




hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 百度百科
APP的用户分析中常用的一个指标是留存率,用来评判用户对APP的使用粘性,依据不同的业务场景可以选取合适的计算方式,以日粒度的留存为例,如何计算得到N日的留存率呢?
假设我们有一个记录每个用户标识及访问日期的基础数据表,要计算1~N日的留存率,该如何处理?
以次日留存率为例=次日留存用户数/当日访问用户数,可以通过left join来实现查询,但如果要一次性计算多天的可以构造一个留存天数的辅助列来实现:
示例HQL:
SELECT t.dt,t.days,count(DISTINCT uid)
FROM
(
/* 构建辅助字段days表示留存的天数,从0开始的整数*/
SELECT a.uid,a.dt,b.dt-a.dt AS days
FROM hdp_defaultdb.test a
LEFT JOIN
hdp_defaultdb.test b
on a. uid =b. uid
WHERE a.dt<=b.dt /* 要求留存日期大于访问日期*/
GROUP BY a.uid,a.dt,b.dt-a.dt
)t
GROUP BY t.dt,t.days
步骤详解:
1-数据源的表内容示例:
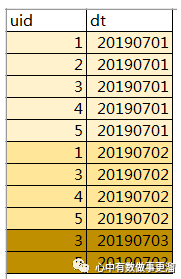
2、进行关联后的数据表结果:
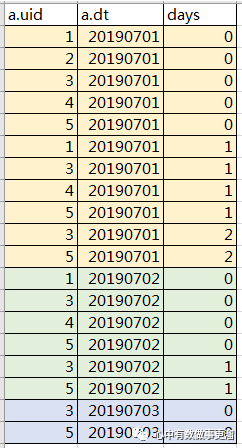
3、再进行一次汇总后的结果为:

这样就快速算出来了。
作为数据分析师,数据是分析的基础材料,数据获取的能力是硬技能,所以hive技能必须要掌握,hive系列计划写一些使用频率高的小知识点。
最后,借楼立个flag:本号至少要保持月更。
文章转载自心中有数做事更溜,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
