




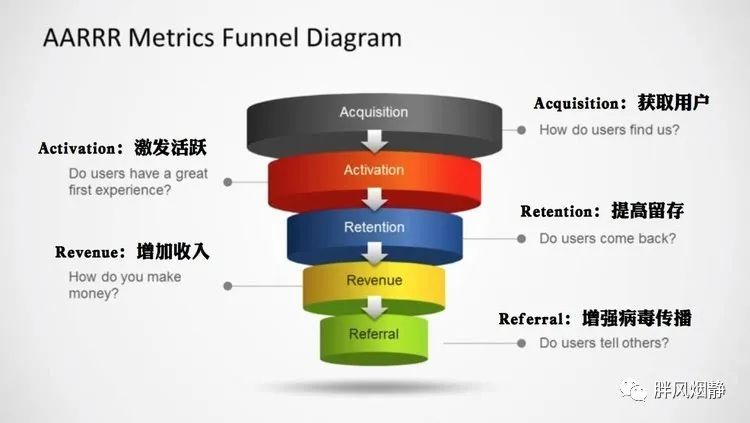
一提事件分析和漏斗分析,大家都会有那么一个笼统的概念,并且觉得自己知道那是什么,Very Easy。但真的如此吗?!
Part 1
你真的了解事件分析吗?
1、事件分析不仅是click点击的统计
事件是用户在App中行为分析的基础,用户对App的每一个行为,都是一个事件。事件可以是启动App、注册登录、浏览商品页、加入购物车、支付订单等等。
事件分析,是指基于事件的统计指标、属性分组、条件筛选等对事件进行查询分析。
统计指标
总次数、用户数、人均次数是一般的事件统计指标,针对一些有属性的事件,我们也可以考虑将属性数据或数值作为事件统计指标;
属性分组
是指事件的属性数据或数值,事件的属性可以是类型型属性,也可以是数值型属性,通过属性我们可以对事件进行进一步的分析;
条件筛选
条件筛选是一个功能,用来进行筛选的条件可以是事件的属性分组,也可以是用户的属性,通过不同条件的筛选和对比,可以为我们提供更多的视角分析事件。
2、事件的Label和参数
2.1 事件Label
为方便对相同类型的事件类型进行归类,在事件统计中,提供了事件标签(Label)的方法;即相同类型的事件可以使用相同的事件ID和不同的事件Label,通过事件ID+事件Label的方式,指代一个特定的事件。
并不是所有厂商都通过事件Label来进行事件分析,其实如果使用得当,我们可以将它合并为事件参数,通过事件参数的复合分析来达到Label分析起的作用。
2.2 事件参数
一个事件在发生的时候,可能会伴随很多额外数据,例如我们在携程搜索酒店的时候,点击搜索按钮之前会先设置城市位置、酒店级别、入住人数等等信息,搜索时设置不同参数的用户,对搜索结果的处理可能很不同,例如在一个酒店很紧俏的地方,入住人数很多的用户可能会搜索不到很多或者合适的结果,这就会导致该用户的酒店预订转化率比其他用户低。因此,我们在事件发生时,还需要关注用户事件的相关参数,以做进一步的分析。
通常,事件参数都会被分为两类:类型型参数和数值型参数;
类型型参数,是枚举型的,他可以作为分类统计,但不能进行数据计算,像商品分类、商品颜色、商品名称可以作为加入购物车事件的类型型参数;
数值型参数,是可以进行数值计算的参数,例如加入购物车事件的商品价格、商品数量,搜索酒店时候的入住人数等。
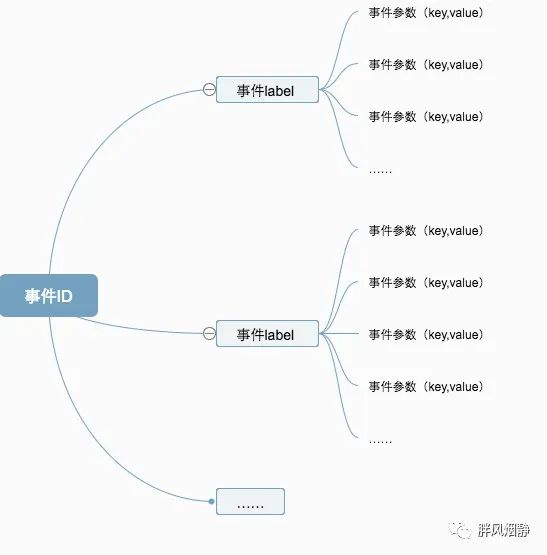
图1:事件ID、事件Label和事件参数之间的关系
在埋点时,需要开发人员在事件发生时,将事件属性放在事件数据中一同上报,这样我们就可以收到事件的完整埋点信息,包括事件统计数据和参数属性,为接下来的事件分析做准备。
那么,如何基于事件Label和参数做事件分析呢?
3、如何做事件分析
3.1 传统友商的竞品分析
百度统计、TalkingData等厂商,是事件级的事件分析,他们将分析主体聚焦于事件主体,基于不同的事件主体,通过相应的事件指标进行事件分析。
例如,页面访问事件的访问量、独立访客数、访问时长;点击事件的点击量;这时数据可能已经满足了部分的需求,如果想进一步,还可以继续通过事件主体的Label和参数进行细分分析;
例如,我们可以将注册按钮统一命名为同一个事件ID,在不同页面中的事件ID,会汇总统一在该事件ID下,而不同页面的注册按钮点击量,可以通过设定不同的事件Label,来统计出在不同页面下的注册按钮点击量。
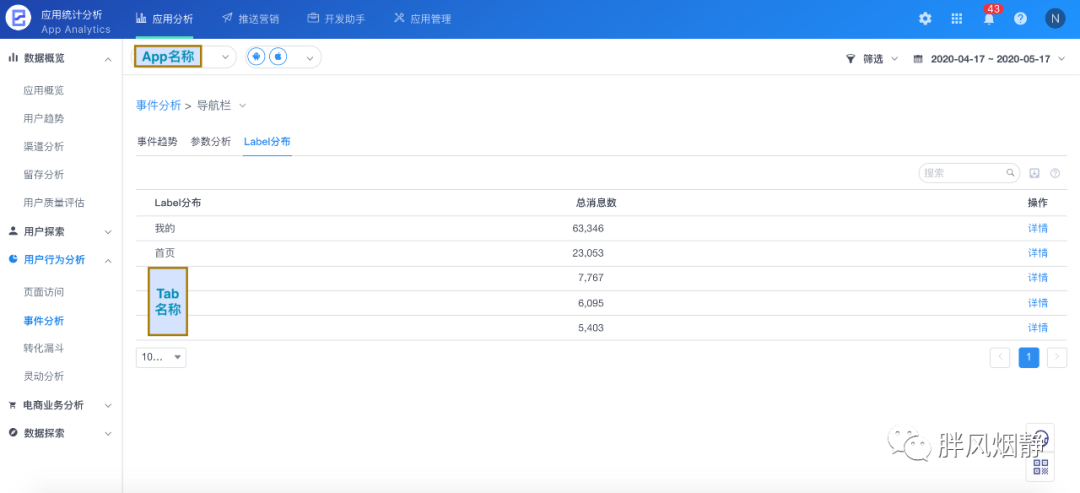
图2:导航栏点击事件的Label标签
而事件参数是在统计一些特定的行为数据时,通过事件参数的方法,以key-value的方式,记录该事件的相关详细信息,如商品名称、分类、价格和购买数量。
根据上报的事件参数,我们可以在该事件之下,进行事件在不同参数取值下的数据分析对比。发掘在单纯的点击事件中发现不到的信息。
最后,百度统计与TalkingData支持针对不同渠道、版本和用户群的维度分析。
从这两家竞品的功能上可以看到,对于事件分析,我们主要是关注:
用户做了什么行为?
在做该行为时,有什么该行为的特征留存?
行为特征可以是行为发生的地点(如在活动页点击的注册按钮还是注册页点击的)、访问时长、添加购物车时选择的商品型号、颜色、数量和价格等等,可见这就是事件的Label和参数。
不同的用户、不同的事件参数情况下,数据的表现。
例如,不同客户等级的用户使用行为是否有差异?同样的用户,对不同的商品的加入购物车的数据是否不同?
基于上述需求,应当如何做?
3.2 事件分析模型
事件分析的主体是事件,要进行数据分析,就需要构建数据指标。有了数据指标后,还需要有不同的维度,用来做分析对比。由此可见,我们要进行事件分析需要两个武器,事件指标与分析维度。
1)事件指标
要衡量事件,可以有很多指标,根据事件主体的不同,也会划分为不同的指标。
对于页面访问事件,我们可以通过访问量、用户量、访问时长等作为事件指标;而针对点击事件,则可以用点击量、独立用户点击量、人均点击量来作为事件指标。
如果事件有属性,则还可以根据事件属性来构建指标,例如数值型指标,立即购买时购买商品的价格,我们可以构建立即购买的金额最大值/均值/最小值指标,用来分析用户在购买商品的时候,一般都是多少钱的商品。
2)分析维度
事件分析维度,可以从使用者的角度分析,即用户维度;也可以通过对事件本身属性的分析来做,即事件属性维度。
用户维度,即用户的属性,包括用户的性别、年龄、客户等级、地域等用户标签,具体有哪些取决于平台自身构建的用户标签有哪些;用户分群也可以作为用户维度参与分析。
事件属性维度,即事件本身的维度,例如立即购买事件发生时,用户购买的商品ID、商品类别是什么?又或者用户搜索信息时,搜索的关键字是什么?
3)筛选功能
事件分析,是指基于事件的统计指标、属性分组、条件筛选等对事件进行查询分析。
前面已经说了统计指标与属性分组,最后,事件分析过程中我们还会遇到只针对特定事件作分析的情况,这时候就需要进行筛选过滤。而筛选过滤的条件,也是上面提到的分析维度,由于维度有粗有细,因此,当我们想查看某大类商品下的商品名称时,就可以使用大类筛选并商品名称维度查看的方式,来过滤掉无关的事件信息。

图3:GrowthIO事件分析的多事件多维度分析
Part 2
漏斗分析简析
1、漏斗分析介绍
事件是用户在App中行为分析的基础,用户对App的每一个行为,都是一个事件。
由于事件是用户行为分析的基础,因此我们要做漏斗分析,也得是在事件的基础上进行。先分析一下漏斗分析这个功能:
1.1 用户需求
要分析特定路径的转化率,并进行各维度对比。
1.2 实现方式
要实现帮助用户进行漏斗分析的需求,需要实现以下步骤:
Step 1:确定转化路径
转化路径由事件节点组成,事件节点需要包括用户所进行的行为事件,包括页面访问和点击事件。当然,可以在通过事件的属性,对事件节点做筛选,选定特定的事件(此时,虽然也可以通过Label做筛选的,但是既有Label又有参数就不方便操作,因此很多厂商将Label合并入了参数)。
Step 2:定义转化事件
有了特定路径,还需要确定什么情况算是成功转化。
成功转化需要设定转化时间以及转化关联。
转化时间
是指转化路径中的事件在多久时间内发生的才认为是成功,一般会认为是启动一次App内,1天内,或者几天内。
转化关联
是指在转化事件中,前后事件是否有特定的属性关联,例如查看商品详情页与加入购物车这两个行为,他们的商品ID是否是一致的。
Step 3:分维度对比查看转化率
维度包括:各节点事件属性、用户属性、用户分群;
*Step 4: 设定参与转化分析的用户群
例如,可以只考虑注册用户,或者只考虑某个分群的用户;该功能实际可以通过全部用户计算,分用户维度分析来实现。
Step 5: 考察转化指标
相关转化率指标包括:总转化率、各步骤转化率、各步骤用户数。
其中,
转化关联的关联属性通过如下示例说明:
如果我们考察商品购买的情况,我们会构建漏斗为浏览商品详情页 -> 提交订单 -> 支付订单,这时候如果我们不设置这三个事件之间的属性关联,则可能会出现用户浏览商品详情页和提交订单的两个事件中不是同一个商品,例如之前浏览了IPhone8,但是提交订单的时候提交的是小米10。或者,当我们只想查看小米10的转化情况时,如果我们在商品浏览页设置了商品名称是小米10,但是没有设置关联属性的话,可能出现的就是虽然浏览商品页是小米10,但是从提交订单,到支付订单,就都不是小米10了。
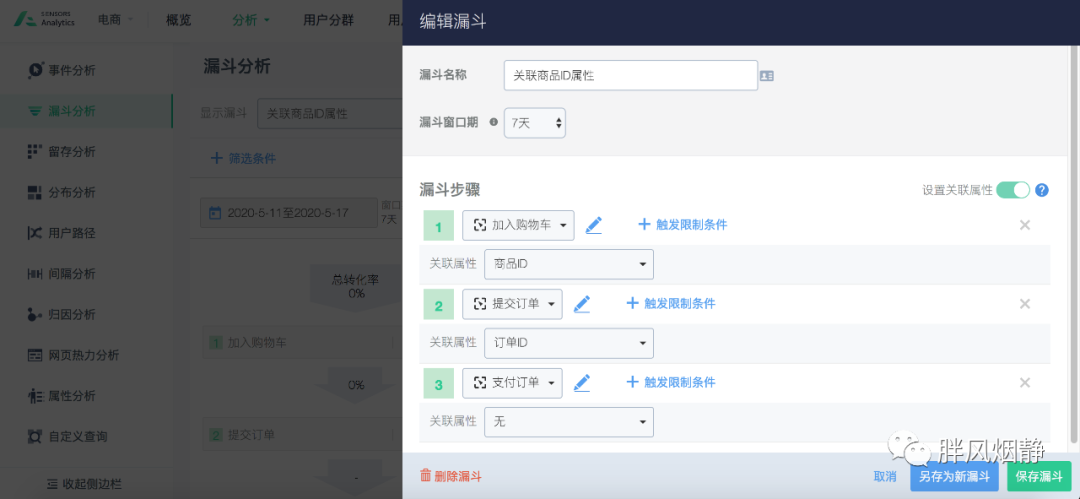
图4:关联属性示例
虽然看似说起来简单,但是要想实现漏斗分析这个功能,就不得不在海量的用户行为事件中对特定事件的发生做查找计算,并且针对用户设定的不同节点、属性、规则,做实时计算,得到最终的数据,这并不是一个简单的过程。
2、漏斗分析的计算规则
2.1 基本计算规则
假设一个漏斗中包含了 A、B、C、D、E 五个步骤,选择的时间范围是 2020 年 1 月 1 日到 2020 年 1 月 3 日,窗口期是 1 天,那么,如果用户在2020年1月1日到2020年1月3日触发了步骤 A,并且在步骤 A 发生的 1 天内,依顺序依次触发了 B、C、D、E,则视作该用户完成了一次成功的漏斗转化。
在这个过程中,如果穿插了一些其它的步骤或者行为,例如在满足时间限制的情况下,用户的行为顺序是 A > X > B > X > C > D > X > E,X 代表任意一个事件,则该用户依然视作完成了一次成功的漏斗转化。
如果该用户在这个时间限制范围内,依次触发了 A > B > C > E,则该用户没有完成该漏斗的转化,并且会被记作步骤 C 的流失用户。
考虑一个更复杂的情况,如果一个用户在所选时段内有多个事件都符合某个转化步骤的定义,那么会优先选择更靠近最终转化目标的事件作为转化事件,并在第一次达到最终转化目标时停止转化的计算。假设一个漏斗的步骤定义是:访问首页、选择支付方式、支付成功,那么不同用户的行为序列及实际转化步骤(标红部分)见如下例子:
例1:
访问首页 > 选择支付方式(支付宝) > 选择支付方式(微信) > 支付成功。
例2:
访问首页 > 选择支付方式(支付宝) > 访问首页 > 选择支付方式(微信) > 支付成功。
例3:
访问首页 > 选择支付方式(支付宝) > 访问首页 > 选择支付方式(微信) > 支付成功 > 选择支付方式(微信) > 支付成功。
2.2 筛选与分组查看
1)筛选
漏斗分析提供了筛选功能。漏斗分析的筛选,都是对完成转化/确认流失的用户,再进行二次挑选。
漏斗分析的筛选,包括2种不同的筛选类型:
用户属性的筛选:
这个比较好理解,是在完成转化/确认流失的用户的基础上,根据这个用户的属性,再来进行更进一步的筛选。例如,我们添加的筛选条件是“性别”为“男”,则只有用户属性中“性别”为“男”的用户,才满足这个筛选条件,并且出现在筛选后的漏斗分析结果中;
指定步骤的属性的筛选:
假设,我们选择了一个筛选条件是步骤 2 的属性“支付方式”为“支付宝”,这个筛选表示,在完成转化/确认流失的用户中,转化到步骤 2 时的“支付方式”的值为“支付宝”的那些用户;如果有多次可能的转化,请参考基本计算规则中的说明。
2)分组查看
漏斗分析提供了分组功能。漏斗分析的分组,都是对完成转化/确认流失的用户的集合上进行分组。
漏斗分析的分组,包括2种不同的分组类型:
用户属性的分组:
同样的,用户属性分组页是在完成转化/确认流失的用户的集合,根据这个用户的属性,在来进行更进一步的分组。例如,我们添加的分组条件是“性别”,那么,就会分别对漏斗分析的结果按照“男”、“女”来进行分组;
指定步骤的属性的分组:
假设,我们选择了一个分组属性是步骤 2 的属性“支付方式”,这个筛选表示,在完成转化/确认流失的用户中,按照转化到步骤 2 时的“支付方式”的值来进行分组;如果有多次可能的转化,请参考基本计算规则中的说明;如果用户没有转化到步骤 2,则分到未知组。
2.3 漏斗内筛选和漏斗外筛选的区别
漏斗内设置的筛选条件是根据设置的条件得到漏斗,漏斗外设置的筛选条件是根据得到的漏斗筛选出满足筛选条件的漏斗。一般业务上的使用场景是在漏斗内设置筛选条件,建议直接在漏斗内设置条件得到满足条件的漏斗。
例如:
漏斗选取的漏斗步骤为 A > B > C > D ,某用户甲的序列是 F > A2 > A1 > A1 > B > C > A1 > B,事件 A 包含了事件发生所在地的属性,其中 A1 的所在地为北京, A2 的所在地为上海。
如果在漏斗内添加筛选条件所在地为北京,那么系统筛选到的序列为 A2 > B > C,筛选的原则是沿着该用户的行为序列顺序查找,直到找到属性为北京的 A 事件;
如果在漏斗外添加筛选条件所在地为北京因为漏斗外筛选是在用户漏斗成功转换后的二次筛选,不加任何筛选条件时,该用户正常的漏斗转化为 A1 > B > C,其中 A1 为第二个 A1 ,因此在漏斗外添加筛选条件时该用户筛选不出来。

END
