




Hadoop作为大数据生态的基石,关于其技术栈你掌握了吗?
常用组件有Hadoopo 、Yarn、Zookeeper、Hive、HBase、Spark、Kafka、ES等。下图简单介绍它们之间的调用关系。
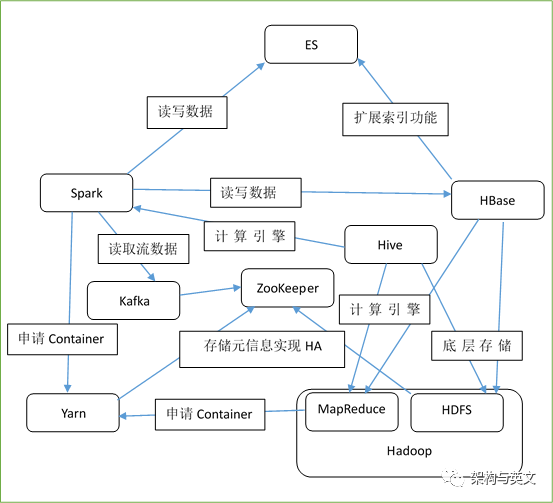
1、Hadoop由HDFS和MapReduce组成,HDFS负责存储,MapReduce负责计算。随着大数据发展,MapReduce管理进程的弊端也逐渐显露,诞生了以Yarn为代表的资源管理工具。
2、Yarn包括ResourceManager和NodeManager。作为新一代计算管理工具,应用需按照Yarn定义的模板实现ApplicationMaster并实现与RM和NM通信的协议,然后便可向Yarn申请运行需要的container进行运行。典型代表案例有MapReduce和Spark。由于MapReduce以磁盘为中间计算数据的宿主,无法满足某些需要快速计算的场景,因此诞生了Spark。
3、Spark以RDD组成的DAG为计算策略,并以内存计算著称;由于少了磁盘输入输出的过程,其运算性能明显上升。其和MapReduce一样可以运行于Yarn之上,有yarn-cluster和yarn-client两种模式,两则最大区别是AM于Driver是否运行在同一个节点里面。
4、Hive是常用的数据仓库工具,提供SQL工具处理海量数据,其存储依赖HDFS,以MapReduce和Spark为计算引擎。
5、HBase是一个能够支持海量数据实时读写的数据库,其表的行和列都可以达到亿级别,并且能够支持行和列的动态划分。
6、ES是常用的全文检索数据库。HBase+ES架构是常用功能,HBase利用ES来扩展索引的功能,其原理是把非索引列与主键ID存入ES,查找数据时先在ES查找,然后再通过ID去HBase查找。
7、ZooKeeper主要提供分布式应用协调服务,HDFS和Yarn利用Zookeeper实现HA功能,Kafak和Solr等利用Zookeeper存放元信息。
8、Kafak是常用的消息中间件,Producer向topic写入数据,Consumer读取topic数据,依赖于Zookeeper存储元数据。Kafka已成为流处理程序必备组件,Kafka+SparkStreaming+HBase/ES是常用组合。
你get了吗
注:以上仅代表个人观点,如有异议欢迎指正。
