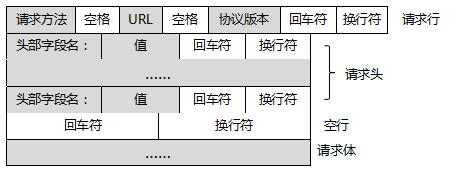
2.响应:
状态行 :协议版本,状态码,状态码描述。
响应头:与请求头类似,附加了一些其他信息。
空行:发送换行符,通知服务器以下不再有响应头。
响应体:包含了我们所请求的数据。
常用状态码:
200:请求成功。
301:重定向。
403:拒绝访问。
404:未找到。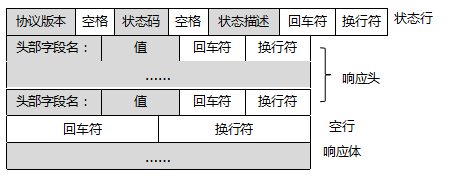
爬虫常用工具
请求和响应库:http.client ,urllib,requests 。
Urllib底层基于httplib实现,requests则基于urllib,httplib为底层模块。

爬虫框架
Scrapy,Scrapy-Redis,PySpider。
框架就是本来就可以进行爬取数据,但是我们可以对它进行优化填充
框架是一个将某一类问题的共性提取出来,为这些共性事先编写好相应的代码并将它们进行封装以便复用的一种工具。它可以提高我们的开发效率,使我们减少编写重复的代码。
简单的例子,如果我们把一个工程当做一个可居住的房子。那么,框架就像满足我们需求户型的一个毛坯房,在框架内编写程序就像在装修房子。
它和模块的区别:模块是指能够单独命名并独立地完成一定功能的程序语句的集合(即程序代码和数据结构的集合体),框架则是一个程序的架构。
数据提取工具:正则表达式,Beautiful Soup4, XPath,JsonPath。
其他工具:Selenium。
Selenium是一个用于Web应用程序测试的工具。

代理IP的分类
透明代理:透明代理直接“隐藏”你的IP地址,但是可以查到你是谁。
匿名代理:使用匿名代理,别人只能知道你用了代理,无法知道你是谁。
高匿代理:高匿代理让别人根本无法发现你是在用代理,是最好的选择。
代理IP的工作工程如下图所示。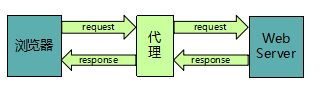
用代码完成爬虫:
首先在软件anaconde中创建工程,将想要爬取的网站放在start url上,用脚本的方式爬取: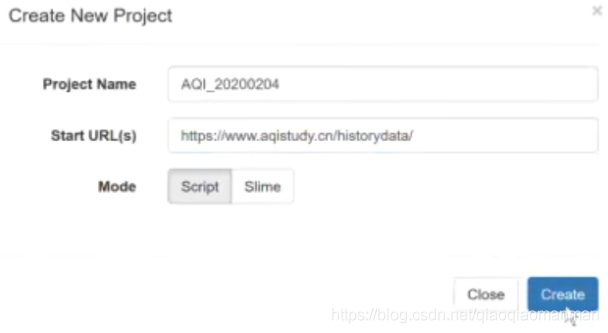 from pyspider.libs.base_handler import *
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
#############爬取某个站点的信息
crawl_config = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",
"Cookie":"UM_distinctid=17001adf2cd16e-0d4537e55c6c28-4c302978-e1000-17001adf2cf160"
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://www.aqistudy.cn/historydata', callback=self.index_page,validate_cert=False)##关闭站点的证书信任
@config(age=10 * 24 * 60 * 60)
def index1_page(self, response):
for each in response.doc('.unstyled1 a').items():
self.crawl(each.attr.href,validate_cert=False,fetch_type='js',js_script="""function() {setTimeout("$('.more').click()", 2000);}""",callback=self.detail_page)# 代码中的JS为等待浏览器加载数据
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('div > li > a').items():
self.crawl(each.attr.href, callback=self.index1_page,fetch_type='js',js_script="""function(){setTimeout("$('.more').click()",2000);}""")
@config(priority=2)
def detail_page(self, response):
import pandas as pd
title_data = response.doc("* tr > th").text()# 获取标签数据
data = response.doc("* > * tr > td").text()# 获取表格内的具体数据
title_list = title_data.split(" ")# 将获取的数据进行分割
data_list = data.split(" ")
data_AQI={}# 新建字典用来存放处理后的数据
for i in range(len(title_list)):# 按照标签进行数据处理
data_AQI[title_list[i]]= data_list[i::9]# 将数据处理为字典形式
data = pd.DataFrame(data_AQI)# 转换成DataFrame格式
data.to_csv("C:\\Users\\Ahahaha\\Desktop\\ data1.csv",index=False,encoding="GBK")# 路径可以更换为想要存储数据的路径,此处存储至windows本地桌面,windows中的编码格式为GBK。
return
return {
"url": response.url,
"title": response.doc('title').text(),
}


联系我们:
微信:smallbellbee
欢迎添加,了解腾科课程体系介绍,可获取学习资源。
官方微博:腾科教育官微
官网:www.tk-edu.com
全国统一热线:400-1024-400

